代码随想录Day16
513.找树左下角的值
给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。
假设二叉树中至少有一个节点。
示例 1:
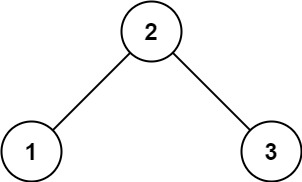
输入: root = [2,1,3]
输出: 1
示例 2:
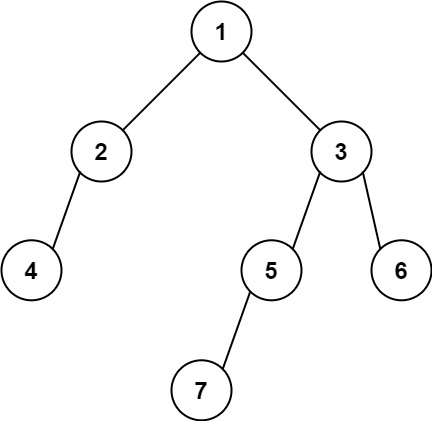
输入: [1,2,3,4,null,5,6,null,null,7]
输出: 7
提示:
二叉树的节点个数的范围是 [1,104]
-231 <= Node.val <= 231 - 1
正解
我们来分析一下题目:在树的最后一行找到最左边的值。
首先要是最后一行,然后是最左边的值。
如果使用递归法,如何判断是最后一行呢,其实就是深度最大的叶子节点一定是最后一行。
所以要找深度最大的叶子节点。
那么如何找最左边的呢?可以使用前序遍历,保证优先左边搜索;
然后记录深度最大的叶子节点,此时就是树的最后一行最左边的值。
- 确定递归函数的参数和返回值
参数必须有要遍历的树的根节点,还有就是一个int型的变量用来记录最长深度。 这里就不需要返回值了,所以递归函数的返回类型为void。
本题还需要类里的两个全局变量,maxLen用来记录最大深度,result记录最大深度最左节点的数值。 - 确定终止条件
当遇到叶子节点的时候,就需要统计一下最大的深度了,所以需要遇到叶子节点来更新最大深度。 - 确定单层递归的逻辑
在找最大深度的时候,递归的过程中依然要使用回溯。
上代码(●'◡'●)
class Solution {
public:
int maxDepth = INT_MIN;
int result;
void traversal(TreeNode* root, int depth) {
if (root->left == NULL && root->right == NULL) {
if (depth > maxDepth) {
maxDepth = depth;
result = root->val;
}
return;
}
if (root->left) {
traversal(root->left, depth + 1); // 隐藏着回溯
}
if (root->right) {
traversal(root->right, depth + 1); // 隐藏着回溯
}
return;
}
int findBottomLeftValue(TreeNode* root) {
traversal(root, 0);
return result;
}
};
112.路径总和
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
叶子节点 是指没有子节点的节点。
示例 1:
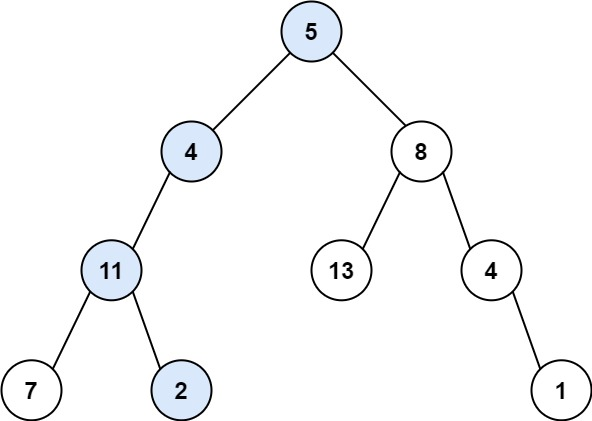
输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
输出:true
解释:等于目标和的根节点到叶节点路径如上图所示。
示例 2:
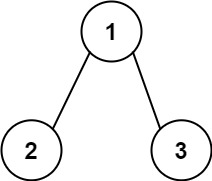
输入:root = [1,2,3], targetSum = 5
输出:false
解释:树中存在两条根节点到叶子节点的路径:
(1 --> 2): 和为 3
(1 --> 3): 和为 4
不存在 sum = 5 的根节点到叶子节点的路径。
示例 3:
输入:root = [], targetSum = 0
输出:false
解释:由于树是空的,所以不存在根节点到叶子节点的路径。
提示:
树中节点的数目在范围 [0, 5000] 内
-1000 <= Node.val <= 1000
-1000 <= targetSum <= 1000
正解
可以使用深度优先遍历的方式(本题前中后序都可以,无所谓,因为中节点也没有处理逻辑)来遍历二叉树。
- 确定递归函数的参数和返回类型
参数:需要二叉树的根节点,还需要一个计数器,这个计数器用来计算二叉树的一条边之和是否正好是目标和,计数器为int型。
返回值:遍历的路线,并不要遍历整棵树,所以递归函数需要返回值,可以用bool类型表示。 - 确定终止条件
首先计数器如何统计这一条路径的和呢?
