wordcount(C语言)
写在前面
上传的作业代码与测试代码放在GitHub上了 https://github.com/IHHHH/gitforwork
本次作业用的是C语言来完成,因为个人能力与时间关系,只完成了基本功能,扩展功能和高级功能很遗憾没有完成。
基本功能
wc.exe -c file.c //返回文件 file.c 的字符数
wc.exe -w file.c //返回文件 file.c 的单词总数
wc.exe -l file.c //返回文件 file.c 的总行数
wc.exe -o outputFile.txt //将结果输出到指定文件outputFile.txt
PSP表格
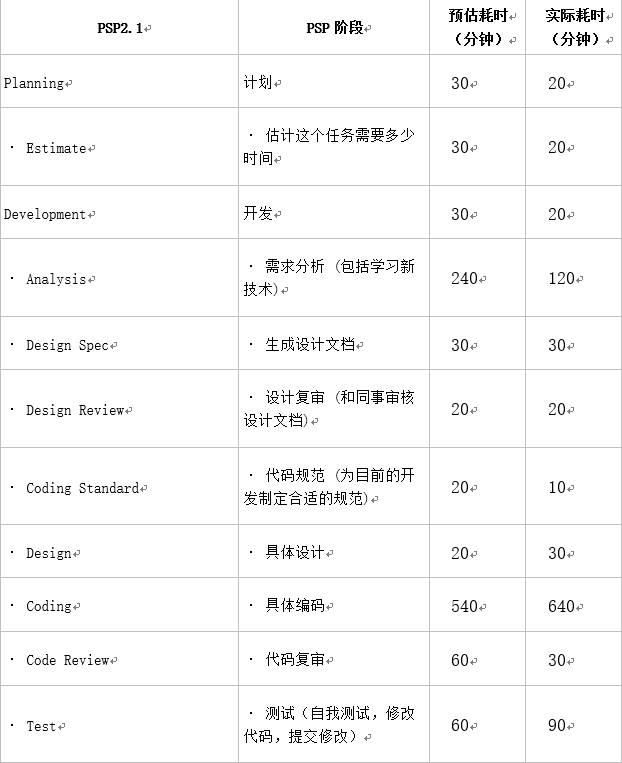
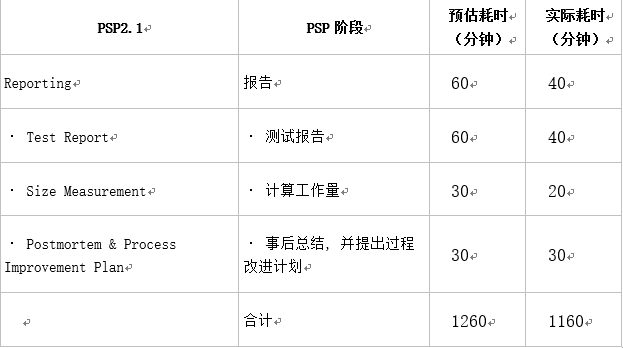
- 关于预估耗时比实际耗时多的原因,并不是因为能力比预估的高,而是一下几点原因:
- 预估耗时是以完成除高级功能外所有功能,包括基本功能和扩展功能,而实际任务中,并没有实现扩展功能,仅仅完成了基本功能
- 完成较少的功能代表着需要较少的时间来学习新的函数和语法
- 报告因为ddl的原因写得比较匆忙,所用时间较少
- 预估耗时是六个该项作业的估计时间,实际上有很多其他事情要处理,并没有留下这么多时间,也就是说其他的事情通过尽量压缩来尽量满足预留时间。
设计思路
- 实现将数据写入指定文件,读取指定文件的数据并输出
- 实现读取指定文件的行数,字符数,单词数并直接输出
- 从用户输入的字符串中提取相应的处理字,文件名并直接输出
- 将提取到的关键字与之前实现的功能进行对接
- 测试程序的一般情况与临界情况
程序分析
char* t; //result
char* wr; //output
char a[50]; //记录输入数据
char b[50]; //记录读取的文件地址
char WC[1000]; //保存打开的文件内容
int col_count(const char* t); //统计字符数
int col_row(const char* t); //统计行数
int col_word(const char* t); //统计单词数
void result(const char* t, const char* a, int num); //产生结果文件
void output(const char* t, const char* w, int count, int row, int word);//产生输出文件
通过两个指针记录可能出现的两个文件地址字符串的首地址,为了简便,b数组中相应数据的位置与a相同,通过指针进行读取。
for (int i = 0; a[i] != NULL; i++)
{
if(a[i] == '-')
if (a[i+1] == 'o')
for (int j = i+1; a[j] != NULL; j++)
{
if (a[j] == ' ')
if (a[j + 1] != ' '&&a[j + 1] != '-') //输出文件入口判断
{
wr = a + j + 1;
break;
}
}
}
通过对输入信息的判断来提取代表文件地址的字符串
for (int i = 1; a[i] != NULL; i++)
{
if (a[i - 1] == ' ')
if (a[i] != ' '&&a[i] != '-') //目标文件名入口判断
{
int j = i;
while (a[i] != ' '&&a[i] != NULL) //目标文件名出口判断
{
b[i] = a[i];
i++;
}
t = b + j;
break;
}
}
默认读取的文件在需要写入的文件前,因此读取的文件判断相对复杂,需要对入口和出口同时进行判断
if(a[i] == '-')
{
if (a[i + 1] == 'c')
{
count = col_count(t);
printf_s("字符数:%d", count);
result(t, "字符数", count);
printf_s("\n");
}
if (a[i + 1] == 'l')
{
row = col_row(t);
printf_s("行数:%d", row);
result(t, "行数", row);
printf_s("\n");
}
if (a[i + 1] == 'w')
{
word = col_word(t);
printf_s("单词数:%d", word);
result(t, "单词数", word);
printf_s("\n");
}
if (a[i + 1] == 'o')
{
output(t, wr, count, row, word);
printf_s("\n");
}
}
通过“-”后面的不同情况应用不同的函数
int col_count(const char* t)
{
char data;
FILE *fp;
errno_t err;
int count = 0;
err = fopen_s(&fp, t, "r");
if (err != 0)
{
printf("can't open file\n");
count = -1;
}
while ((data = getc(fp)) != EOF)
