千万级数据的表,我把慢sql优化后性能提升30倍!
分享技术,用心生活
背景:系统中有一个统计页面加载特别慢,前端设置的40s超时时间都加载不出来数据,因为是个统计页面,基本上一猜就知道是mysql的语句有问题,遗留了很久没有解决,正好趁不忙的时候,下定决心一定把它给搞定!
1. 分析原因
(mysql5.7)
执行一下问题sql,可以看到单表查就需要61s 这怎么能忍受?

通过explain看一下执行计划

挑重点,可以看到用命中了名为idx_first_date的索引,但是rows中扫描了1000多万行的数据,这显然是sql慢的根源。我们来查一下表数据量:
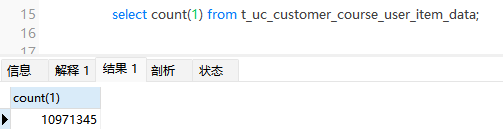
真真的千万级的大表!
找到原因后,那么就需要明确优化方向
- 通过设置分区
- 通过水平分表
- 通过优化sql
我们大概会有以上三种思路
分区方案会有诸多限制,比如可能会索引失效,占用内存,有主键限制等,故不采纳
分表方案看来可行,通过缩小热点数据,把非热点数据全部放入分表。是可以达到效果。不过查询表写入日期后,发现最早在2021年。目前系统内查询统计还会经常用到2021年数据。如果贸然分表后,带来的连表查询,数据管理问题等,现有代码可能会出大问题。
那么就只剩下优化sql这一条路了,虽然是千万级数据的表,但是你要相信mysql是可以支撑的。
确定方向后,那就需要解决如何通过减少数据的扫描来实现提升性能。
通过sql可以看到,这个统计sql是根据日期查询的,而且也命中了索引,那么为什么还会扫描这么多数据呢?我们再去看下表的索引

发现猫腻了吧,idx_first_date是个联合索引,再根据上图key_len长度为67和最左匹配原则可知,mysql执行器是优先使用customer_id去扫描数据。所以几乎全表扫描了。
我们把idx_first_date修改一下联合索引的字段顺序,把first_date放在第一位,我们再来执行一下sql看下结果