不要去累加然后判断是否等于目标和,那么代码比较麻烦,可以用递减,让计数器count初始为目标和,然后每次减去遍历路径节点上的数值。
如果最后count == 0,同时到了叶子节点的话,说明找到了目标和。
如果遍历到了叶子节点,count不为0,就是没找到。 - 确定单层递归的逻辑
因为终止条件是判断叶子节点,所以递归的过程中就不要让空节点进入递归了。
递归函数是有返回值的,如果递归函数返回true,说明找到了合适的路径,应该立刻返回。
上代码(●'◡'●)
class Solution {
public:
bool hasPathSum(TreeNode* root, int sum) {
if (!root) return false;
if (!root->left && !root->right && sum == root->val) {
return true;
}
return hasPathSum(root->left, sum - root->val) || hasPathSum(root->right, sum - root->val);
}
};
可以看出,代码很精简,但隐藏了许多过程,包括回溯的过程;
如果都展开的话应该是这个样子:
class Solution {
private:
bool traversal(TreeNode* cur, int count) {
if (!cur->left && !cur->right && count == 0) return true; // 遇到叶子节点,并且计数为0
if (!cur->left && !cur->right) return false; // 遇到叶子节点直接返回
if (cur->left) { // 左
count -= cur->left->val; // 递归,处理节点;
if (traversal(cur->left, count)) return true;
count += cur->left->val; // 回溯,撤销处理结果
}
if (cur->right) { // 右
count -= cur->right->val; // 递归,处理节点;
if (traversal(cur->right, count)) return true;
count += cur->right->val; // 回溯,撤销处理结果
}
return false;
}
public:
bool hasPathSum(TreeNode* root, int sum) {
if (root == NULL) return false;
