算法金 | 再见,支持向量机 SVM!

大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
今日 170+/10000

一、SVM概述
定义与基本概念
支持向量机(SVM)是一种监督学习模型,用于解决分类和回归问题。它的核心思想是在特征空间中寻找一个最优的超平面,以此作为决策边界来区分不同类别的数据。SVM的目标是最大化这个决策边界的间隔,即数据点到超平面的最短距离。间隔越大,模型的泛化能力越强,越能减少过拟合的风险。SVM由 Vapnik 在 1995 年提出,因其出色的性能和广泛的应用,迅速成为机器学习领域的一个重要算法。
SVM的发展历史和应用领域
SVM 的发展可以追溯到 1963 年,当时 Vapnik 和 Chervonenkis 提出了一种基于最大间隔的分类方法。1990 年代,Vapnik 等人进一步发展了这一方法,并引入了核技巧,使得 SVM 能够处理非线性问题。如今,SVM 已经被广泛应用于多个领域,包括图像识别、文本分类、生物信息学、金融市场分析等。特别是在高维数据集上,SVM 展现出了卓越的性能。
SVM与其他机器学习算法的比较
与其他机器学习算法相比,SVM 在处理高维数据集时具有明显的优势。它不仅能够提供较高的分类准确率,而且泛化能力强,不容易过拟合。
如下试验中,SVM表现均最优,是神经网络崛起前名副其实的王者
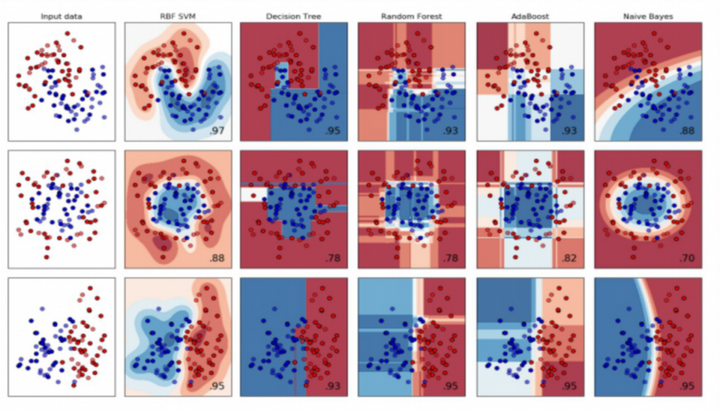
二、SVM的关键术语
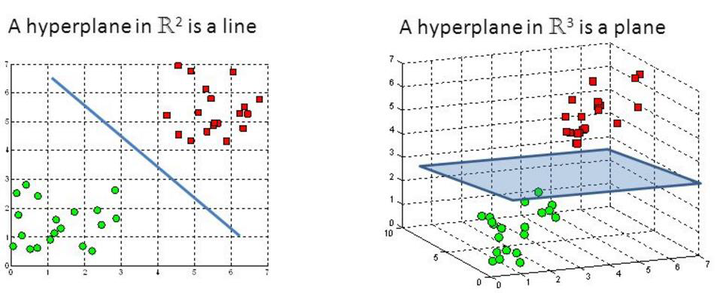
超平面:数据分类的边界
超平面是 SVM 中用于区分不同类别数据的线性边界。在二维空间中,它表现为一条直线;在三维空间中,它是一个平面;而在更高维的空间中,则是一个超平面。超平面的方程通常由权重向量和偏置项确定。
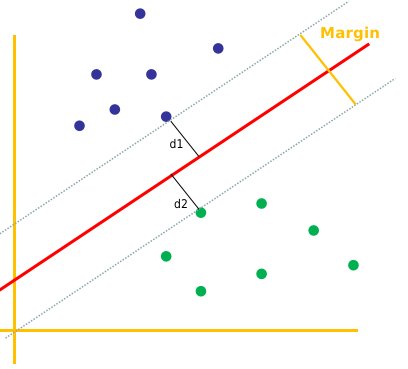
间隔:超平面与最近数据点的距离
间隔指的是超平面与最近的数据点之间的距离。间隔的大小直接影响到 SVM 模型的泛化能力。一个较大的间隔意味着模型在面对新的、未见过的数据时,有更高的准确率。
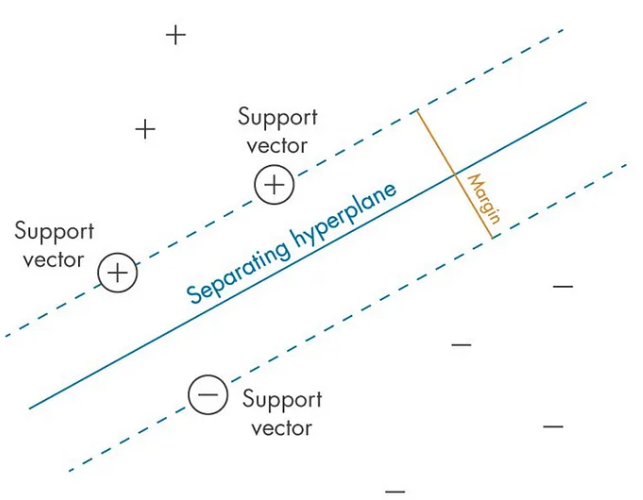
支持向量:决定超平面位置的关键数据点
支持向量是那些位于间隔边缘的数据点,它们是 SVM 模型中最关键的部分。这些数据点支撑着超平面,决定了其位置和方向。如果从数据集中移除这些支持向量,超平面的位置将会发生改变,从而影响模型的分类能力。

三、SVM的工作原理
分类问题的直观理解
在分类问题中,SVM 的目标是找到一个能够最好地区分不同类别的决策边界。这个边界被称为超平面,它能够将数据空间划分为两部分,每部分包含一个类别的所有数据点。SVM 通过最大化数据点到这个超平面的间隔来确定最优的决策边界,从而确保分类的准确性和模型的泛化能力。