{
WC[count] = data;
count++;
}
fclose(fp);
return count;
}
int col_row(const char* t)
{
char data;
FILE *fp;
errno_t err;
int row = 0;
err = fopen_s(&fp, t, "r");
if (err != 0)
{
printf("can't open file\n");
row = -1;
}
while ((data = getc(fp)) != EOF)
if (data == '\n')
row++;
fclose(fp);
return row;
}
int col_word(const char* t)
{
char data;
FILE *fp;
errno_t err;
int word = 0;
int i = 0;
err = fopen_s(&fp, t, "r");
if (err != 0)
{
printf("can't open file\n");
word = -1;
}
while ((data = getc(fp)) != EOF)
{
WC[i] = data;
i++;
}
if (WC[0] != ' ' && WC[0] != ',' && WC[0] != '\n')
word++;
for (i = 0; WC[i] != NULL; i++)
{
if (WC[i] == ' ' || WC[i] == ',' || WC[i] == '\n')
if (WC[i + 1] != ' ' && WC[i + 1] != ',' && WC[i + 1] != '\n')
word++;
}
fclose(fp);
return word;
}
以上三个函数为需要实现功能函数,均用getc()函数对文件按照一个字符一个字符的方式读取,不同的是自变量的递增条件
判断字符数时,每读取一个就加1,初值为0
判断行数时,每读取一个换行符加1,初值为1
判断单词数时,进行单词的开头与结尾判断,每对应一次加一,但根据判断条件不同,有时要加上开头或者结尾的一个单词
void result(const char* t, const char* a, int num)
{
FILE *wt;
errno_t err;
err = fopen_s(&wt, "result.txt", "a+");
if (err != 0)
{
printf("can't write file\n");
}
fprintf(wt, "%s,%s:%d\n", t, a, num);
fclose(wt);
}
void output(const char* t, const char* w, int count, int row, int word)
{
FILE *wt;
errno_t err;
err = fopen_s(&wt, w, "a+");
if (err != 0)
{
printf("can't write file\n");
}
fprintf(wt, "%s,字符数:%d,行数:%d,单词数:%d", t, count, row, word);
fclose(wt);
}
写文件函数,a+表示不擦除之前所写的内容,且去掉之前的停止符EOF
测试
测试思路
测试要覆盖可能出现的左右情况,尽量找到代码中可能蕴含的错误并改正,因此,测试设计应该覆盖判断中的各种边界情况,,满足基本功能的所有需求,-c –w –l -o
用于测试的输入
-c test.txt
-w test.txt
-l test.txt
-c –w test.txt
-c –l test.txt
-w –l test.txt
-c –w –l test.txt
-c test.txt –o output.txt
-w test.txt –o output.txt
-l test.txt –o output.txt
-c –w test.txt –o output.txt
-c –l test.txt –o output.txt
-w –l test.txt –o output.txt
-c –w –l test.txt –o output.txt
没有写测试脚本,但测试均可通过,表示基本功能没有问题
不足
除了扩展功能和高级功能没有完成外,有以下几个不足
- 生成的result.txt和outut.txt由于没有在程序内部进行清空,会导致在多次运行后,文件内部信息比较杂乱
- 默认先-c-w-l读取文件,再-o保存数据,因此无法在二者翻转时进行正确执行,但由于需求内没有标明,没有考虑该种情况,希望老师验收时注意
- 有多个功能聚集在主函数内部,比较杂乱,没有比较好的代码优化。
收获
本次作业除了加强编程能力外,让我们对时间安排有了更充分的理解,理解了上课所学习的基本内容,初步理解的测试的相关方法,希望能在今后的学习中对软件测试有更加深刻的理解和学习
wordcount(C语言)的更多相关文章
- WordCount C语言实现求文本的字符数,单词数,行数
1.码云地址: https://gitee.com/miaomiaobobo/WordCount 2.psp表格 PSP2.1表格 PSP2.1 PSP阶段 预估耗时 (分钟) 实际耗时 (分钟) P ...