return traversal(root, sum - root->val);
}
};
106.从中序与后序遍历序列构造二叉树
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:
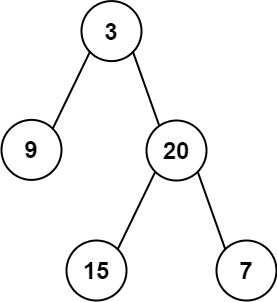
输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
输出:[3,9,20,null,null,15,7]
示例 2:
输入:inorder = [-1], postorder = [-1]
输出:[-1]
提示:
1 <= inorder.length <= 3000
postorder.length == inorder.length
-3000 <= inorder[i], postorder[i] <= 3000
inorder 和 postorder 都由 不同 的值组成
postorder 中每一个值都在 inorder 中
inorder 保证是树的中序遍历
postorder 保证是树的后序遍历
正解
首先回忆一下如何根据两个顺序构造一个唯一的二叉树:
以 后序数组的最后一个元素为切割点,先切中序数组;
根据中序数组,反过来再切后序数组。
一层一层切下去,每次后序数组最后一个元素就是节点元素。
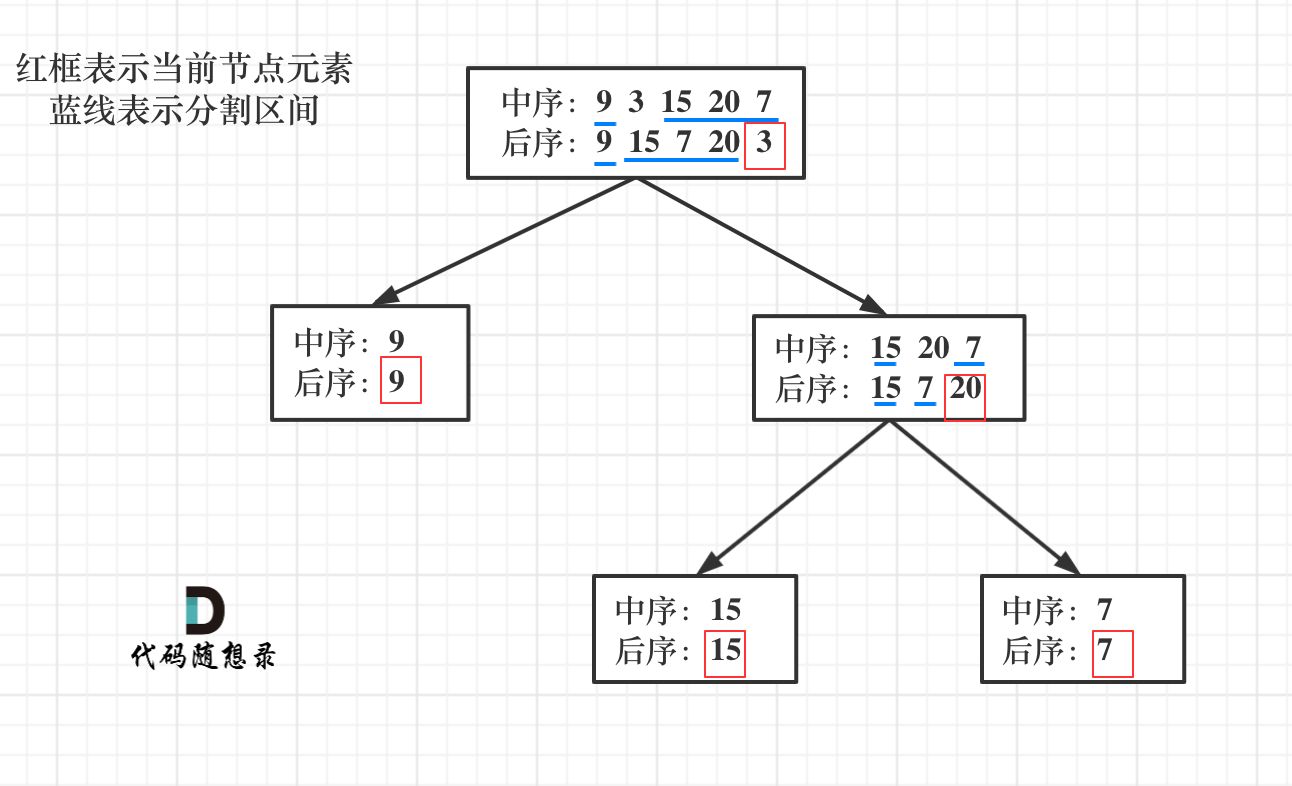
说到一层一层切割,就应该想到了递归。
来看一下一共分几步:
第一步:如果数组大小为零的话,说明是空节点了。
第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
第四步:切割中序数组,切成中序左数组和中序右数组 (注意顺序,一定是先切中序数组)
第五步:切割后序数组,切成后序左数组和后序右数组
第六步:递归处理左区间和右区间
此时应该注意确定切割的标准,是左闭右开,还有左开右闭,还是左闭右闭;
这个就是不变量,要在递归中保持这个不变量。
在切割的过程中会产生四个区间,把握不好不变量的话,一会左闭右开,一会左闭右闭,必然乱套!
首先要切割中序数组,为什么先切割中序数组呢?
切割点在后序数组的最后一个元素,就是用这个元素来切割中序数组的,所以必要先切割中序数组。
中序数组相对比较好切,找到切割点(后序数组的最后一个元素)在中序数组的位置,然后切割
接下来就要切割后序数组了。
首先后序数组的最后一个元素指定不能要了,这是切割点 也是 当前二叉树中间节点的元素,已经用了。
后序数组的切割点怎么找?