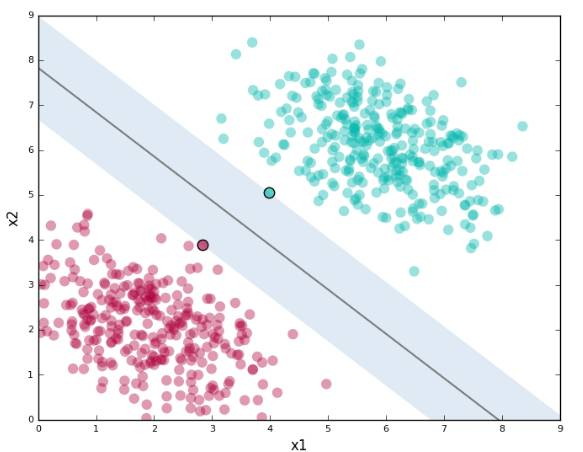
超平面与决策边界的概念
超平面是 SVM 中用于分类的线性边界,它可以是二维空间中的直线,三维空间中的平面,或者更高维空间中的超平面。决策边界是超平面在数据空间中的投影,它定义了数据点的分类。SVM 通过优化这些边界来实现对数据点的最佳分类。
间隔最大化原则
间隔是超平面与最近数据点之间的距离。SVM 的间隔最大化原则是指在所有可能的超平面中,选择一个使得间隔最大的超平面作为决策边界。这样做可以提高模型的泛化能力,因为它减少了模型对训练数据中噪声的敏感性。
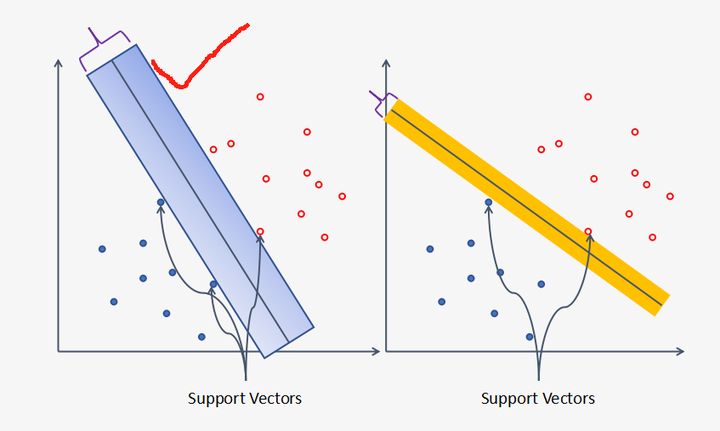
支持向量的作用与重要性
支持向量是那些位于间隔边缘的数据点,它们是定义超平面位置的关键。这些数据点对模型的构建至关重要,因为它们直接影响到超平面的位置和方向。如果移除了这些支持向量,超平面的位置将会改变,从而导致模型性能的下降。因此,在 SVM 中,支持向量的识别和利用是实现最优分类的关键步骤。

四、线性与非线性SVM
线性SVM:适用于线性可分数据
线性 SVM 是 SVM 算法的基本形式,它在处理线性可分数据集时非常有效。这种类型的 SVM 通过在特征空间中寻找一个线性超平面来分隔不同类别的数据点。线性 SVM 的优点在于其简单性和计算效率。
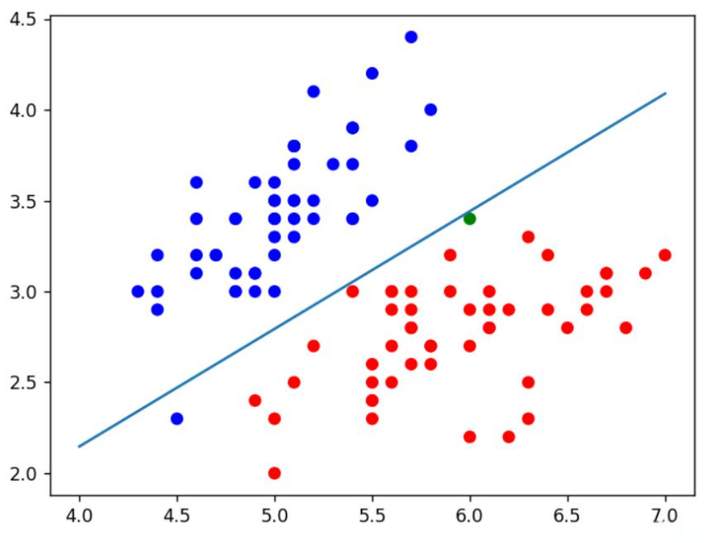
非线性SVM:通过核函数处理非线性可分数据
当数据集不是线性可分的时候,非线性 SVM 通过核函数将原始数据映射到一个更高维的空间,使得数据在这个新空间中线性可分。这种方法允许 SVM 处理更复杂的数据关系和模式。
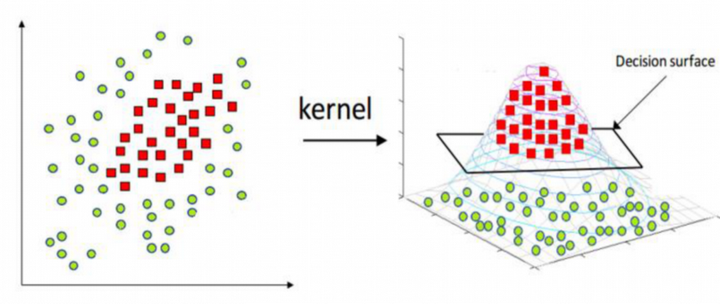
核函数的类型与选择
核函数是一种数学工具,用于在不显式计算高维空间中的点积的情况下,将数据映射到高维空间。常用的核函数包括线性核、多项式核、径向基函数(RBF)核和 Sigmoid 核等。选择合适的核函数对于提高 SVM 模型的性能至关重要。
五、SVM的优缺点
优点:高维数据处理能力强,泛化性能好
SVM 算法在处理高维数据集时表现出色,能够有效地找到最优的决策边界。由于其间隔最大化原则,SVM 具有很好的泛化能力,能够减少过拟合的风险,使得模型在未知数据上也能保持较高的准确率。
缺点:参数选择复杂,计算成本高,对噪声敏感
SVM 算法的性能受到核函数和正则化参数选择的影响,这些参数需要通过交叉验证等方法来确定,过程较为复杂。此外,SVM 的计算成本相对较高,尤其是在处理大规模数据集时。SVM 对噪声数据也比较敏感,这可能会影响模型的性能和泛化能力。
六、SVM在实际问题中的应用
二元分类问题
SVM 在处理二元分类问题时非常有效,例如在垃圾邮件识别中,SVM 能够准确地将邮件分类为垃圾邮件或非垃圾邮件。其强大的分类能力和对高维数据的处理能力使其成为这类问题的理想选择。
文本分类与情感分析
