jdk17下netty导致堆内存疯涨原因排查
背景:
介绍
天网风控灵玑系统是基于内存计算实现的高吞吐低延迟在线计算服务,提供滑动或滚动窗口内的count、distinctCout、max、min、avg、sum、std及区间分布类的在线统计计算服务。客户端和服务端底层通过netty直接进行tcp通信,且服务端也是基于netty将数据备份到对应的slave集群。
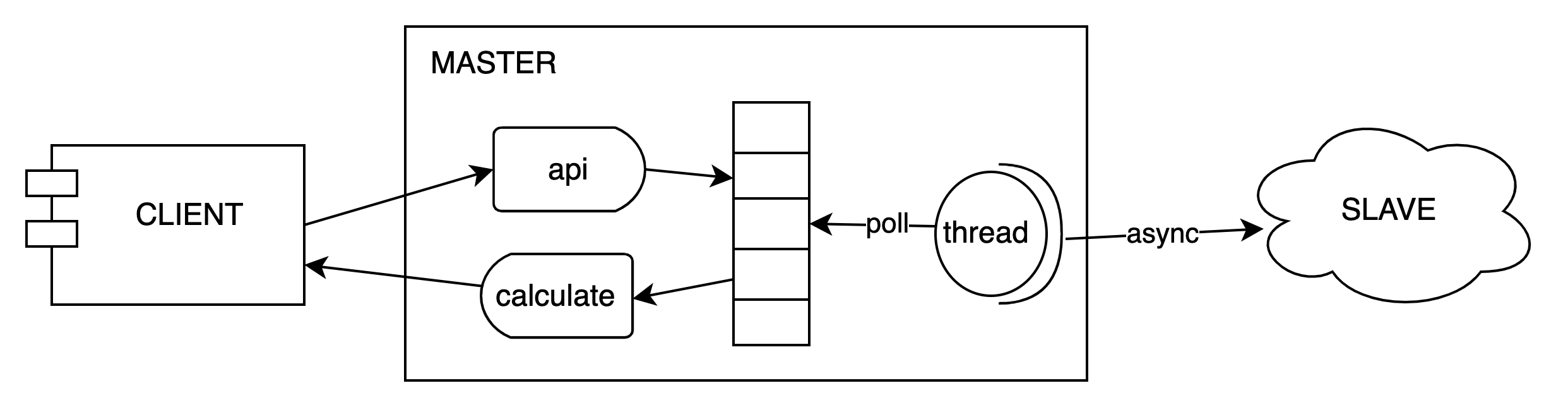
低延迟的瓶颈
灵玑第1个版本经过大量优化,系统能提供较大的吞吐量。如果对客户端设置10ms超时,服务端1wqps/core的流量下,可用率只能保证在98.9%左右,高并发情况下主要是gc导致可用率降低。如果基于cms 垃圾回收器。当一台8c16g的机器在经过第二个版本优化后吞吐量超过20wqps的时候,那么大概每4秒会产生一次gc。如果按照一次gc等于30ms。那么至少分钟颗粒度在gc时间的占比至少在(15*30/1000/60)=0.0075。也就意味着分钟级别的tp992至少在30ms。不满足相关业务的需求。
jdk17+ZGC
为了解决上述延迟过高的相关问题,JDK 11 开始推出了一种低延迟垃圾回收器 ZGC。ZGC 使用了一些新技术和优化算法,可以将 GC 暂停时间控制在 10 毫秒以内,而在 JDK 17 的加持下,ZGC 的暂停时间甚至可以控制在亚毫秒级别。实测在平均停顿时间在10us左右,主要是基于一个染色指针和读屏障做到大多数gc阶段可以做到并发的,有兴趣的同学可以了解下,并且jdk17是一个lts版本。
问题:
采用jdk17+zgc经过相关的压测后,一切都在向着好的方向发展,但是在一种特殊场景压测,需要将数据从北京数据中心同步给宿迁数据中心的时候,发现了一些诡异的事情
服务端容器的内存疯涨,并且停止压测后,内存只是非常缓慢的减少。
相关机器cpu一直保存在20%(已经无流量请求)
一直在次数不多的gc。大概每10s一次
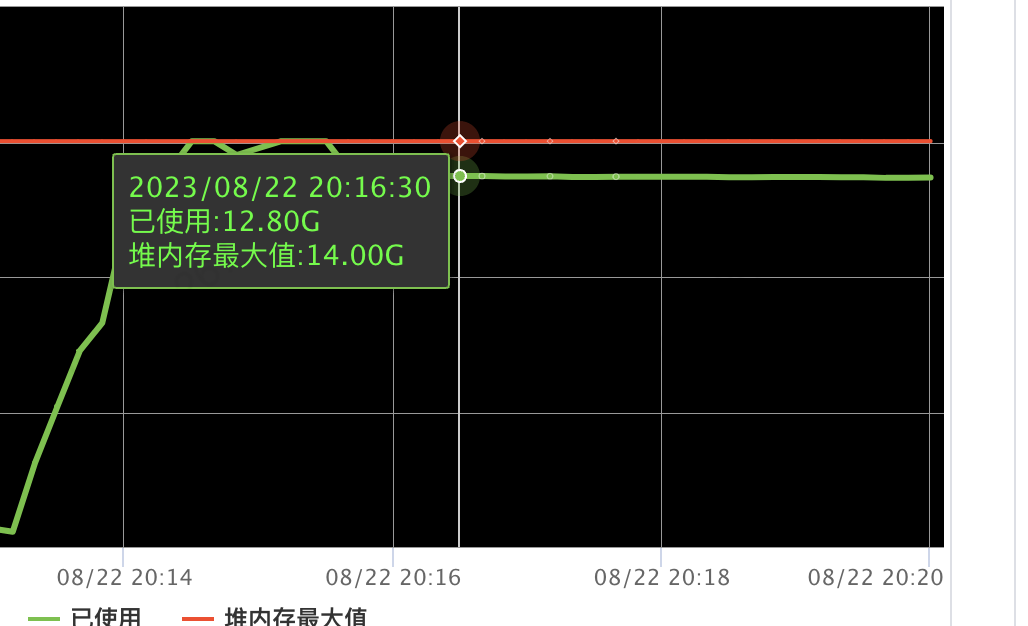
排查之旅
内存泄漏排查
第一反应是遇到内存疯涨和无法释放该问题时,首先归纳为内存泄漏问题,感觉这题也简单明了。开始相关内存泄漏检查:先dump堆内存分析发现占用堆内存的是netty相关的对象,恰好前段时间也有个同学也分享了netty下的不合理使用netty byteBuf导致的内存泄漏,进一步增加了对netty内存泄露的怀疑。 于是开启netty内存泄漏严格检查模式 (加上jvm 参数Dio.netty.leakDetection.level=PARANOID),重新试跑并没有发现相关内存泄漏日志。好吧~!初步判定不是netty内存泄漏。
