SQL Server统计信息偏差影响表联结方式案例浅析
我们知道数据库中的统计信息的准确性是非常重要的。它会影响执行计划。一直想写一篇关于统计信息影响执行计划的相关博客,但是都卡在如何构造一个合适的例子上,所以一直拖着没有写。巧合,最近在生产环境中遇到这么一个案例,下面对案例中的相关信息做了脱敏处理,有些中间步骤也省略了,只关注核心部分SQL。如下所示,同事反馈一个SQL语句执行很慢。
UPDATE b
SET b.[Status] = '已扫描,未签收' ,
b.[Time] = pr.CreatedDate
FROM #Batch b
JOIN WDPM.PdaRecords pr WITH ( NOLOCK ) ON b.Batch_No = pr.OrderNo
AND pr.FunctionName = '[WDPM].[usp_SaveOutOrder]'
WHERE b.[Status] = '已打单,未扫描'
AND pr.CreatedDate > b.[Time];
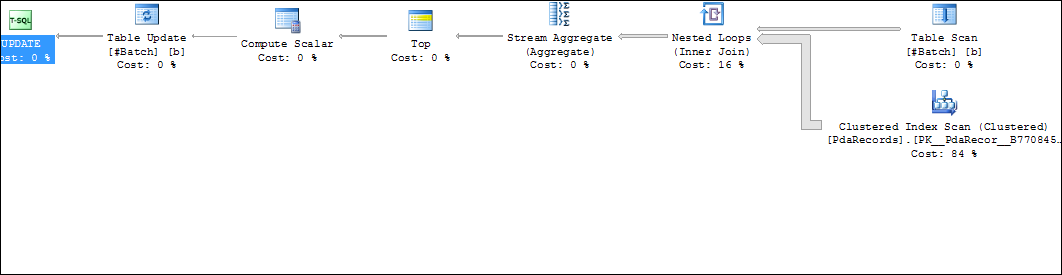
如下截图所示,这个SQL语句基本上耗时271秒。一个临时表与一个表做嵌套循环连接(Nested Loops)。 因为表WDPM.PdaRecords只有一个聚集索引,所以执行计划中,这个表走聚集索引扫描。

注意:这里表WDPM.PdaRecords本身缺少合适的索引,只有一个聚集索引。后面展开讲述这个问题.这里先围绕统计信息的准确性对执行计划的影响来展开讲述。
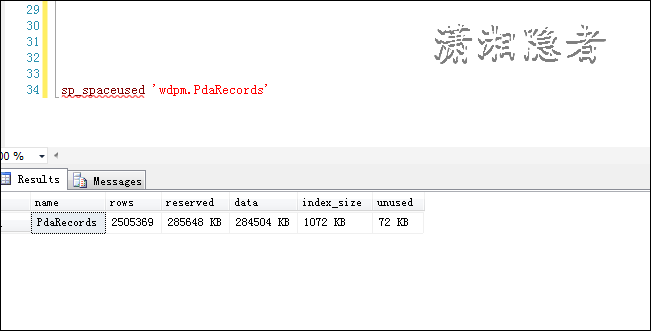
物理表WDPM.PdaRecords的数据量为2505369(当然这个是一直在变化的。这个数值仅仅是实验前的检测记录,一直有会话对其进行DML操作,所以数据会变化,所以这里没有列出统计信息截图)。
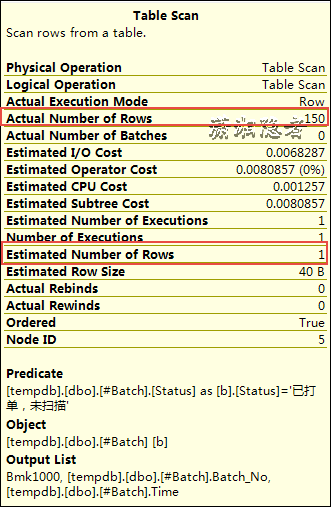
我们看到Table Scan部分,预估行数(Estimated Number of Rows)为1, 实际行数为150。 这个偏差已经比较大了。
对于物理表WDPM.PdaRecords而言,基数估计的预估行数(Estimated Number of Rows)为921771, 但是由于嵌套循环连接,所以累加起来的实际行数(Actual Number of Rows)为: 921771*150 =138265650 。
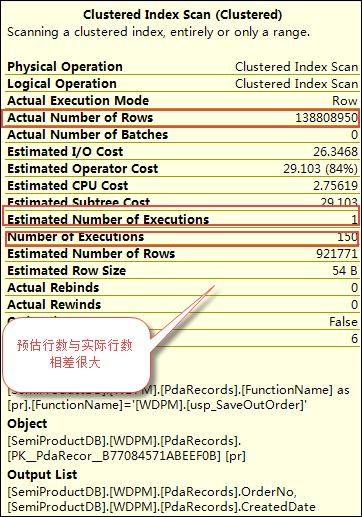