在文本分类和情感分析领域,SVM 通过提取文本特征来进行分类任务。它可以区分不同类别的文档,如新闻文章的分类,或者在社交媒体上对用户评论的情感倾向进行分类。
图像识别与物体检测
SVM 也被广泛应用于图像识别和物体检测任务中。例如,在面部识别系统中,SVM 可以用于区分不同的人脸特征。此外,它还可以用于图像中的物体识别和场景分类。
医学诊断与生物信息学
在医学诊断领域,SVM 可以分析医学图像,如 MRI 或 CT 扫描,以辅助诊断。在生物信息学中,SVM 用于分析基因表达数据,帮助识别疾病标记物或预测疾病风险。

七、SVM的模型建立
数据预处理的重要性
在建立 SVM 模型之前,进行数据预处理是至关重要的一步。这包括数据清洗、标准化和归一化等步骤,以确保数据的质量并提高模型的性能。预处理可以帮助减少模型训练时间,并提高模型对新数据的泛化能力。
选择合适的核函数和参数
SVM 的性能在很大程度上取决于核函数的选择和参数的设定。核函数的选择决定了数据在特征空间中的映射方式,而参数则影响模型的复杂度和对数据的拟合程度。通常需要通过交叉验证等方法来选择最合适的核函数和参数。
软间隔与硬间隔的概念
硬间隔 SVM 要求所有的训练数据点都必须正确分类,并且与决策边界保持一定的距离。而软间隔 SVM 允许一些数据点违反间隔原则,以换取更好的泛化能力。软间隔通过引入松弛变量来实现,这使得模型在面对复杂数据集时更加灵活。
正则化和模型复杂度控制
正则化是防止 SVM 模型过拟合的重要技术。通过在损失函数中加入正则化项,可以控制模型的复杂度,避免模型对训练数据过度拟合。正则化参数的选择需要权衡模型的复杂度和分类误差,以达到最佳的泛化性能。

import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs, make_circles
# 创建一个线性可分数据集
def generate_linear_data():
# 假设 "武当" 和 "少林" 是两个不同的武侠门派
X, y = make_blobs(n_samples=100, centers=[[-2, 2], [2, -2]], cluster_std=0.8, random_state=42)
y = np.where(y == 0, '武当', '少林')
return X, y
# 创建一个线性不可分数据集
def generate_nonlinear_data():
# 假设 "武当" 和 "少林" 是两个不同的武侠门派
X, y = make_circles(n_samples=100, factor=0.5, noise=0.1, random_state=42)
y = np.where(y == 0, '武当', '少林')
return X, y
# 可视化数据集
def plot_data(X, y, title, ax):
colors = ['r' if label == '武当' else 'b' for label in y]
