实例讲解Flink 流处理程序编程模型
摘要:在深入了解 Flink 实时数据处理程序的开发之前,先通过一个简单示例来了解使用 Flink 的 DataStream API 构建有状态流应用程序的过程。
本文分享自华为云社区《Flink 实例:Flink 流处理程序编程模型》,作者:TiAmoZhang 。
在深入了解 Flink 实时数据处理程序的开发之前,先通过一个简单示例来了解使用 Flink 的 DataStream API 构建有状态流应用程序的过程。
01、流数据类型
Flink 以一种独特的方式处理数据类型和序列化,它包含自己的类型描述符、泛型类型提取和类型序列化框架。基于 Java 和 Scala 语言,Flink 实现了一套自己的一套类型系统,它支持很多种类的类型,包括
- 基本类型。
- 数组类型。
- 复合类型。
- 辅助类型。
- 通用类型。
详细的 Flink 类型系统如图 1 所示。
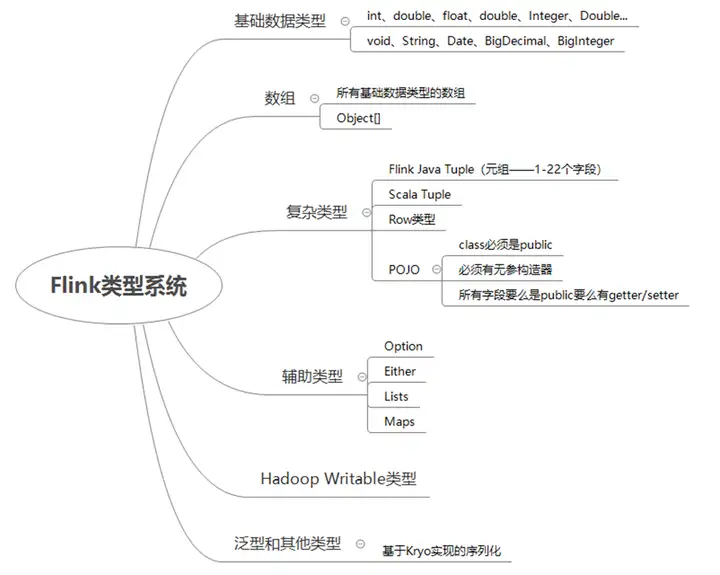
■ 图 1 Flink 类型系统
Flink 针对 Java 和 Scala 的 DataStream API 要求流数据的内容必须是可序列化的。Flink 内置了以下类型数据的序列化器:
- 基本数据类型:String、Long、Integer、Boolean、Array。
- 复合数据类型:Tuple、POJO、Scala case class。
对于其他类型,Flink 会返回 Kryo。也可以在 Flink 中使用其他序列化器。Avro 尤其得到了很好的支持。
1.java DataStream API 使用的流数据类型
对于 Java API,Flink 定义了自己的 Tuple1 到 Tuple25 类型来表示元组类型,代码如下:
Tuple2<String, Integer> person = new Tuple2<>("王老五", 35);
//索引基于0
String name = person.f0;
Integer age = person.f1;
在 Java 中,POJO(plain old Java Object)是这样的 Java 类:
- 有一个无参的默认构造器。
- 所有的字段要么是 public 的,要么有一个默认的 getter 和 setter。
例如,定义一个名为 Person 的 POJO 类,代码如下:
//定义一个Person POJO类public class Person{ public String name; public Integer age;
public Person() {};
public Person(String name, Integer age) { this.name = name; this.age = age; };}
//创建一个实例Person person = new Person("王老五", 35);
2.Scala DataStream API 使用的流数据类型
对于元组,使用 Scala 自己的 Tuple 类型就好,代码如下:
val person = ("王老五", 35)
//索引基于1val name = person._1val age = person._2
对于对象类型,使用 case class(相当于 Java 中的 JavaBean),代码如下:
case class Person(name: String, age:Int)
val person = Person("王老五", 35)
3.Flink 类型系统
对于创建的任意一个 POJO 类型,看起来它是一个普通的 Java Bean,在 Java 中,可以使用 Class 来描述该类型,但其实在 Flink 引擎中,它被描述为 PojoTypeInfo,而 PojoTypeInfo 是 TypeInformation 的子类。
TypeInformation 是 Flink 类型系统的核心类。Flink 使用 TypeInformation 来描述所有 Flink 支持的数据类型,就像 Java 中的 Class 类型一样。每种 Flink 支持的数据类型都对应的是 TypeInformation 的子类。例如 POJO 类型对应的是 PojoTypeInfo、基础数据类型数组对应的是 BasicArrayTypeInfo、Map 类型对应的是 MapTypeInfo、值类型对应的是 ValueTypeInfo。
除了对类型的描述,TypeInformation 还提供了序列化的支持。在 TypeInformation 中有一种方法:createSerializer 方法,它用来创建序列化器,序列化器中定义了一系列的方法,其中,通过 serialize 和 deserialize 方法,可以将指定类型进行序列化,并且 Flink 的这些序列化器会以稠密的方式来将对象写入内存中。Flink 中也提供了非常丰富的序列化器。在我们基于 Flink 类型系统支持的数据类型进行编程时,Flink 在运行时会推断出数据类型的信息,我们在基于 Flink 编程时,几乎是不需要关心类型和序列化的。
4.类型与 Lambda 表达式支持
