Google图片和NASA 网站图片的爬虫
1.根据关键字爬取NASA网站上的图片
首先针对需要爬取的网站进行分析,输入关键字查找需要的内容

通过关键字请求,网页每次会加载20张的缩略图,分析网页源码能够很容易的找到缩略图的url:

然后再点开缩略图,会链接的另一个网页,从这里可以分析出更高分辨率大图的url:
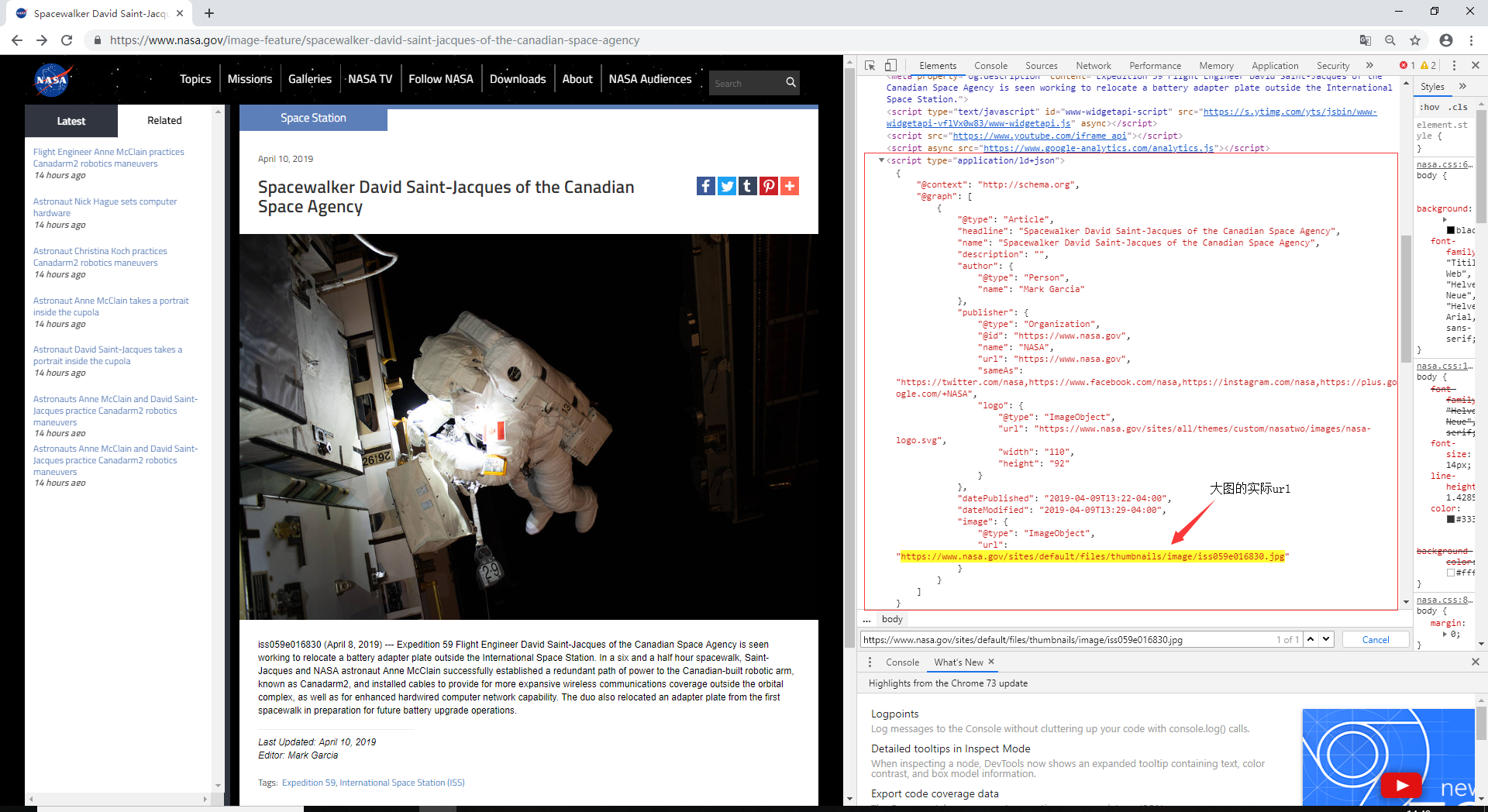
最后根据取得的url地址下载原图就可以了,下面附上源代码
# -*- coding: utf-8 -*-
import urllib
import requests
from bs4 import BeautifulSoup
import re
import json
def getUrl(keyword):
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:53.0) Gecko/20100101 Firefox/53.0'
results = requests.get("https://nasasearch.nasa.gov/search/images",
params={'affiliate': 'nasa', 'query': keyword},
headers={'User-Agent': user_agent})
results.encoding = 'utf-8'
s = requests.session()
s.keep_alive = False
soup = BeautifulSoup(results.text, 'lxml')
# 获取网页中的所有div ,class=url的文本
for link in soup.find_all('div', class_='url'):
# 拼接url
html = requests.get('https://'+link.text)
soup1 = BeautifulSoup(html.text, 'lxml')
# 获取字段
data = soup1.find('script', attrs={"type": "application/ld+json"})
# json字符串转换为字典
jsonobj = json.loads(data.text)
# 从json块中获取图片地址
imageUrl = jsonobj['@graph'][0]['image']['url']
namelist = imageUrl.split('/')
# 获取图片名称
name = namelist[-1].split('.')[0]
downloadImage(imageUrl, name)
def downloadImage(imageUrl, name):
path = 'D:/space/'
print(name)
if imageUrl is not None:
try:
image_file = requests.get(imageUrl, stream=True, timeout=9)
except requests.exceptions.RequestException:
print('网络异常')
# else:
# if image_file.status_code is not requests.codes.ok:
#print('{}'.format(imageUrl) + '链接为空!')