ax.scatter(X[:, 0], X[:, 1], c=colors, edgecolor='k', s=100)
ax.set_title(title)
ax.set_xlabel('特征 1')
ax.set_ylabel('特征 2')
# 可视化决策边界
def plot_decision_boundary(X, y, clf, title, ax):
colors = ['r' if label == '武当' else 'b' for label in y]
ax.scatter(X[:, 0], X[:, 1], c=colors, edgecolor='k', s=100)
xlim = ax.get_xlim()
ylim = ax.get_ylim()
xx, yy = np.meshgrid(np.linspace(xlim[0], xlim[1], 100),
np.linspace(ylim[0], ylim[1], 100))
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contour(xx, yy, Z, colors='k', levels=[0], alpha=0.5, linestyles=['-'])
ax.set_title(title)
ax.set_xlabel('特征 1')
ax.set_ylabel('特征 2')
# 生成线性可分数据集并训练 SVM
X_linear, y_linear = generate_linear_data()
clf_linear = svm.SVC(kernel='linear')
clf_linear.fit(X_linear, y_linear)
# 生成线性不可分数据集并训练 SVM
X_nonlinear, y_nonlinear = generate_nonlinear_data()
clf_nonlinear = svm.SVC(kernel='rbf', gamma=1)
clf_nonlinear.fit(X_nonlinear, y_nonlinear)
# 创建图像网格
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# 可视化线性可分数据集
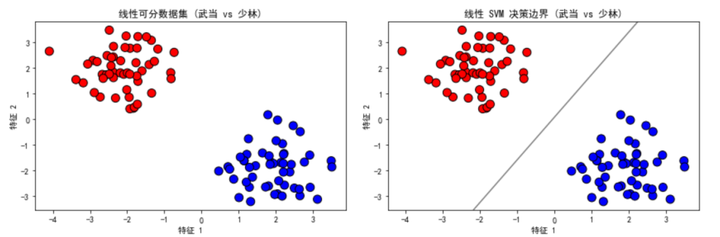
plot_data(X_linear, y_linear, "线性可分数据集 (武当 vs 少林)", axes[0, 0])
plot_decision_boundary(X_linear, y_linear, clf_linear, "线性 SVM 决策边界 (武当 vs 少林)", axes[0, 1])
# 可视化线性不可分数据集
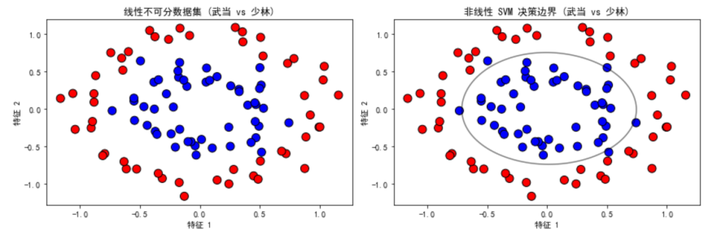