- 个人项目(WordCount C语言)
WordCount程序(C语言) Github地址:https://github.com/peter-ye-code/WordCount 一.题目描述 实现一个简单而完整的软件工具(源程序特征统计程序 ...
- 软件工程-wordcount(C语言实现)
Github项目地址:https://github.com/xiaobaot/wordcount-wc/tree/master WC 项目要求 wc.exe 是一个常见的工具,它能统计文本文件的字符数 ...
- WordCount:C语言实现
项目地址:https://github.com/m8705/WordCount 项目要求 wc.exe 是一个常见的工具,它能统计文本文件的字符数.单词数和行数. 这个项目要求写一个命令行程序,模仿已 ...
- 结对编程项目——C语言实现WordCount Web化
结对编程项目 代码地址 201631062219,201631011410 gitee项目地址:https://gitee.com/xxlznb/pair_programming 作业地址:https ...
- Scala,Java,Python 3种语言编写Spark WordCount示例
首先,我先定义一个文件,hello.txt,里面的内容如下: hello sparkhello hadoophello flinkhello storm Scala方式 scala版本是2.11.8. ...
- Spark源码编译并在YARN上运行WordCount实例
在学习一门新语言时,想必我们都是"Hello World"程序开始,类似地,分布式计算框架的一个典型实例就是WordCount程序,接触过Hadoop的人肯定都知道用MapRedu ...
- 软件工程-构建之法 WordCount小程序 统计文件中字符串个数,单词个数,词频,行数
一.前言 在之前写过一个词频统计的C语言课设,别人说你一个大三的怎么写C语言课程,我只想说我是先学习VB,VB是我编程语言的开始,然后接触到C语言及C++:再后来我是学习C++,然后反过来学习C语言, ...
- 利用Scala语言开发Spark应用程序
Spark内核是由Scala语言开发的,因此使用Scala语言开发Spark应用程序是自然而然的事情.如果你对Scala语言还不太熟悉,可 以阅读网络教程A Scala Tutorial for Ja ...
随机推荐
- ExecuteNonQuery和ExecuteScalar的区别
ExecuteNonQuery 针对 Connection 执行 SQL 语句并返回受影响的行数. 返回值 受影响的行数. 备注 您可以使用 ExecuteNonQuery 来执行目录操作(例如查 ...
- C++成员函数的存储方式
用类去定义对象时,系统会为每一个对象分配存储空间.如果一个类包括了数据和函数,要分别为数据和函数的代码分配存储空间. 按理说,如果用同一个类定义了10个对象,那么就需要分别为10个对象的数据和函数代码 ...
- asp.net曲线图
highcharts的曲线图控件真的很强大,自己研究了下,做了一个简单的,给自己留个备忘,希望能帮到需要的朋友 Dome下载:http://files.cnblogs.com/linyijia/asp ...
- 【BZOJ】1176: [Balkan2007]Mokia(cdq分治)
http://www.lydsy.com/JudgeOnline/problem.php?id=1176 在写这题的时候思维非常逗啊........2333................... 最后 ...
- Myeclipse怎么导入project项目
1,打开Meclipse,在左面的区域点击右键,选择import键. 2,在import面板中选择Exiting Projects into Workbence,点击Next, 3,选择Browse. ...
- POJ 3087 Shuffle'm Up(模拟)
Shuffle'm Up Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 7404 Accepted: 3421 Desc ...
- 【Python】用文本打印树
From:http://zhidao.baidu.com/link?url=O8U5TynGBMojDw2iFhlghPPf5_ZE1X8CAQMrK19pv-KxhvKCc6Z2yzsoQaukgN ...
- MyBitis(iBitis)系列随笔之四:多表(多对一查询操作)
前面几篇博客介绍的都是单表映射的一些操作,然而在我们的实际项目中往往是用到多表映射.至于多表映射的关键要用到mybitis的association来加以实现. 这篇介绍的是多表中 ...
- jQuery实用技巧必备
本文实例总结了经典且实用的jQuery代码开发技巧.分享给大家供大家参考.具体如下: 1. 禁止右键点击 $(document).ready(function(){ $(document).bind ...
- 修改Android 界面颜色
btnGetCode.setTextColor(getResources().getColor(R.color.dark_white)); Color.parseColor("#1a71d4 ...