jdk与netty版本bug排查
会不会是netty与jdk17兼容不好导致的bug? 回滚jdk8测试发现的确不存在这个问题,当时使用的是jdk17.0.7 版本。正好官方发布了jdk17.0.8版本,并且看到版本介绍上有若干的 Bug Fixes。所以又升级了jdk一个小版本,然而发现问题仍然在。会不会是netty的版本过低?正好看见gitup上也有类似的issue# https://github.com/netty/netty/issues/6125WriteBufferWaterMark's 并且在高版本疑似修复了该问题,修改了netty几个版本重新压测,然而发现问题仍然在。
直接原因定位与解决
经过上述两次排查,发现问题比想象中复杂,应该深入分析下为什么,重新梳理了下相关线索:
发现回滚至jdk8的时候,对应宿迁中心的集群接受到的备份数据量比北京中心发送的数据量低了很多
为什么没有流量了还一直有gc,cpu高应该是gc造成的(当时认为是zgc的内存的一些特性)
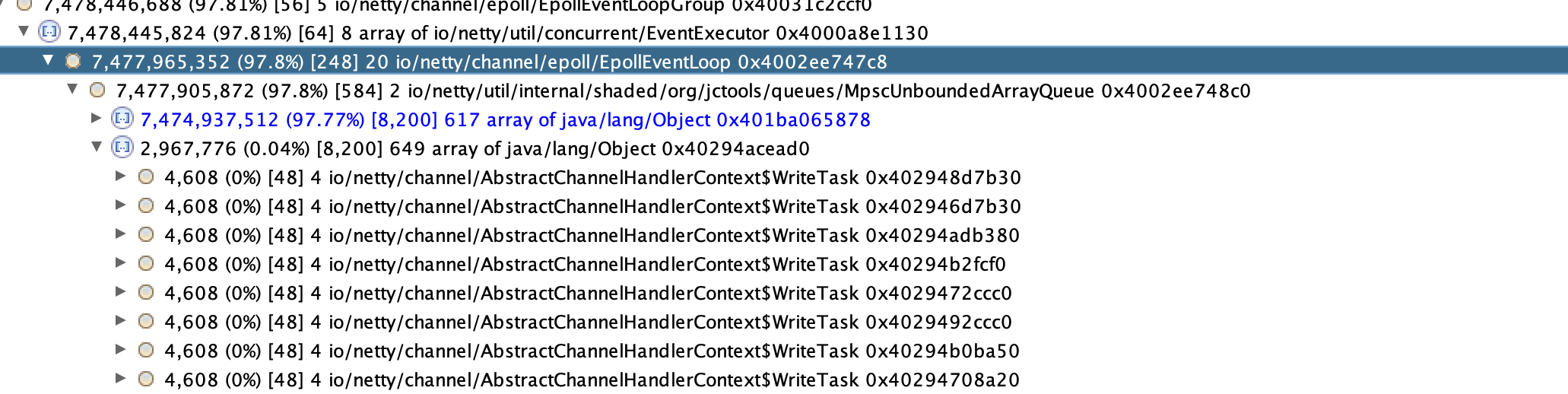
内存分析:为什么netty的MpscUnboundedArrayQueue引用了大量的AbstractChannelHandlerContext$WriteTask对象,。MpscUnboundedArrayQueue是生产消费writeAndFlush任务队列,WriteTask是相关的writeAndFlush的任务对象,正是因为大量的WriteTask对象及其引用导致了内存占用过高。
只有跨数据中心出现该问题,同数据中心数据压测不会出现该问题。
分析过后已经有了基本的猜想,因为跨数据中心下机房延迟更大,单channel信道下已经没法满足同步数据能力,导致netty的eventLoop的消费能不足导致积压。
解决方案:增加与备份数据节点的channel信道连接,采用connectionPool,每次批量同步数据的时候随机选择一个存活的channel进行数据通信。经过相关改造后发现问题得到了解决。
根因定位与解决
根因定位
虽然经过上述的改造,表面上看似解决了问题,但是问题的根本原因还是没有被发现