else:
image_file_path = '{}{}.jpg'.format(path, name)
print('正在下载:' + '{}.jpg'.format(name))
with open(image_file_path, 'wb') as f:
f.write(image_file.content)
print('下载完成!')
if __name__ == "__main__":
keyword = input()
getUrl(keyword)
2.爬取谷歌图片
这里主要使用了一个开源代码,爬虫作者github地址:https://github.com/YoongiKim/AutoCrawler
爬虫的效果还是很不错的,具体的使用作者在主页也详细的说明了
Google图片和NASA 网站图片的爬虫的更多相关文章
- C#获取网页的HTML码、下载网站图片、获取IP地址
1.根据URL请求获取页面HTML代码 /// <summary> /// 获取网页的HTML码 /// </summary> /// <param name=" ...
- C#获取网页的HTML码、下载网站图片
1.根据URL请求获取页面HTML代码 /// <summary> /// 获取网页的HTML码 /// </summary> /// <param name=" ...
- Python爬虫下载美女图片(不同网站不同方法)
声明:以下代码,Python版本3.6完美运行 一.思路介绍 不同的图片网站设有不同的反爬虫机制,根据具体网站采取对应的方法 1. 浏览器浏览分析地址变化规律 2. Python测试类获取网页内容,从 ...
- webmagic 二次开发爬虫 爬取网站图片
webmagic的是一个无须配置.便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫. webmagic介绍 编写一个简单的爬虫 webmagic的使用文档:http://w ...
- Python爬虫实战:批量下载网站图片
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: GitPython PS:如有需要Python学习资料的小伙伴可以 ...
- Scrapy爬取美女图片第四集 突破反爬虫(上)
本周又和大家见面了,首先说一下我最近正在做和将要做的一些事情.(我的新书<Python爬虫开发与项目实战>出版了,大家可以看一下样章) 技术方面的事情:本次端午假期没有休息,正在使用fl ...
- 如何:使用PicturBox实现类似淘宝网站图片的局部放大功能
转载至http://xuzhihong1987.blog.163.com/blog/static/267315872011822113131823/ 概要: 本文将讲述如何使用PictureBox控件 ...
- Web 性能优化: 图片优化让网站大小减少 62%
摘要: 压缩各种格式的图片. 原文:Web 性能优化: 图片优化让网站大小减少 62% 作者:前端小智 Fundebug经授权转载,版权归原作者所有. 这是 Web 性能优化的第二篇,上一篇在下面看点 ...
- 批量下载网站图片的Python实用小工具
定位 本文适合于熟悉Python编程且对互联网高清图片饶有兴趣的筒鞋.读完本文后,将学会如何使用Python库批量并发地抓取网页和下载图片资源.只要懂得如何安装Python库以及运行Python程序, ...
随机推荐
- windows+python3.6下安装fasttext+fasttext在win上的使用+gensim(fasttext)
真是坑了好久,faxttext对win并不是很友好,所以遇到了很多坑,记录下来,以供大家少走弯路. 法1:刚开始直接用pip install fasttext,最后一直报下面这个错误 “error:M ...
- 147.Insertion Sort List---链表排序(直接插入)
题目链接 题目大意:对链表进行插入排序. 解法:直接插入排序.代码如下(耗时40ms): public ListNode insertionSortList(ListNode head) { List ...
- UIScrollViewDelegate 方法调用
UIScrollViewDelegate 方法调用 /** 设置缩放的View, 初始化完之后调用此方法告诉scrollView 谁可以缩放操作, 然后进行布局 */ func viewForZoom ...
- 虚拟机NAT网络设置
1. 虚拟机设置 2. 本地网络设置 3. 本地虚拟网卡设置 4. 安装虚拟机,设置网络为NAT方式即可访问外网.
- C# 随笔 【ToList().Foreach()和Foreach()】
1. 最近在做一个Socket通讯的例子,但是如果使用UTF-8编码传输中文的话取和的会不一样.早上做了测试 . string str = "a我..";看代码中间是一个英文,一个 ...
- LightOJ 1369 Answering Queries(找规律)
题目链接:https://vjudge.net/contest/28079#problem/P 题目大意:给你数组A[]以及如下所示的函数f: long long f( int A[], int n ...
- ios app应用在显示屏幕上改中文名
1.点击项目名 2.选Build settings 搜索 product name 3.双击,改为需要在手机上显示的应用名
- php正则判断手机号码的方法
导读: php用正则表达式判断手机号码的写法:从文章中匹配出所有的手机号就可以preg_match_all(),如果要检查用户输入的手机号是否正确可这样来检查:preg_match(). 用正则匹配手 ...
- qt调用仪器驱动库dll实现程控
在<使用qt+visa实现程控>中实现了qt调用visa库的简单Demo本文将尝试使用qt调用仪器驱动库来实现对仪器仪表的程控 开发环境 系统: windows 10 环境: qt 5.8 ...
- 【PAT】1011. A+B和C (15)
1011. A+B和C (15) 给定区间[-231, 231]内的3个整数A.B和C,请判断A+B是否大于C. 输入格式: 输入第1行给出正整数T(<=10),是测试用例的个数.随后给出T组测 ...