在编译时,编译器能够从 Java 源代码中读取完整的类型信息,并强制执行类型的约束,但生成 class 字节码时,会将参数化类型信息删除。这就是类型擦除。类型擦除可以确保不会为泛型创建新的 Java 类,泛型是不会产生额外的开销的。也就是说,泛型只是在编译器编译时能够理解该类型,但编译后执行时,泛型是会被擦除掉的。
为了全球说明,请看下面的代码:
public static <T> boolean hasItems(T [] items, T item){ for (T i : items){ if(i.equals(item)){ return true; } } return false;}
以上是一段 Java 的泛型方法,但在编译后,编译器会将未绑定类型的 T 擦除掉,替换为 Object。也就是编译之后的代码如下:
public static Object boolean hasItems(Object [] items, Object item){ for (Object i : items){ if(i.equals(item)){ return true; } } return false;}
泛型只是能够防止在运行时出现类型错误,但运行时会出现以下异常,而且 Flink 以非常友好的方式提示:
could not be determined automatically, due to type erasure. You can give type information hints by using the returns(...) method on the result of the transformation call, or by letting your function implement the 'ResultTypeQueryable' interface.
就是因为 Java 编译器类型擦除的原因,所以 Flink 根本无法推断出来算子(例如 flatMap)要输出的类型是什么,所以在 Flink 中使用 Lambda 表达式时,为了防止因类型擦除而出现运行时错误,需要指定 TypeInformation 或者 TypeHint。
创建 TypeInformation,代码如下:
.returns(TypeInformation.of(String.class))
创建 TypeHint,代码如下:
.returns(new TypeHint<String>() {})
02、流应用程序实现
Flink 程序的基本构建块是 stream 和 transformation(流和转换)。从概念上讲,stream 是数据记录的流(可能永远不会结束),transformation 是一个运算,它接受一个或多个流作为输入,经过处理/计算后生成一个或多个输出流。
下面实现一个完整的、可工作的 Flink 流应用程序示例。
【示例 1】将有关人员的记录流作为输入,并从中筛选出未成年人信息。
Scala 代码如下:
(1) 在 IntelliJ IDEA 中创建一个 Flink 项目,使用 flink-quickstart-scala 项目模板
(2) 设置依赖。在 pom.xml 文件中添加如下依赖内容:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.13.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.13.2</version>
<scope>provided</scope>
</dependency>
(3) 创建主程序 StreamingJobDemo1,编辑流处理代码如下:
import org.apache.flink.streaming.api.scala._
object StreamingJobDemo1 {//定义事件类 case class Person(name:String, age:Integer)
def main(args: Array[String]) {
//设置流执行环境 val env = StreamExecutionEnvironment.getExecutionEnvironment
//读取数据源,构造数据流 val peoples = env.fromElements( Person("张三", 21), Person("李四", 16), Person("王老五", 35) )
//对数据流执行filter转换 val adults = peoples.filter(_.age>18)
//输出结果 adults.print
//执行 env.execute("Flink Streaming Job") }}
执行以上代码,输出结果如下:
7> Person(张三,21)1> Person(王老五,35)
Java 代码如下:
(1) 在 IntelliJ IDEA 中创建一个 Flink 项目,使用 flink-quickstart-Java 项目模板