1.6s!大呼!性能直接提升30倍!
你以为到这里就结束了吗?不不不!再看一张图

发现了吗,因为用了联合索引,导致索引占用空间过大,比数据占用都大。我认为这里存在滥用索引的现象。索引本身不止会占用空间,而且也会降低写入性能,维护更新索引成本过高等。
把idx_first_date中的customer_id字段去掉,再看下索引占用情况
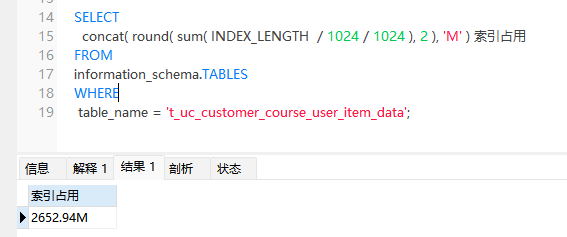
下降至2.6G,减少了将近1.4G的索引占用。
至此,这张千万数据的大表慢sql已优化完,不仅提升了查询性能,也减少了索引带来的空间占用过大的问题。
本文由mdnice多平台发布
千万级数据的表,我把慢sql优化后性能提升30倍!的更多相关文章
- MySQL百万级、千万级数据多表关联SQL语句调优
本文不涉及复杂的底层数据结构,通过explain解释SQL,并根据可能出现的情况,来做具体的优化,使百万级.千万级数据表关联查询第一页结果能在2秒内完成(真实业务告警系统优化结果).希望读者能够理解S ...
- 4W条人才表循环处理业务sql优化过程
场景: 使用windows服务定时更新合同数据:执行存储过程(pas_RefreshContractStatus),但存储过程里面有一个需要更新4W条人才表循环处理业务 问题: 循环更新4W条人才表状 ...
- 从两表连接看Oracle sql优化器的效果
select emp.*,dept.* from tb_emp03 emp,tb_dept03 dept where emp.deptno=dept.id -- 不加hint SQL> sele ...
- MySQL千万级数据分区存储及查询优化
作为传统的关系型数据库,MySQL因其体积小.速度快.总体拥有成本低受到中小企业的热捧,但是对于大数据量(百万级以上)的操作显得有些力不从心,这里我结合之前开发的一个web系统来介绍一下MySQL数据 ...
- Mysql千万级数据删除实操-企业案例
某天,在生产环节中,发现一个定时任务表,由于每次服务区查询这个表就会造成慢查询,给mysql服务器带来不少压力,经过分析,该表中绝对部分数据是垃圾数据 需要删除,约1050万行,由于缺乏处理大数据的额 ...
- (转载)MYSQL千万级数据量的优化方法积累
转载自:http://blog.sina.com.cn/s/blog_85ead02a0101csci.html MYSQL千万级数据量的优化方法积累 1.分库分表 很明显,一个主表(也就是很重要的表 ...
- 转载自lanceyan: 一致性hash和solr千万级数据分布式搜索引擎中的应用
一致性hash和solr千万级数据分布式搜索引擎中的应用 互联网创业中大部分人都是草根创业,这个时候没有强劲的服务器,也没有钱去买很昂贵的海量数据库.在这样严峻的条件下,一批又一批的创业者从创业中获得 ...
- 构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(37)-文章发布系统④-百万级数据和千万级数据简单测试
原文:构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(37)-文章发布系统④-百万级数据和千万级数据简单测试 系列目录 我想测试EF在一百万条数据下的显示时间! ...
- mysql千万级数据量查询出所有重复的记录
查询重复的字段需要创建索引,多个条件则创建组合索引,各个条件的索引都存在则不必须创建组合索引 有些情况直接使用GROUP BY HAVING则能直接解决:但是有些情况下查询缓慢,则需要使用下面其他的方 ...
- MySQL 千万 级数据量根据(索引)优化 查询 速度
一.索引的作用 索引通俗来讲就相当于书的目录,当我们根据条件查询的时候,没有索引,便需要全表扫描,数据量少还可以,一旦数据量超过百万甚至千万,一条查询sql执行往往需要几十秒甚至更多,5秒以上就已经让 ...
随机推荐
- 蓝桥杯真题 k倍区间
考点: - 利用前缀和求子列和 - 同余作差是模的倍数 题目概要 给定一个长度为N的数列,A1, A2, - AN,如果其中一段连续的子序列Ai, Ai+1, - Aj(i <= j)之和是K的 ...
- macbook苹果m1芯片训练机器学习、深度学习模型,resnet101在mnist手写数字识别上做加速,torch.device("mps")
apple的m1芯片比以往cpu芯片在机器学习加速上听说有15倍的提升,也就是可以使用apple mac训练深度学习pytorch模型!!!惊呆了 安装apple m1芯片版本的pytorch 然后使 ...
- IT入门深似海,入门到放弃你学废了嘛
我一直觉得IT行业 程序员行业.甚至觉得程序员人群 是一个特殊存在的群体. 入门到放弃,是真的,IT门槛高嘛. 其实吧,IT编程门槛,是有的,但是对于感兴趣的,想学习IT编程同学来说,也是一件容易事情 ...
- golang 包管理
- Python 列表、字典、元组的一些小技巧
1. 字典排序 我们知道 Python 的内置 dictionary 数据类型是无序的,通过 key 来获取对应的 value.可是有时我们需要对 dictionary 中的 item 进行排序输出, ...
- CMU15445 (Fall 2020) 数据库系统 Project#2 - B+ Tree 详解(上篇)
前言 考虑到 B+ 树较为复杂,CMU15-445 将 B+ 树实验拆成了两部分,这篇博客将介绍 Checkpoint#1 部分的实现过程,搭配教材 <DataBase System Conce ...
- MySQL8新特性窗口函数详解
本文博主给大家详细讲解一波 MySQL8 的新特性:窗口函数,相信大伙看完一定能有所收获. 本文提供的 sql 示例都是基于 MySQL8,由博主亲自执行确保可用 博主github地址:http:// ...
- requests Python中最好用的网络请求工具 基础速记+最佳实践
简介 requests 模块是写python脚本使用频率最高的模块之一.很多人写python第一个使用的模块就是requests,因为它可以做网络爬虫.不仅写爬虫方便,在日常的开发中更是少不了requ ...
- 鸿蒙星空的太白星 | WebView给元服务调用JS API指明方向
漆黑深夜夜凉如水,繁星盛开于无垠苍穹.清风徐来,一片薄云,夜空顿然失色,有些阴霾.天空中最亮的星,太白星,在薄云中依然闪耀,如同海上迷雾中的灯塔,为迷失方向的船只指明方向. 元服务是华为提供的一种面 ...
- [渗透测试]—7.1 漏洞利用开发和Shellcode编写
在本章节中,我们将学习漏洞利用开发和Shellcode编写的基本概念和技巧.我们会尽量详细.通俗易懂地讲解,并提供尽可能多的实例. 7.1 漏洞利用开发 漏洞利用开发是渗透测试中的高级技能.当你发现一 ...