后序数组没有明确的切割元素来进行左右切割,不像中序数组有明确的切割点,切割点左右分开就可以了。
此时有一个很重的点,就是中序数组大小一定是和后序数组的大小相同的(这是必然)
中序数组我们都切成了左中序数组和右中序数组了;
那么后序数组就可以按照左中序数组的大小来切割,切成左后序数组和右后序数组。
此时,中序数组切成了左中序数组和右中序数组,后序数组切割成左后序数组和右后序数组。
接下来可以递归了。
上代码(●'◡'●)
class Solution {
private:
TreeNode* traversal (vector<int>& inorder, vector<int>& postorder) {
if (postorder.size() == 0) return NULL;
// 后序遍历数组最后一个元素,就是当前的中间节点
int rootValue = postorder[postorder.size() - 1];
TreeNode* root = new TreeNode(rootValue);
// 叶子节点
if (postorder.size() == 1) return root;
// 找到中序遍历的切割点
int delimiterIndex;
for (delimiterIndex = 0; delimiterIndex < inorder.size(); delimiterIndex++) {
if (inorder[delimiterIndex] == rootValue) break;
}
// 切割中序数组
// 左闭右开区间:[0, delimiterIndex)
vector<int> leftInorder(inorder.begin(), inorder.begin() + delimiterIndex);
// [delimiterIndex + 1, end)
vector<int> rightInorder(inorder.begin() + delimiterIndex + 1, inorder.end() );
// postorder 舍弃末尾元素
postorder.resize(postorder.size() - 1);
// 切割后序数组
// 依然左闭右开,注意这里使用了左中序数组大小作为切割点
// [0, leftInorder.size)
vector<int> leftPostorder(postorder.begin(), postorder.begin() + leftInorder.size());
// [leftInorder.size(), end)
vector<int> rightPostorder(postorder.begin() + leftInorder.size(), postorder.end());
root->left = traversal(leftInorder, leftPostorder);
root->right = traversal(rightInorder, rightPostorder);
return root;
}
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
if (inorder.size() == 0 || postorder.size() == 0) return NULL;
return traversal(inorder, postorder);
}
};
写博不易,请大佬点赞支持一下8~
代码随想录Day16的更多相关文章
- 代码随想录第十三天 | 150. 逆波兰表达式求值、239. 滑动窗口最大值、347.前 K 个高频元素
第一题150. 逆波兰表达式求值 根据 逆波兰表示法,求表达式的值. 有效的算符包括 +.-.*./ .每个运算对象可以是整数,也可以是另一个逆波兰表达式. 注意 两个整数之间的除法只保留整数部分. ...
- 代码随想录第八天 |344.反转字符串 、541. 反转字符串II、剑指Offer 05.替换空格 、151.翻转字符串里的单词 、剑指Offer58-II.左旋转字符串
第一题344.反转字符串 编写一个函数,其作用是将输入的字符串反转过来.输入字符串以字符数组 s 的形式给出. 不要给另外的数组分配额外的空间,你必须原地修改输入数组.使用 O(1) 的额外空间解决这 ...
- 代码随想录-day1
链表 今天主要是把链表专题刷完了,链表专题的题目不是很难,基本都是考察对链表的操作的理解. 在处理链表问题的时候,我们通常会引入一个哨兵节点(dummy),dummy节点指向原链表的头结点.这样,当我 ...
- 代码随想录 day0 博客怎么写
前言 2.25日开始记录自己的博客生涯以及代码随想录训练营的每日内容 一.题目链接怎么找?怎么设置连接? 力扣题目链接1:力扣 二.正文怎么写? 二分查找 算法思路: 二分查找需要保证数组为有序数组同 ...
- 【LeetCode动态规划#05】背包问题的理论分析(基于代码随想录的个人理解,多图)
背包问题 问题描述 背包问题是一系列问题的统称,具体包括:01背包.完全背包.多重背包.分组背包等(仅需掌握前两种,后面的为竞赛级题目) 下面来研究01背包 实际上即使是最经典的01背包,也不会直接出 ...
- 代码随想录算法训练营day16 | leetcode ● 104.二叉树的最大深度 559.n叉树的最大深度 ● 111.二叉树的最小深度 ● 222.完全二叉树的节点个数
基础知识 二叉树的多种遍历方式,每种遍历方式各有其特点 LeetCode 104.二叉树的最大深度 分析1.0 往下遍历深度++,往上回溯深度-- class Solution { int deep ...