(2) 设置依赖。在 pom.xml 文件中添加如下依赖内容: <dependency><groupId>org.apache.flink</groupId> <artifactId>flink-Java</artifactId> <version>1.13.2</version> <scope>provided</scope></dependency>dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-Java_2.12</artifactId> <version>1.13.2</version> <scope>provided</scope></dependency>
(3) 创建一个 POJO 类,用来表示流中的数据,代码如下: //POJO类,表示人员信息实体public class Person { public String name; //存储姓名 public Integer age; //存储年龄 //空构造器 public Person() {}; //构造器,初始化属性 public Person(String name, Integer age) { this.name = name; this.age = age; }; //用于调试时输出信息 public String toString() { return this.name.toString() + ": age " + this.age.toString(); };}
(4) 打开项目中的 StreamingJob 对象文件,编辑流处理代码如下: import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.api.common.functions.FilterFunction; public class StreamingJobDemo1 { public static void main(String[] args) throws Exception { //获得流执行环境 final StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment(); //读取数据源,构造DataStream DataStream<Person> personDS = env.fromElements( new Person("张三", 21), new Person("李四", 16), new Person("王老五", 35) ); //执行转换运算(这里是过滤年龄不小于18岁的人)//注意,这里使用了匿名函数 DataStream<Person> adults = personDS.filter(new FilterFunction<Person>() { @Override public boolean filter(Person person) throws Exception { return person.age >= 18; } }); //将结果输出到控制台 adults.print(); //触发流程序开始执行 env.execute("stream demo"); }}
(5) 执行以上程序,输出结果如下。
张三: age 21王老五: age 35
注意
Flink 将批处理程序作为流程序的一种特殊情况执行,其中流是有界的(有限数量的元素)。DataSet 在内部被视为数据流,因此,上述概念同样适用于批处理程序,也适用于流程序,只有少数例外:
- 批处理程序的容错不使用检查点。错误恢复是通过完全重放流实现的,这使恢复的成本更高,但是因为它避免了检查点,所以使常规处理更轻量。
- DataSet API 中的有状态运算使用简化的 in-memory/out-of-核数据结构,而不是 key-value 索引。
- DataSet API 引入了特殊的同步(基于 superstep)迭代,这只可能在有界流上实现。
03、流应用程序剖析
所有的 Flink 应用程序都以特定的步骤来工作,这些工作步骤如图 2 所示。

■ 图 2 Flink 应用程序工作步骤
也就是说,每个 Flink 程序都由相同的基本部分组成:
- 获取一个执行环境。
- 加载/创建初始数据。
- 指定对该数据的转换。
- 指定计算结果放在哪里。
- 触发程序执行。
1.获取一个执行环境
Flink 应用程序从其 main()方法中生成一个或多个 Flink 作业(job)。这些作业可以在本地 JVM(LocalEnvironment)中执行,也可以在具有多台机器的集群的远程设置中执行(RemoteEnvironment)。对于每个程序,ExecutionEnvironment 提供了控制作业执行(例如设置并行性或容错/检查点参数)和与外部环境交互(数据访问)的方法。
每个 Flink 应用程序都需要一个执行环境(本例中为 env)。流应用程序需要的执行环境使用的是 StreamExecutionEnvironment。为了开始编写 Flink 程序,用户首先需要获得一个现有的执行环境,如果没有,就需要先创建一个。根据目的不同,Flink 支持以下几种方式:
- 获得一个已经存在的 Flink 环境。
- 创建本地环境。
- 创建远程环境。
Flink 流程序的入口点是 StreamExecutionEnvironment 类的一个实例,它定义了程序执行的上下文。StreamExecutionEnvironment 是所有 Flink 程序的基础。可以通过一些静态方法获得一个 StreamExecutionEnvironment 的实例,代码如下:
StreamExecutionEnvironment.getExecutionEnvironment()StreamExecutionEnvironment.createLocalEnvironment()StreamExecutionEnvironment.createRemoteEnvironment(String host, int port, String... jarFiles)
要获得执行环境,通常只需调用 getExecutionEnvironment()方法。这将根据上下文选择正确的执行环境。如果正在 IDE 中的本地环境上执行,则它将启动一个本地执行环境。如果是从程序中创建了一个 JAR 文件,并通过命令行调用它,则 Flink 集群管理器将执行 main()方法,getExecutionEnvironment()将返回用于在集群上以分布式方式执行程序的执行环境。
在上面的示例程序中,使用以下语句来获得流程序的执行环境。
Scala 代码如下:
//设置流执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment
Java 代码如下:
//获得流执行环境final StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
StreamExecutionEnvironment 包含 ExecutionConfig,可使用它为运行时设置特定于作业的配置值。例如,如果要设置自动水印发送间隔,可以像下面这样在代码进行配置。
Scala 代码如下:
val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.getConfig.setAutoWatermarkInterval(long milliseconds)
Java 代码如下:
final StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.getConfig().setAutoWatermarkInterval(long milliseconds);
2.加载/创建初始数据
执行环境可以从多种数据源读取数据,包括文本文件、CSV 文件、Socket 套接字数据等,也可以使用自定义的数据输入格式。例如,要将文本文件读取为行序列,代码如下:
final StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> text = env.readTextFile("file://path/to/file");
数据被逐行读取内存后,Flink 会将它们组织到 DataStream 中,这是 Flink 中用来表示流数据的特殊类。
在示例程序【示例 1】中,使用 fromElements()方法读取集合数据,并将读取的数据存储为 DataStream 类型。
Scala 代码如下:
//读取数据源,构造数据流val personDS = env.fromElements( Person("张三", 21), Person("李四", 16), Person("王老五", 35) )
Java 代码如下:
//读取数据源,构造DataStreamDataStream<Person> personDS = env.fromElements( new Person("张三", 21), new Person("李四", 16), new Person("王老五", 35));
3.对数据进行转换
每个 Flink 程序都对分布式数据集合执行转换。Flink 的 DataStream API 提供了多种数据转换功能,包括过滤、映射、连接、分组和聚合。例如,下面是一个 map 转换应用,通过将原始集合中的每个字符串转换为整数来创建一个新的 DataStream,代码如下:
在示例程序【示例 1】中使用了 filter 过滤转换,将原始数据集转换为只包含成年人信息的新 DataStream 流,代码如下:
DataStream<String> input = env.fromElements("12","3","25","5","32","6");
DataStream<Integer> parsed = input.map(new MapFunction<String, Integer>() { @Override public Integer map(String value) { return Integer.parseInt(value); }});
Scala 代码如下:
//对数据流执行filter转换val adults = personDS.filter(_.age>18)
Java 代码如下:
//对数据流执行filter转换DataStream<Person> adults = flintstones.filter( new FilterFunction<Person>() { @Override public boolean filter(Person person) throws Exception { return person.age >= 18; } });