plot_data(X_nonlinear, y_nonlinear, "线性不可分数据集 (武当 vs 少林)", axes[1, 0])
plot_decision_boundary(X_nonlinear, y_nonlinear, clf_nonlinear, "非线性 SVM 决策边界 (武当 vs 少林)", axes[1, 1])
plt.tight_layout()
plt.show()
代码说明
- 生成线性可分数据集:使用 make_blobs 函数生成两个不同的中心点,分别代表 "武当" 和 "少林" 两个门派。
- 生成线性不可分数据集:使用 make_circles 函数生成圆环形数据,模拟 "武当" 和 "少林" 门派的数据,代表非线性可分的情况。
- 可视化数据集:通过颜色区分不同门派的数据点,并标注出两个特征的坐标。
- 训练 SVM 模型:分别对线性可分数据集和线性不可分数据集训练 SVM 模型,使用不同的核函数(线性核和 RBF 核)。
- 可视化决策边界:绘制 SVM 模型的决策边界,展示模型如何区分不同门派的数据。
这个示例将武侠元素融入数据集中,直观展示了 SVM 如何处理线性可分和线性不可分的数据。

算法金 | 再见,支持向量机 SVM!的更多相关文章
- 【机器学习算法-python实现】svm支持向量机(1)—理论知识介绍
(转载请注明出处:http://blog.csdn.net/buptgshengod) 1.背景 强烈推荐阅读(http://www.cnblogs.com/jerrylead/archiv ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
- 机器学习算法 - 支持向量机SVM
在上两节中,我们讲解了机器学习的决策树和k-近邻算法,本节我们讲解另外一种分类算法:支持向量机SVM. SVM是迄今为止最好使用的分类器之一,它可以不加修改即可直接使用,从而得到低错误率的结果. [案 ...
- 一步步教你轻松学支持向量机SVM算法之案例篇2
一步步教你轻松学支持向量机SVM算法之案例篇2 (白宁超 2018年10月22日10:09:07) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 一步步教你轻松学支持向量机SVM算法之理论篇1
一步步教你轻松学支持向量机SVM算法之理论篇1 (白宁超 2018年10月22日10:03:35) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 机器学习集成算法--- 朴素贝叶斯,k-近邻算法,决策树,支持向量机(SVM),Logistic回归
朴素贝叶斯: 是使用概率论来分类的算法.其中朴素:各特征条件独立:贝叶斯:根据贝叶斯定理.这里,只要分别估计出,特征 Χi 在每一类的条件概率就可以了.类别 y 的先验概率可以通过训练集算出 k-近邻 ...