- 代码随想录第七天| 454.四数相加II、383. 赎金信 、15. 三数之和 、18. 四数之和
第一题454.四数相加II 给你四个整数数组 nums1.nums2.nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 <= i, ...
- 代码随想录算法训练营day22 | leetcode 235. 二叉搜索树的最近公共祖先 ● 701.二叉搜索树中的插入操作 ● 450.删除二叉搜索树中的节点
LeetCode 235. 二叉搜索树的最近公共祖先 分析1.0 二叉搜索树根节点元素值大小介于子树之间,所以只要找到第一个介于他俩之间的节点就行 class Solution { public T ...
- 代码随想录算法训练营day17 | leetcode ● 110.平衡二叉树 ● 257. 二叉树的所有路径 ● 404.左叶子之和
LeetCode 110.平衡二叉树 分析1.0 求左子树高度和右子树高度,若高度差>1,则返回false,所以我递归了两遍 class Solution { public boolean is ...
- 代码随想录算法训练营day13
基础知识 二叉树基础知识 二叉树多考察完全二叉树.满二叉树,可以分为链式存储和数组存储,父子兄弟访问方式也有所不同,遍历也分为了前中后序遍历和层次遍历 Java定义 public class Tree ...
随机推荐
- R 语言入门学习笔记:软件安装踩坑记录——删除所有包以及彻底解决库包被安装到 C 盘用户目录下的问题,以及一些其他需要注意的点
目录 R 语言入门学习笔记:软件安装踩坑记录--删除所有包以及彻底解决库包被安装到 C 盘用户目录下的问题,以及一些其他需要注意的点 软件版本及环境 遇到的问题描述 问题的分析和探究 最终的解决方案 ...
- Python中r+,w+,a+的区别
相信有很多人对他们的区别不清楚,网上对他们的讨论又过于复杂. 其实利用光标位置来区分它们就会变得非常地简单. r+读写模式 打开文件之后光标位置位于0的位置 根据光标位置读写 w+写读模式 会清空文件 ...
- AtCoder Beginner Contest 302 H. Ball Collector 题解 可撤销并查集
为了更好的阅读体验,请单击这里 AtCoder Beginner Contest 302 H. Ball Collector 题意跳过. 可以视作将 \(a_i, b_i\) 之间连了一条边,然后 \ ...
- Android 通过odex优化提高首次开机速度
背景 客户反馈说开机时间过长,需要优化. 原文:https://blog.csdn.net/croop520/article/details/73930184 介绍 现在很多Android都需要预装很 ...
- Xilinux PS与PL交互:裸机程序读写FPGA-REG
背景 当时在搞ZYNQ驱动的时候,出于TDD的思想,从最简单的功能开始验证.因此就涉及到了下面的需求. PL侧会提供寄存器地址供PS端读写,这部分的寄存器在PL侧作为Avalon的IP,对PS端来说, ...
- Linux进程退出:SIGINT、SIGTERM 和 SIGKILL 有关信号 区别
背景 学习 海思SDK,查看例程的时候发现了类似下面的代码: int main(int argc, char *argv[]) { if(argc != 2) { printf("Usage ...
- C#/.NET/.NET Core编程技巧练习集(学习,实践干货)
DotNet Exercises介绍 DotNetGuide专栏C#/.NET/.NET Core编程常用语法.算法.技巧.中间件.类库练习集,配套详细的文章教程讲解,助你快速掌握C#/.NET/.N ...
- 数据源dataSource以及事务tx的xml文件配置方式及代码配置方式
所需要使用的依赖 <dependencies> <!--spring jdbc Spring 持久化层支持jar包--> <dependency> <grou ...
- 通过vscode写博客
通过Vscode写博客到博客园 前言 在以前的写作方式都是通过博客园内置的markdown进行工作,但是在实际使用过程中,感觉不是很方便,所以找到了用VSCode插件写作的方法. 所需插件 博客园Cn ...
- 从Java开发者到.NET Core初级工程师学习路线:C#语言基础
1. C#语言基础 1.1 C#语法概览 欢迎来到C#的世界!对于刚从Java转过来的开发者来说,你会发现C#和Java有很多相似之处,但C#也有其独特的魅力和强大之处.让我们一起来探索C#的基本语法 ...