这里不必了解每个转换的具体含义,后面我们会详细介绍它们。需要强调的是,Flink 中的转换是惰性的,在调用 sink 操作之前不会真正执行。
4.指定计算结果放在哪里
一旦有了包含最终结果的 DataStream,就可以通过创建接收器(sink)将其写入外部系统。例如,将计算结果打印输出到屏幕上。
Scala 代码如下:
//输出结果adults.print
Java 代码如下:
//输出结果adults.print();
Flink 中的接收器(sink)操作触发流的执行,以生成程序所需的结果,例如将结果保存到文件系统或将其打印到标准输出。上面的示例使用 adults.print()将结果打印到任务管理器日志中(在 IDE 中运行时,任务管理器日志将显示在 IDE 的控制台中)。这将对流的每个元素调用其 toString()方法。
5.触发流程序执行
一旦写好了程序处理逻辑,就需要通过调用 StreamExecutionEnvironment 上的 execute()来触发程序执行。所有的 Flink 程序都是延迟执行的:当程序的主方法执行时,数据加载和转换不会直接发生,而是创建每个运算并添加到程序的执行计划中。当执行环境上的 execute()调用显式触发执行时,这些操作才实际上被执行。程序是在本地执行还是提交到集群中执行取决于 ExecutionEnvironment 的类型。
延迟计算可以让用户构建复杂的程序,然后 Flink 将其作为一个整体计划的单元执行。在示例程序【示例 1】中,使用如下代码来触发流处理程序的执行。
Scala 代码如下:
//触发流程序执行env.execute("Flink Streaming Job") //参数是程序名称,会显示在Web UI界面上
Java 代码如下:
//触发流程序执行env.execute("Flink Streaming Job"); //参数是程序名称,会显示在Web UI界面上
在应用程序中执行的 DataStream API 调用将构建一个附加到 StreamExecutionEnvironment 的作业图(Job Graph)。调用 env.execute()时,此图被打包并发送到 Flink Master,该 Master 并行化作业并将其片段分发给 TaskManagers 以供执行。作业的每个并行片段将在一个 task slot(任务槽)中执行,如图 3 所示。
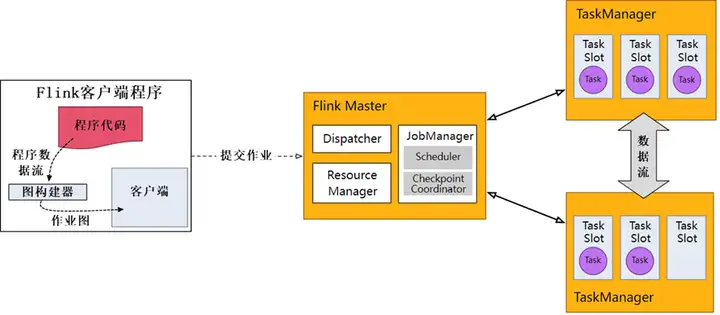
■图 3 Flink 流应用程序执行原理
这个分布式运行时要求 Flink 应用程序是可序列化的。它还要求集群中的每个节点都可以使用所有依赖项。
StreamExecutionEnvironment 上的 execute()方法将等待作业完成,然后返回一个 JobExecutionResult,其中包含执行时间和累加器结果。注意,如果不调用 execute(),应用程序将不会运行。
如果不想等待作业完成,可以通过调用 StreamExecutionEnvironment 上的 executeAysnc()来触发异步作业执行。它将返回一个 JobClient,可以使用它与刚才提交的作业进行通信。例如,下面的示例代码演示了如何通过 executeAsync()实现 execute()的语义。
Scala 代码如下:
val jobClient = evn.executeAsyncval jobExecutionResult =jobClient.getJobExecutionResult(userClassloader).get
Java 代码如下:
final JobClient jobClient = env.executeAsync();final JobExecutionResult jobExecutionResult =jobClient.getJobExecutionResult(
实例讲解Flink 流处理程序编程模型的更多相关文章
- [Note] Apache Flink 的数据流编程模型
Apache Flink 的数据流编程模型 抽象层次 Flink 为开发流式应用和批式应用设计了不同的抽象层次 状态化的流 抽象层次的最底层是状态化的流,它通过 ProcessFunction 嵌入到 ...
- 再也不担心写出臃肿的Flink流处理程序啦,发现一款将Flink与Spring生态完美融合的脚手架工程-懒松鼠Flink-Boot
目录 你可能面临如下苦恼: 接口缓存 重试机制 Bean校验 等等...... 它为流计算开发工程师解决了 有了它你的代码就像这样子: 仓库地址:懒松鼠Flink-Boot 1. 组织结构 2. 技术 ...
- 第03讲:Flink 的编程模型与其他框架比较
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 本课时我们主要介绍 ...
- 【大数据面试】Flink 01 概述:包含内容、层次架构、运行组件、部署模式、任务提交流程、任务调度概念、编程模型组成
一.概述 1.介绍 对无界和有界数据流进行有状态计算的分布式引擎和框架,并可以使用高层API编写分布式任务,主要包括: DataSet API(批处理):静态数据抽象为分布式数据集,方便使用操作符进行 ...