- 转:机器学习中的算法(2)-支持向量机(SVM)基础
机器学习中的算法(2)-支持向量机(SVM)基础 转:http://www.cnblogs.com/LeftNotEasy/archive/2011/05/02/basic-of-svm.html 版 ...
- 4、2支持向量机SVM算法实践
支持向量机SVM算法实践 利用Python构建一个完整的SVM分类器,包含SVM分类器的训练和利用SVM分类器对未知数据的分类, 一.训练SVM模型 首先构建SVM模型相关的类 class SVM: ...
- 机器学习第7周-炼数成金-支持向量机SVM
支持向量机SVM 原创性(非组合)的具有明显直观几何意义的分类算法,具有较高的准确率源于Vapnik和Chervonenkis关于统计学习的早期工作(1971年),第一篇有关论文由Boser.Guyo ...
- [白话解析] 深入浅出支持向量机(SVM)之核函数
[白话解析] 深入浅出支持向量机(SVM)之核函数 0x00 摘要 本文在少用数学公式的情况下,尽量仅依靠感性直觉的思考来讲解支持向量机中的核函数概念,并且给大家虚构了一个水浒传的例子来做进一步的通俗 ...
随机推荐
- LTV预估的一些思考
什么是LTV 用户生命周期价值(Lifetime Value, LTV)是一个非常重要的指标,定义为单个用户在某种生命周期内(i.e. 从开始使用产品到停止使用期间) 为产品创造的总价值. 比如GMV ...
- sql 语句系列(插入系列)[八百章之第五章]
复制数据到另外一个表 这个不解释,只是自我整理. insert EMP_EAST (DEPTNO,DNAME,LOC) select DEPTNO,DNAME,LOC from DEPT where ...
- 纯钧chunjun的http-x插件修复
简介 chunjun是一款基于flink的开源数据同步工具,官方文档,其提供了很多flink官方未提供的插件供大家来使用,特别是达梦插件在国产化环境中很方便! 本次介绍的是chunjun中的一款htt ...
- 【转】Java程序员常用工具类库 - 目录
原文地址:http://rensanning.iteye.com/blog/1553076 有人说当你开始学习Java的时候,你就走上了一条不归路,在Java世界里,包罗万象,从J2SE,J2ME,J ...
- 这些Git事故灾难, 你经历过几个?
前言 关于Git, 相信大家最常用的就是pull和push. 但随着协作规模的提升, 遇到的问题也会越来越多. 本篇文章并不科普一些命令的详细用法, 更多的是分享在工作中遇到的Git场景问题以及踩过的 ...
- (二)asyncio的简单使用,python异步高效处理数据,asyncio.get_event_loop(),loop.run_until_complete(main()),loop.close()
Asyncio 是一个基于事件循环的异步I/O框架,它提供了高效的协程实现,能够轻松地编写高并发的Python程序.Asyncio 在 Python 3.4 中首次引入,它的核心是事件循环(Event ...
- 树上点差分的经典应用 LuoguP3258松鼠的新家
树上点差分的核心就是如何避免重复,即正确的运用差分数组 例如a,b点路径上点权值加1,则把a,b路径找到,并找到其LCA,此时可以把a到根,b到根这两条路径看出两条链,把每条链看出我们熟悉的 顺序差分 ...
- 【Oracle】力扣简单的练习题
Oracle力扣简单的练习题 请你编写一个 SQL 查询来交换所有的 'f' 和 'm' /* Write your PL/SQL query statement below */ /******** ...
- ModelScope初探:一行代码调用成熟AI模型
简介: 如何用一行代码调用成熟AI模型?试试ModelScope,让AI开发者解放生产力! ModelScope是阿里推出的下一代开源的模型即服务共享平台,为泛AI开发者提供灵活.易用.低成本的一站式 ...
- WPF 通过 Windows Template Studio 快速搭建项目框架和上手项目
本文对新手友好.在咱开始一个新项目的时候,可以利用 Windows Template Studio 快速搭建整个项目的框架.搭建出来的框架比较现代化,适合想要快速开发一个项目的大佬使用,也适合小白入门 ...