1.如果是eventLoop消费能力不足,为什么停止压测后,相关内存只是缓慢减少,按理说应该是疯狂的内存减少。
2.为什么一直cpu在23%左右,按照平时的压测数据,同步数据是一个流转批的操作,最多也就消耗5%cpu 左右,多出来的cpu应该是gc造成的,但是数据同步应该并不多,不应该造成这么多的gc压力。
3.为什么jdk8下不会存在该问题
推测应该是有个netty eventLoop消费耗时阻塞的操作导致消费能力大幅度下降。所以感觉还是netty的问题,于是开了netty的相关debug日志。发现了一行关键日志
[2023-08-23 11:16:16.163] DEBUG [] - io.netty.util.internal.PlatformDependent0 - direct buffer constructor: unavailable: Reflective setAccessible(true) disabled
顺着这条日志找到了本次的问题根因,为什么一个直接内存的构造器不能使用会导致我们系统WriteTask消费阻塞, 带着这个目的去查看相关的源码。
源码分析
- 一) netty 默认会用PooledByteBufAllocator来分配直接内存,采用类似jmelloc的内存池机制,每次内存不足的时候会通过创建io.netty.buffer.PoolArena.DirectArena#newChunk去预占申请内存。
protected PoolChunk<ByteBuffer> newChunk() {
// 关键代码
ByteBuffer memory = allocateDirect(chunkSize);
}
}
- 二) allocateDirect()是申请直接内存的逻辑。大致就是如果能采用底层unsafe去申请、释放直接内存和反射创建ByteBuffer对象,那么就采用unsafe。否则就直接调用java的Api ByteBuffer.allocateDirect来直接分配内存并且采用自带的Cleaner来释放内存。这里 PlatformDependent.useDirectBufferNoCleaner 是个关键点,其实就是USE_DIRECT_BUFFER_NO_CLEANER参数配置
PlatformDependent.useDirectBufferNoCleaner() ?
PlatformDependent.allocateDirectNoCleaner(capacity) : ByteBuffer.allocateDirect(capacity);
三) USE_DIRECT_BUFFER_NO_CLEANER 参数逻辑配置在PlatformDependent 类的static{}里面。
关键逻辑:maxDirectMemory==0和!hasUnsafe()在jdk17下没有特殊配置都是不满足条件的,关键是PlatformDependent0.hasDirectBufferNoCleanerConstructor的判断逻辑
if (maxDirectMemory == 0 || !hasUnsafe() || !PlatformDependent0.hasDirectBufferNoCleanerConstructor()) {
USE_DIRECT_BUFFER_NO_CLEANER = false;
} else {
USE_DIRECT_BUFFER_NO_CLEANER = true;
- 四) PlatformDependent0.hasDirectBufferNoCleanerConstructor()的判断是看PlatformDependent0的DIRECT_BUFFER_CONSTRUCTOR是否NULL,回到了刚开的debug日志,我们是可以看到在默认情况下DIRECT_BUFFER_CONSTRUCTOR该构造器是unavailable的(unavailable则为NULL)。以下代码具体的逻辑判断及其伪代码。
1.开启条件一:jdk9及其以上必须要开启jvm参数 -io.netty.tryReflectionSetAccessible参数
2.开启条件二:能反射获取到一个 private DirectByteBuffer构造器,该构造器是通过内存地址和大小来构造DirectByteBuffer.(备注:如果在jdk9以上对java.nio有模块权限限制,需要加上jvm启动参数--add-opens=java.base/java.nio=ALL-UNNAMED ,否则会报Unable to make private java.nio.DirectByteBuffer(long,int) accessible: module java.base does not "opens java.nio" to unnamed module)
所以这里我们默认是没有开启这两个jvm参数的,那么DIRECT_BUFFER_CONSTRUCTOR为空值,对应第二部PlatformDependent.useDirectBufferNoCleaner()为false。
// 伪代码,实际与这不一致
ByteBuffer direct = ByteBuffer.allocateDirect(1);
if(SystemPropertyUtil.getBoolean("io.netty.tryReflectionSetAccessible",
javaVersion() < 9 || RUNNING_IN_NATIVE_IMAGE)) {
DIRECT_BUFFER_CONSTRUCTOR =
direct.getClass().getDeclaredConstructor(long.class, int.class)
}
- 五) 现在回到第2步骤,发现PlatformDependent.useDirectBufferNoCleaner()在jdk高版本下默认值是false。那么每次申请直接内存都是通过ByteBuffer.allocateDirect来创建。那么到这个时候就已经定位到相关根因了,通过ByteBuffer.allocateDirect来申请直接内存,如果内存不足的时候会强制系统System.Gc(),并且会同步等待DirectByteBuffer通过Cleaner的虚引用回收内存。下面是ByteBuffer.allocateDirect预占内存(reserveMemory)的关键代码。大概逻辑是 触达申请的最大的直接内存->判断是否有相关的对象在gc回收->没有在回收则主动触发System.gc()来触发回收->在同步循环最多等待MAX_SLEEPS次数看是否有足够的直接内存。整个同步等待逻辑在亲测在jdk17版本最多能1秒以上。
所以最根本原因:如果这个时候我们的netty的消费者EventLoop处理消费因为申请直接内存在达到最大内存的场景,那么就会导致有大量的任务消费都会同步去等待申请直接内存上。并且如果没有足够的的直接内存,那么就会成为大面积的消费阻塞。
static void reserveMemory(long size, long cap) {
if (!MEMORY_LIMIT_SET && VM.initLevel() >= 1) {
MAX_MEMORY = VM.maxDirectMemory();
MEMORY_LIMIT_SET = true;
}
// optimist!