- Storm集群组件和编程模型
Storm工作原理: Storm是一个开源的分布式实时计算系统,常被称为流式计算框架.什么是流式计算呢?通俗来讲,流式计算顾名思义:数据流源源不断的来,一边来,一边计算结果,再进入下一个流. 比 ...
- Apache Flink 数据流编程模型
抽象等级(Levels of Abstraction) Flink提供不同级别的抽象来开发流/批处理应用程序. Statefule Stream Processing: 是最低级别(底层)的抽象,只提 ...
- flink原理介绍-数据流编程模型v1.4
数据流编程模型 抽象级别 程序和数据流 并行数据流 窗口 时间 有状态操作 检查点(checkpoint)容错 批量流处理 下一步 抽象级别 flink针对 流式/批处理 应用提供了不同的抽象级别. ...
- 分布式流处理框架 Apache Storm —— 编程模型详解
一.简介 二.IComponent接口 三.Spout 3.1 ISpout接口 3.2 BaseRichSpout抽象类 四.Bolt 4.1 IBolt 接口 4. ...
- Flink入门(四)——编程模型
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性.高吞吐.低延迟等优势,本文简述flink的编程模型. 数据集类型: 无穷数据集:无穷的持续集成的数据集合 有界数据集:有 ...
- ARIMA模型实例讲解——网络流量预测可以使用啊
ARIMA模型实例讲解:时间序列预测需要多少历史数据? from:https://www.leiphone.com/news/201704/6zgOPEjmlvMpfvaB.html 雷锋网按:本 ...
随机推荐
- jmeter常用的命令行及参数
一.运行方式分类 GUI方式:图形界面方式运行 CLI方式:command line命令行,jmeter的脚本可以通过命令行用命令进行执行 二.用命令行执行的优势: 1.图形化界面运行的时候会占用很大 ...
- InnoDB Buffer Pool改进LRU页面置换
由于硬盘和内存的造价差异,一台主机实例的硬盘容量通常会远超于内存容量.对于数据库等应用而言,为了保证更快的查询效率,通常会将使用过的数据放在内存中进行加速读取. 数据页与索引页的LRU 数据页和索引页 ...
- Django笔记十二之defer、only指定返回字段
本篇笔记为Django笔记系列之十二,首发于公号[Django笔记] 本篇笔记将介绍查询中的 defer 和 only 两个函数的用法,笔记目录如下: defer only 1.defer defer ...
- 从头开始,手写android应用框架(一)
前言 搭建android项目框架前,我们需要先定义要框架的结构,因为android框架本身的结构就很复杂,如果一开始没定义好结构,那么后续的使用就会事倍功半. 结构如下: com.kiba.frame ...
- 深入理解 python 虚拟机:令人拍案叫绝的字节码设计
深入理解 python 虚拟机:令人拍案叫绝的字节码设计 在本篇文章当中主要给大家介绍 cpython 虚拟机对于字节码的设计以及在调试过程当中一个比较重要的字段 co_lnotab 的设计原理! p ...
- [Windows]解决:windows连接远程桌面-出现身份验证错误,要求的函数不受支持( CredSSP加密数据库修正)[转载]
文由 需要在本地Windows系统电脑通过远程桌面(mstsc)另一台Windows服务器,将其内的数据拷贝过来.但却发生了这样的异常 解决方案 step1 Win+R step2 打开注册表: gp ...
- .NET快速开发框架-RDIFramework.NET 全新EasyUI版发布
RDIFramework.NET,基于.NET的快速信息化系统快速开发框架.10年专注.易上手.多组件.全源码.可灵活构建各类型系统. 1.RDIFramework.NET快速开发框架简介 RDIFr ...
- Docker 配置阿里云或腾讯云镜像加速
1.新建 /etc/docker/daemon.json 文件,并写入以下内容: 阿里云按下面配置 sudo tee /etc/docker/daemon.json <<-'EOF' { ...
- [操作系统] - 进程状态&进程描述
2.1 进程(Process) 2.1.1 定义 chatGPT版:一个具有独立功能的程序关于某个数据集合的一次运行活动 人话版:程序在并发环境中的执行过程& 进程是程序的一次执行 2.1.2 ...
- JVM有意思的图-持续更新
放一些JVM有意思的图 通过一行代码联想JVM: