Hadoop(一)Hadoop的简介与源码编译
一 Hadoop简介
1.1Hadoop产生的背景
1. HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问,如何解决数十亿网页的存储和索引问题。
2. 2003年开始谷歌陆续发表的三篇论文为该问题提供了可行的解决方案。
- 分布式文件系统(GFS),可用于处理海量网页的存储
- 分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
- BigTable 数据库:OLTP 联机事务处理 Online Transaction Processing 增删改,OLAP 联机分析处理 Online Analysis Processing 查询,真正的作用:提供了一种可以在超大数据集中进行实时CRUD操作的功能
3.Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
1.2 Hadoop的优势
1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
1.3 Hadoop组成
1)Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。
2)Hadoop MapReduce:一个分布式的离线并行计算框架。
3)Hadoop YARN:作业调度与集群资源管理的框架。
4)Hadoop Common:支持其他模块的工具模块。
1.4.1 YARN架构概述
1)ResourceManager(rm): 处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
1.4.2 MapReduce架构概述 MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
1.4 大数据技术生态体系图
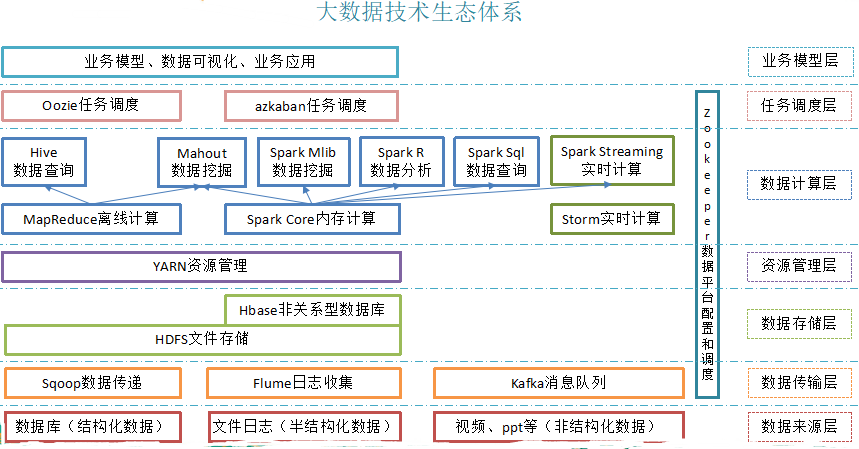
Hadoop生态圈重点组件:
HDFS:Hadoop的分布式文件存储系统。
MapReduce:Hadoop的分布式程序运算框架,也可以叫做一种编程模型。
Hive:基于Hadoop的类SQL数据仓库工具
Hbase:基于Hadoop的列式分布式NoSQL数据库
ZooKeeper:分布式协调服务组件
Mahout:基于MapReduce/Flink/Spark等分布式运算框架的机器学习算法库
Oozie/Azkaban:工作流调度引擎
Sqoop:数据迁入迁出工具
Flume:日志采集工具
获取数据的三种方式
1、自己公司收集的数据--日志 或者 数据库中的数据
2、有一些数据可以通过爬虫从网络中进行爬取
3、从第三方机构购买
二 Hadoop编译源码
2.1 前期准备工作
1)CentOS联网
配置CentOS能连接外网。最好是用新克隆的虚拟机 注意:采用root角色编译,减少文件夹权限出现问题,yum源最好用org官方的,虚拟机内存设置大一点(我这里设置的2G)。
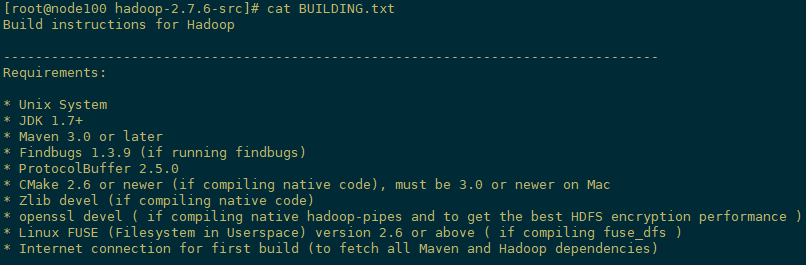
2)编译环境说明
打开下载的hadoop2.7.6源码并解压,打开解压目录下的BUILDING.txt,编译过程和需要的软件其实就是根据这个文档里的描述来的。
[root@node100 software]# tar -zxvf hadoop-2.7.6-src.tar.gz -C /opt/
[root@node100 hadoop-2.7.6-src]# cat BUILDING.txt
3)jar包准备 (hadoop源码、JDK7 、 maven、 ant 、protobuf)
(1)hadoop-2.7.6-src.tar.gz
(2)jdk-7u80-linux-x64.tar.gz
(3)apache-ant-1.9.9-bin.tar.gz
(4)apache-maven-3.1.1-bin.tar.gz
(5)protobuf-2.5.0.tar.gz
2.2 jar包安装
0)注意:所有操作必须在root用户下完成
1)安装jdk,maven,ant,配置环境变量,验证
[root@node100 software]# tar -zxf jdk-7u80-linux-x64.tar.gz -C /opt/module/
[root@node100 software]# tar -zxvf apache-maven-3.1.1-bin.tar.gz -C /opt/module/
[root@node100 software]# tar -zxvf apache-ant-1.9.9-bin.tar.gz -C /opt/module/
[root@node100 software]# vi /etc/profile
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.7.0_80
export PATH=$PATH:$JAVA_HOME/bin
#MAVEN_HOM
export MAVEN_HOME=/opt/module/apache-maven-3.1.1
export PATH=$PATH:$MAVEN_HOME/bin
#ANT_HOME
export ANT_HOME=/opt/module/apache-ant-1.9.11
export PATH=$PATH:$ANT_HOME/bin
[root@node100 software]#source /etc/profile
java -version
mvn -version
ant -version
修改maven的配置文件,添加maven的下载源
[root@node100 software]# cd /opt/module/apache-maven-3.1.1/conf/
[root@node100 conf]# vi settings.xml
在mirrors中添加alimaven的下载源
<mirrors>
<!-- mirror
| Specifies a repository mirror site to use instead of a given repository. The repository that
| this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used
| for inheritance and direct lookup purposes, and must be unique across the set of mirrors.
| <mirror>
<id>alimaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</mirror>
<mirror>
<id>mirrorId</id>
<mirrorOf>repositoryId</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://my.repository.com/repo/path</url>
</mirror>
-->
</mirrors>
2)安装protobuf,配置环境变量,验证
[root@node100 software]# tar -zxvf protobuf-2.5.0.tar.gz -C /opt/module/
[root@node100 software]# cd /opt/module/protobuf-2.5.0/
[root@node100 protobuf-2.5.0]#./configure
[root@node100 protobuf-2.5.0]# make & make install
[root@node100 protobuf-2.5.0]# vi /etc/profile
#LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/opt/module/protobuf-2.5.0
export PATH=$PATH:$LD_LIBRARY_PATH
[root@node100 software]#source /etc/profile
验证命令:protoc --version
3)安装 各种库 命令如下:
[root@node100 ~]# yum -y install svn ncurses-devel gcc*
[root@node100 ~]# yum -y install lzo-devel zlib-devel autoconf automake libtool cmake openssl-devel
到此,编译工具安装基本完成。
2.3 编译源码
1)解压源码到/opt/目录
[root@node100 software]# tar -zxvf hadoop-2.7.6-src.tar.gz -C /opt/
2)进入到hadoop源码主目录,通过maven执行编译命令
[root@node100 ~]# cd /opt/hadoop-2.7.6-src/
[root@node100 hadoop-2.7.6-src]# mvn package -Pdist,native -DskipTests -Dtar
等待时间30分钟左右,最终成功是全部SUCCESS,首次编译时间可能会有两三个小时
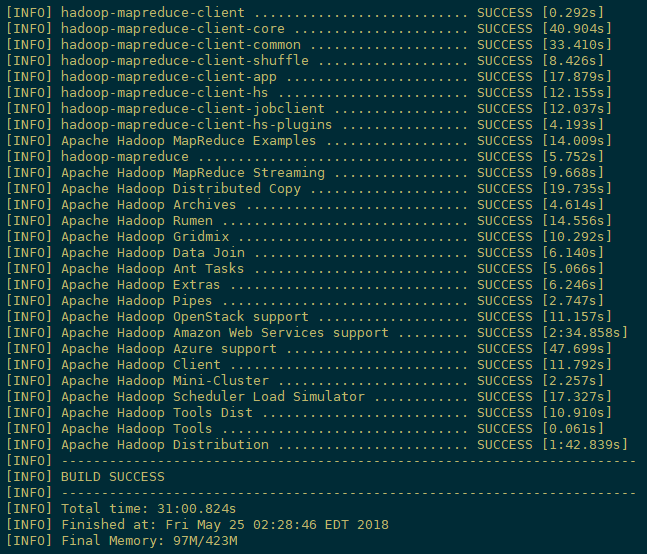
3)成功的64位hadoop包在/opt/hadoop-2.7.6-src/hadoop-dist/target下。
[root@node100 ~]# cd /opt/hadoop-2.7.6-src/hadoop-dist/target/
2.4 常见的问题及解决方案
1)MAVEN install时候JVM内存溢出
处理方式:在环境配置文件和maven的执行文件均可调整MAVEN_OPT的heap大小。(详情查阅MAVEN 编译 JVM调优问题,如:http://outofmemory.cn/code-snippet/12652/maven-outofmemoryerror-method)
2)编译期间maven报错。可能网络阻塞问题导致依赖库下载不完整导致,多次执行命令(一次通过比较难)
[root@hadoop101 hadoop-2.7.6-src]# mvn clean package -Pdist,native -DskipTests -Dtar
3)报ant、protobuf等错误,插件下载未完整或者插件版本问题,最开始链接有较多特殊情况,同时推荐
2.7.0版本的问题汇总帖子 http://www.tuicool.com/articles/IBn63qf
Hadoop(一)Hadoop的简介与源码编译的更多相关文章
- Hadoop源码编译过程
一. 为什么要编译Hadoop源码 Hadoop是使用Java语言开发的,但是有一些需求和操作并不适合使用java,所以就引入了本地库(Native Libraries)的概念,通 ...
- Hadoop,HBase,Zookeeper源码编译并导入eclipse
基本理念:尽可能的参考官方英文文档 Hadoop: http://wiki.apache.org/hadoop/FrontPage HBase: http://hbase.apache.org/b ...
- 基于cdh5.10.x hadoop版本的apache源码编译安装spark
参考文档:http://spark.apache.org/docs/1.6.0/building-spark.html spark安装需要选择源码编译方式进行安装部署,cdh5.10.0提供默认的二进 ...
- hadoop 源码编译
hadoop 源码编译 1.准备jar 1) hadoop-2.7.2-src.tar.gz 2) jdk-8u144-linux-x64.tar.gz 3) apach-ant-1.9.9-bin. ...
- Hadoop的源码编译
目录 正文 1.准备阶段 使用root登录Centos,并且要求能够正常连接网络.配置清单如下: (1)hadoop-2.7.2-src.tar.gz (2)jdk-8u144-linux-x64.t ...
- Linux内核分析(一)---linux体系简介|内核源码简介|内核配置编译安装
原文:Linux内核分析(一)---linux体系简介|内核源码简介|内核配置编译安装 Linux内核分析(一) 从本篇博文开始我将对linux内核进行学习和分析,整个过程必将十分艰辛,但我会坚持到底 ...
- ThreadLocal 简介 案例 源码分析 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- Spark源码编译
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3822995.html spark源码编译步骤如下: cd /home/hdpusr/workspace ...
- hadoop-1.2.0源码编译
以下为在CentOS-6.4下hadoop-1.2.0源码编译步骤. 1. 安装并且配置ant 下载ant,将ant目录下的bin文件夹加入到PATH变量中. 2. 安装git,安装autoconf, ...
随机推荐
- python基础----递归函数(二分法、最大深度递归)
递归函数 定义:在函数内部,可以调用其他函数.如果一个函数在内部调用自身本身,这个函数就是递归函数. #例子1 # age()=age()+ n= age(n)=age(n-)+ # age()=ag ...
- Linux基础------文件打包解包---tar命令,文件压缩解压---命令gzip,vim编辑器创建和编辑正文件,磁盘分区/格式化,软/硬链接
作业一:1) 将用户信息数据库文件和组信息数据库文件纵向合并为一个文件/1.txt(覆盖) cat /etc/passwd /etc/group > /1.txt2) 将用户信息数据库文件和用户 ...
- uCOS-II之移植20160823
首先我们看一下uC/OS-II的框架图: 1.配置文件修改 +------------------------------------------ |core: os_core.c | os: os ...
- 010. C++ 传值与传引用
1.参数传递 参数传递:pass by value vs. pass by reference(to const) 推荐:能传引用,尽量传引用(高效,尤其在需要拷贝的对象很大时) class comp ...
- 1.UiDevice API 详细介绍
1.UiDevice按键与keycode使用 返回值 方法名 说明 boolean pressBack() 模拟短按返回back键 boolean pressDPadCenter() 模拟按轨迹球中点 ...
- C/C++ Volatile关键词深度剖析
文章来源:http://hedengcheng.com/?p=725 背景 此微博,引发了朋友们的大量讨论:赞同者有之:批评者有之:当然,更多的朋友,是希望我能更详细的解读C/C++ Volatile ...
- react-native安装react-navigation后出现package-lock.json文件的坑
npm5.0开始安装后回生成一个新的package-lock.json文件.以致初始化好的react-native项目引入的依赖被删除. 目前解决办法.使用facebook的yarn add 第三方组 ...
- Linux下UDP一发一收通信
实现在Linux环境下的UDP通信测试. 注释了while循环,将代码规范化. udpserver.c代码: /******************************************** ...
- DES解码
DES加解密算法是一个挺老的算法了,现在给出它的C语言版. des.h #ifdef __cplusplus extern "C" { #endif ]); char* des(c ...
- 解决VS Code编译调试中文输出乱码
最近尝试用VS Code配置了C和C++的编译调试环境,结果遇到了中文输出乱码问题,查阅网上竟然还没有相关问题,有怀疑是mingw中文支持问题,但最后证明是VS Code编码问题. 解决方案: 文件- ...