if (tryReserveMemory(size, cap)) {
return;
}
final JavaLangRefAccess jlra = SharedSecrets.getJavaLangRefAccess();
boolean interrupted = false;
try {
do {
try {
refprocActive = jlra.waitForReferenceProcessing();
} catch (InterruptedException e) {
// Defer interrupts and keep trying.
interrupted = true;
refprocActive = true;
}
if (tryReserveMemory(size, cap)) {
return;
}
} while (refprocActive);
// trigger VM's Reference processing
System.gc();
int sleeps = 0;
while (true) {
if (tryReserveMemory(size, cap)) {
return;
}
if (sleeps >= MAX_SLEEPS) {
break;
}
try {
if (!jlra.waitForReferenceProcessing()) {
Thread.sleep(sleepTime);
sleepTime <<= 1;
sleeps++;
}
} catch (InterruptedException e) {
interrupted = true;
}
}
// no luck
throw new OutOfMemoryError
("Cannot reserve "
+ size + " bytes of direct buffer memory (allocated: "
+ RESERVED_MEMORY.get() + ", limit: " + MAX_MEMORY +")");
} finally {
if (interrupted) {
// don't swallow interrupts
Thread.currentThread().interrupt();
}
}
}
- 六) 虽然我们看到了阻塞的原因,但是为什么jdk8下为什么就不会阻塞从4步骤中看到java 9以下是设置了DIRECT_BUFFER_CONSTRUCTOR的,因此采用的是PlatformDependent.allocateDirectNoCleaner进行内存分配。 以下是具体的介绍和关键代码
步骤一:申请内存前:通过全局内存计数器DIRECT_MEMORY_COUNTER,在每次申请内存的时候调用incrementMemoryCounter 增加相关的size,如果达到相关DIRECT_MEMORY_LIMIT(默认是-XX:MaxDirectMemorySize) 参数则直接抛出异常,而不会去同步gc等待导致大量耗时。。
步骤二:分配内存allocateDirectNoCleaner:是通过unsafe去申请内存,再用构造器DIRECT_BUFFER_CONSTRUCTOR通过内存地址和大小来构造DirectBuffer。释放也可以通过unsafe.freeMemory根据内存地址来释放相关内存,而不是通过java 自带的cleaner来释放内存。
public static ByteBuffer allocateDirectNoCleaner(int capacity) {
assert USE_DIRECT_BUFFER_NO_CLEANER;
incrementMemoryCounter(capacity);
try {
return PlatformDependent0.allocateDirectNoCleaner(capacity);
} catch (Throwable e) {
decrementMemoryCounter(capacity);
throwException(e);
return null; }
}
private static void incrementMemoryCounter(int capacity) {
if (DIRECT_MEMORY_COUNTER != null) {
long newUsedMemory = DIRECT_MEMORY_COUNTER.addAndGet(capacity);
if (newUsedMemory > DIRECT_MEMORY_LIMIT) {
DIRECT_MEMORY_COUNTER.addAndGet(-capacity);
throw new OutOfDirectMemoryError("failed to allocate " + capacity
+ " byte(s) of direct memory (used: " + (newUsedMemory - capacity)
+ ", max: " + DIRECT_MEMORY_LIMIT + ')');
}
}
}
static ByteBuffer allocateDirectNoCleaner(int capacity) {
return newDirectBuffer(UNSAFE.allocateMemory(Math.max(1, capacity)), capacity);
}
- 经过上述的源码分析,已经看到了根本原因,就是ByteBuffer.allocateDirect gc 同步等待直接内存释放导致消费能力严重不足导致的,并且在最大直接内存不足的情况下,大面积的消费阻塞耗时在申请直接内存,导致消费WriteTask能力接近于0,内存从而无法下降
总结
1.流程图:
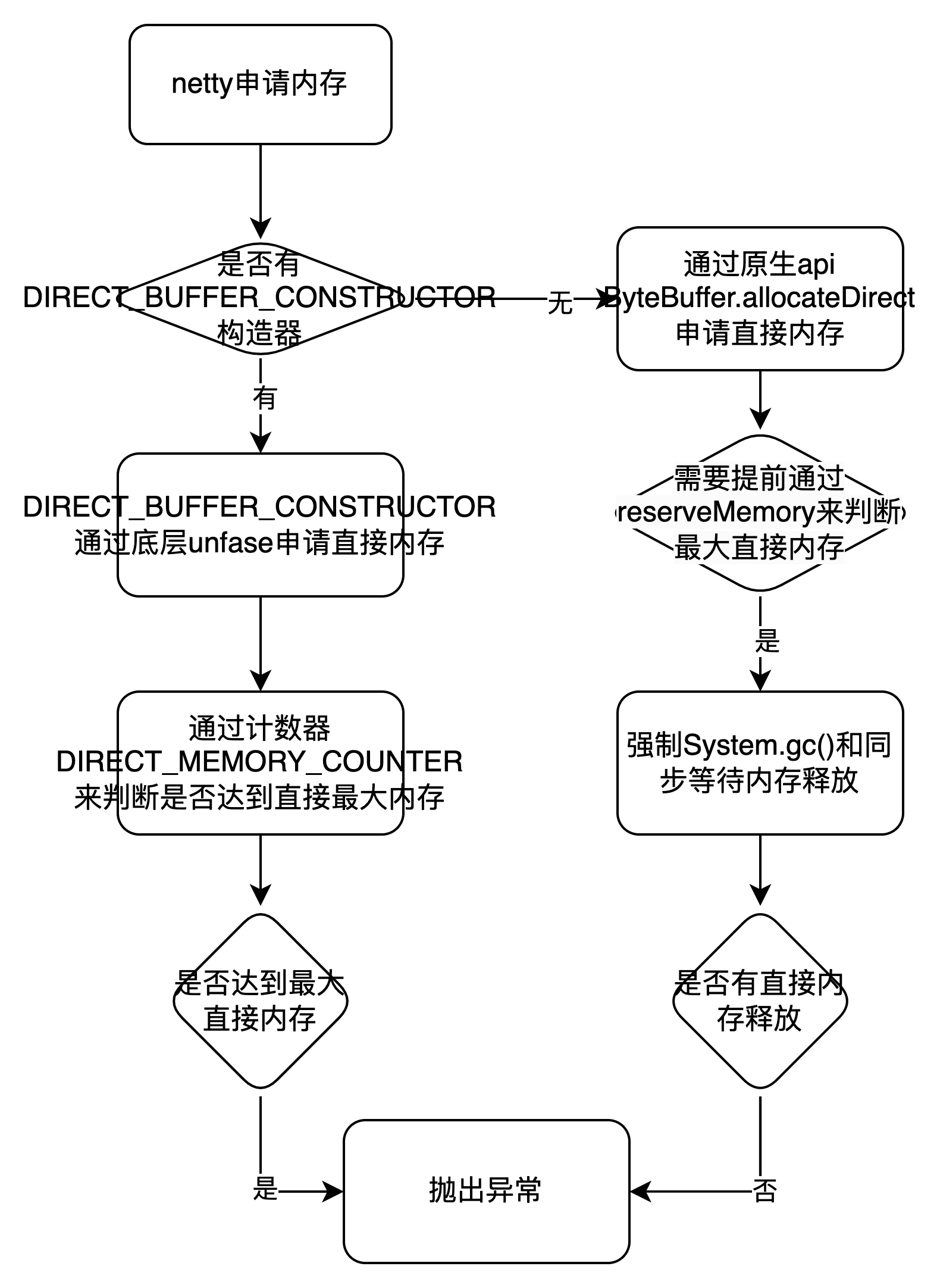
2.直接原因:
- 跨数据中心同步数据单channel管道同步数据能力不足,导致tcp环阻塞。从而导致netty eventLoop的消费WriteTask任务(WriteAndFlush)中的write能力大于flush能力,因此申请的大量的直接内存存放在ChannelOutboundBuffer#unflushedEntry链表中没法flush。
3.根本原因:
- netty在jdk高版本需要手动添加jvm参数 -add-opens=java.base/java.nio=ALL-UNNAMED和-io.netty.tryReflectionSetAccessible 来开启采用直接调用底层unsafe来申请内存,如果不开启那么netty申请内存采用ByteBuffer.allocateDirect来申请直接内存,如果EventLoop消费任务申请的直接内存达到最大直接内存场景,那么就会导致有大量的任务消费都会同步去等待申请直接内存上。并且如果没有释放足够的直接内存,那么就会成为大面积的消费阻塞,也同时导致大量的对象累积在netty的无界队列MpscUnboundedArrayQueue中。
4.反思与定位问题慢的原因:
默认同步数据这里不会是系统瓶颈,没有加上lowWaterMark和highWaterMark水位线的判断(socketChannel.isWritable()),如果同步数据达到系统瓶颈应该提前能感知到抛出异常。
同步数据的时候调用writeAndFlush应该加上相关的异常监听器(以下代码2),若果能提前感知到异常OutOfMemoryError那么更方便排查到相关问题。
(1)ChannelFuture writeAndFlush(Object msg)
(2)ChannelFuture writeAndFlush(Object msg, ChannelPromise promise);
jdk17下监控系统看到的非堆内存监控并未与系统实际使用的直接内存统计一致,导致开始定位问题无法定位到直接内存已经达到最大值,从而并未往这个方案思考。
相关引用的中间件底层通信也是依赖于netty通信,如果有类似的数据同步也可能会触发类似的问题。特别ump在高版本和titan使用netty的时候是进行了shade打包的,并且相关的jvm参数也被修改,虽然不会触发该bug,但是也可能导致触发系统gc。
ump高版本:jvm参数修改(低版本直接采用了底层socket通信,未使用netty和创建ByteBuffer) io.netty.tryReflectionSetAccessible->ump.profiler.shade.io.netty.tryReflectionSetAccessible
titan:jvm参数修改:io.netty.tryReflectionSetAccessible->titan.profiler.shade.io.netty.tryReflectionSetAccessible
作者:京东零售 刘鹏
来源:京东云开发者社区 转载请注明来源
jdk17下netty导致堆内存疯涨原因排查的更多相关文章
- StringBuilder 导致堆内存溢出
StringBuilder 导致堆内存溢出 原始问题描述: Exception in thread "main" java.lang.OutOfMemoryError: Java ...
- 解决Hangfire 导致服务器内存飙涨
最近因为项目需要调度作业服务,之前看张队推荐过一篇https://www.cnblogs.com/yudongdong/p/10942028.html 故直接拿过来实操,发现很好用,简单.方便 执行 ...
- Linux服务器Cache占用过多内存导致系统内存不足问题的排查解决(续)
作者: 大圆那些事 | 文章可以转载,请以超链接形式标明文章原始出处和作者信息 网址: http://www.cnblogs.com/panfeng412/archive/2013/12/17/dro ...
- IIS进程池异常崩溃,导致网站 service unavailable,原因排查与记录。
昨晚十点钟的样子,网站崩溃,开始 service unavailable,最近开始业务高峰,心里一惊,麻痹肯定进程池又异常崩溃了.又碰到什么问题?上次是因为一个异步线程的问题,导致了进程池直接崩溃,后 ...
- 堆内存泄漏移除导致tcp链接异常高
故障现象: 1:活动前端Nginx服务器TCP连接数到1万多 2:活动后端Tomcat其中1台TCP连接数达4千,并且CPU瞬间到780%(配置8核16G),内存正常 3:重启后端Tomcat后,TC ...
- Android一般什么情况下会导致内存泄漏
资料参考:https://blog.csdn.net/u011479990/article/details/78480091 内存泄漏的原因在于生命周期长的对象持有了生命周期短的对象的引用 内存泄漏形 ...
- 基于Java软引用机制最大使用JVM堆内存并杜绝OutOfMemory
题记:说好的坚持一周两篇文章在无数琐事和自己的懒惰下没有做好,在此表达一下对自己的不满并对有严格执行力的人深表敬意!!!! -------------------------------------- ...
- 源码角度分析-newFixedThreadPool线程池导致的内存飙升问题
前言 使用无界队列的线程池会导致内存飙升吗?面试官经常会问这个问题,本文将基于源码,去分析newFixedThreadPool线程池导致的内存飙升问题,希望能加深大家的理解. (想自学习编程的小伙伴请 ...
- 一次bug死磕经历之Hbase堆内存小导致regionserver频繁挂掉
环境如下: Centos6.5 Apache Hadoop2.7.1 Apache Hbase0.98.12 Apache Zookeeper3.4.6 JDK1.7 Ant1.9.5 Maven3. ...
- Linux堆内存管理深入分析(下)
Linux堆内存管理深入分析 (下半部) 作者@走位,阿里聚安全 0 前言回顾 在上一篇文章中(链接见文章底部),详细介绍了堆内存管理中涉及到的基本概念以及相互关系,同时也着重介绍了堆中chunk分 ...
随机推荐
- 【汇编】masm文件夹整理
整理masm文件夹 前言 不好意思,我又来了,今天上汇编课,发现汇编masm文件夹实在是太乱了,像这样: 着实太乱了!程序一多就会很乱很让人心烦!(虽然我现在没有认真上汇编课吧,就这几个文件) 开始折 ...
- 探索JS中this的最终指向
js 中的this 指向 一直是前端开发人员的一个痛点难点,项目中有很多bug往往是因为this指向不明确(this指向在函数定义时无法确定,只有在函数被调用时,才确定该this的指向为最终调用它的对 ...
- 曲线艺术编程 coding curves 第六章 平托图 (Pintographs)
第六章 平托图 (Pintographs) 原作:Keith Peters https://www.bit-101.com/blog/2022/11/coding-curves/ 译者:池中物王二狗( ...
- docker镜像的原理
docker镜像的原理 docker镜像是由特殊的文件系统叠加而成 最低端是bootfs,并使用宿主机的bootfs 第二层是root文件系统rootfs,称之为base image 再往上是可叠加的 ...
- 2023 华北分区赛 normal_snake
国赛终于解出Java题了,顺利拿下一血,思路之前也学过.继续加油 normal_snake 题目解读 @RequestMapping({"/read"}) public Strin ...
- 我在 vscode 插件里接入了 ChatGPT,解决了代码变量命名的难题
lowcode 插件 已经迭代了差不多3年.作为我的生产力工具,平常一些不需要动脑的搬砖活基本上都是用 lowcode 去完成,比如管理脚手架,生成 CURD 页面,根据接口文档生成 TS 类型,生成 ...
- Rust 内存系统
第四章 内存系统 不同的编程语言对内存有着不同的管理方式. 按照内存的管理方式可将编程语言大致分为两类: 手动管理类 手动内存管理类需要开发者使用malloc和free等函数显式管理内存. 自动内存管 ...
- 洛谷 P9047 [PA2021] Poborcy podatkowi
题意 给一棵有边权的树,从中选出若干条长度为 4 的路径,要求边不交,求最大权值和. 数据范围:\(1\le n\le 2\times 10^5, -10^9\le w\le 10^9\). 题解 考 ...
- 洛谷 P5979 [PA2014] Druzyny
简要题意 有 \(n\) 个人,把他们划分成尽可能多的区间,其中第 \(i\) 个人要求它所在的区间长度大于等于 \(c_i\),小于等于 \(d_i\),求最多的区间数量以及如此划分的方案数. 数据 ...
- 前端Vue自定义导航栏菜单 定制左侧导航菜单按钮 中部logo图标 右侧导航菜单按钮
前端Vue自定义导航栏菜单 定制左侧导航菜单按钮 中部logo图标 右侧导航菜单按钮, 下载完整代码请访问uni-app插件市场地址:https://ext.dcloud.net.cn/plugin? ...