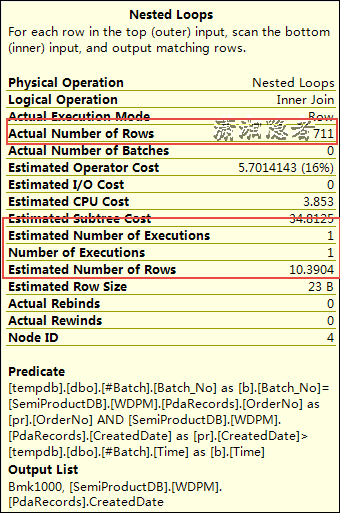
我们知道嵌套循环(Nested Loops)算法的时间复杂度为N*M, N的预估值从1变成了150 ,这里面的偏差就大了(因为每次聚集索引扫描的开销也很大)。所以导致优化器在表的物理连接方式上选择了嵌套循环(Nested Loops), 因为预估的代价是很小的。但是实际因为统计信息的误差,导致这个代价放大了150倍。那么如果我们更新临时表的统计信息呢?然后执行这个SQL,会有什么变化呢?
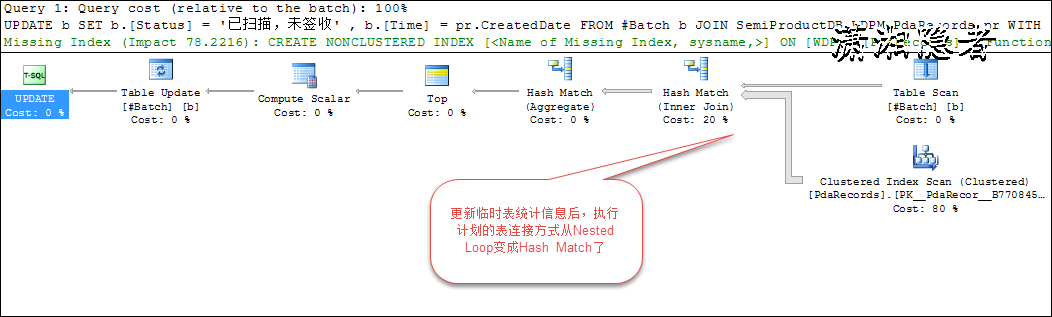
如下所示,我们在执行SQL语句前,更新一下临时表的统计信息。发现优化器在获取了准确的统计信息后,在表的物理连接上选择了Hash Join方式。而且SQL语句耗时变成了1秒多。为什么呢? 因为优化器发现选择Nested Loops的代价远远高于 Hash Join。所以它在获取了准确的信息后,作出了最优选择。之前之所以生成了一个错误的执行计划,就是因为它得到的“信息”不准确,导致它作出了错误的抉择。这个就好比你获取了错误的信息,作出了错误的选择,购买了一只错误的股票,而巴菲特由于掌握了准确的行业信息,作出了正确的选择。 购买了几只购票都大涨了。
UPDATE STATISTICS #Batch WITH FULLSCAN;
UPDATE b
SET b.[Status] = '已扫描,未签收' ,
b.[Time] = pr.CreatedDate
FROM #Batch b
JOIN WDPM.PdaRecords pr WITH ( NOLOCK ) ON b.Batch_No = pr.OrderNo
AND pr.FunctionName = '[WDPM].[usp_SaveOutOrder]'
WHERE b.[Status] = '已打单,未扫描'
AND pr.CreatedDate > b.[Time];

当然,了解到这里,还远远没有结束。我们发现表WDPM.PdaRecords 只有一个聚集索引,而且聚集索引位于Iden自增字段上,从另外一个角度来看,这个表其实是缺少合适的索引的。那么我们可以创建一个索引。
CREATE INDEX IX_PdaRecords_N1 ON wdpm.PdaRecords(OrderNo,FunctionName)
创建索引后,即使不更新临时表#Batch的统计信息,我们发现执行计划也会走嵌套循环(Nested Loops),而不会走Hash Join了。这个又是什么原因呢?
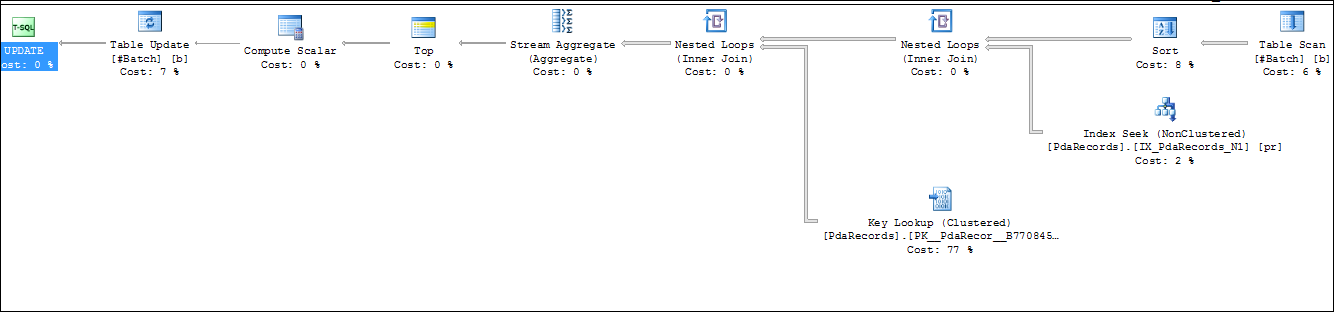
此处截图,是第二次执行SQL,临时表的数据变化了(生成临时表的数据的SQL有好几个,每次执行获取的数据都会有部分变化)
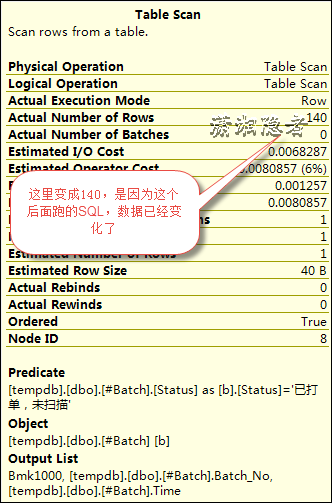
因为有了合适的索引,趋近准确的统计信息,以及谓词下推(predicate push down),基数(Cardinality)的预估行数(Esitmted Row Size)为35.0545 与实际行数(Actual Number of Rows)为666, 这样即使循环次数为140. 总的访问记录数为140*666=93240 , 这个是远远小于之前错误执行计划的138265650 。所以即使临时表的#Batch的统计信息有误,但是优化器还是生成了一个不错的执行计划。这样SQL的执行时间也就缩短到了1秒内.

这个案例仅仅是为了展示:统计信息的准确与否,会导致优化器生成的执行计划选择不同的表连接方式, 例如从嵌套循环(Nested Loops)变成Hash Join。 仅仅是为了说明统计信息准确的重要性。
SQL Server统计信息偏差影响表联结方式案例浅析的更多相关文章
- SQL Server信息偏差影响表联结方式统计
SQL Server统计信息偏差影响表联结方式案例浅析 我们知道数据库中的统计信息的准确性是非常重要的.它会影响执行计划.一直想写一篇关于统计信息影响执行计划的相关博客,但是都卡在如何构造一个合适 ...
- SQL Server统计信息:问题和解决方式
在网上看到一篇介绍使用统计信息出现的问题已经解决方式,感觉写的很全面. 在自己看的过程中顺便做了翻译. 因为本人英文水平有限,可能中间有一些错误. 假设有哪里有问题欢迎大家批评指正.建议英文好的直接看 ...
- 全废话SQL Server统计信息(2)——统计信息基础
接上文:http://blog.csdn.net/dba_huangzj/article/details/52835958 我想在大地上画满窗子,让所有习惯黑暗的眼睛都习惯光明--顾城<我是一个 ...
- 全废话SQL Server统计信息(1)——统计信息简介
当心空无一物,它便无边无涯.树在.山在.大地在.岁月在.我在.你还要怎样更好的世界?--张晓风<我在> 为什么要写这个内容? 随着工作经历的积累,越来越感觉到,大量的关系型数据库的性能问题 ...
- SQL SERVER 统计信息概述(Statistics)
前言 查询优化器使用统计信息来创建可提高查询性能的查询计划,对于大多数查询,查询优化器已经为高质量查询计划生成必要的统计信息,但是在少数情况下,您需要创建附加的统计信息或者修改查询设计以得到最佳结果. ...
- SQL Server 统计信息更新时采样百分比对数据预估准确性的影响
为什么要写统计信息 最近看到园子里有人写统计信息,楼主也来凑热闹. 话说经常做数据库的,尤其是做开发的或者优化的,统计信息造成的性能问题应该说是司空见惯. 当然解决办法也并非一成不变,“一招鲜吃遍天” ...
- SQL Server 统计信息对查询的影响
优化器根据开消确定选择哪个执行计划,开消又与行数统计信息有关,默认情况下统计信息是在优化的过程中自动生成的. 一旦列被标记为需要统计信息,查询优化器就会查找该列以有的统计信息,如果以有一个统计信息,下 ...
- SQL Server 统计信息(Statistics)-概念,原理,应用,维护
前言:统计信息作为sql server优化器生成执行计划的重要参考,需要数据库开发人员,数据库管理员对其有一定的理解,从而合理高效的应用,管理. 第一部分 概念 统计信息(statistics):描述 ...
- SQL Server 统计信息
SELECT * FROM SYS.stats _WA_Sys_00000009_00000062:统计对象的名称.不同的机器名称不同,自动创建的统计信息都以_WA_Sys开头,00000009表示的 ...
随机推荐
- 【转】搭建自己的 sentry 服务
1. 安装 docker 首先要确认你的 Ubuntu 版本是否符合安装 Docker 的前提条件.如果没有问题,你可以通过下边的方式来安装 Docker : 使用具有 sudo 权限的用户来登录你的 ...
- SSM-SpringMVC-19:SpringMVC中请求和响应的乱码解决
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 配置一道拦截器即可解决乱码 配置方式如下: 在web.xml中: <!--过滤器处理乱码--> ...
- SSM-Spring-08:Spring的静态代理初窥案例
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 静态代理 java的设计模式的代理模式,就是静态代理 写在前面的话,静态代理的优点和缺点 优点:可以在不改变一 ...
- 13.app后端为什么要用到消息队列
很多没有实际项目经验的小伙伴,对消息队列系统非常陌生,看着很多架构的介绍中,都提到消息队列.但是,不知道为什么要用消息队列?什么是消息队列?常见的消息队列产品有哪些? 通过阅读本文,帮你解开以上的疑惑 ...
- Android 框架炼成 教你如何写组件间通信框架EventBus
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/41096639 ,本文出自:[张鸿洋的博客] 1.概述 关于Eventbus的介绍 ...
- GitHub 系列之「怎样使用 GitHub?」
1.写在前边的话,为什么要写CitHub? 跟朋友在交流的时候听到求职的时候发现有些公司要附Github帐号,一个优秀的 GitHub 账号当然能让你增色不少.自己之前听说过,但没有花时间研究,最后花 ...
- SimpleDateFormat安全的时间格式化
SimpleDateFormat安全的时间格式化 想必大家对SimpleDateFormat并不陌生.SimpleDateFormat 是 Java 中一个非常常用的类,该类用来对日期字符串进行解析和 ...
- Vert.x 线程模型揭秘
来源:鸟窝, colobu.com/2016/03/31/vertx-thread-model/ 如有好文章投稿,请点击 → 这里了解详情 Vert.x是一个在JVM开发reactive应用的框架,可 ...
- 如果裸写一个goroutine pool
引言 在上文中,我说到golang的原生http server处理client的connection的时候,每个connection起一个goroutine,这是一个相当粗暴的方法.为了感受更深一点, ...
- InfluxDB介绍
InfluxDB介绍 InfluxDB用Go语言编写的一个开源分布式时序.事件和指标数据库,和传统是数据库相比有不少不同的地方. 类似的数据库有Elasticsearch.Graphite等. 特点 ...