【GUI软件】抖音搜索结果批量采集,支持多个关键词、排序方式、发布时间筛选等!
一、背景介绍
1.1 爬取目标
您好!我是@马哥python说,一名10年程序猿。
我用python开发了一个爬虫采集软件,可自动按关键词抓取抖音视频数据。
为什么有了源码还开发界面软件呢?方便不懂编程代码的小白用户使用,无需安装python,无需改代码,双击打开即用!
软件界面截图:

爬取结果截图:
结果截图1:
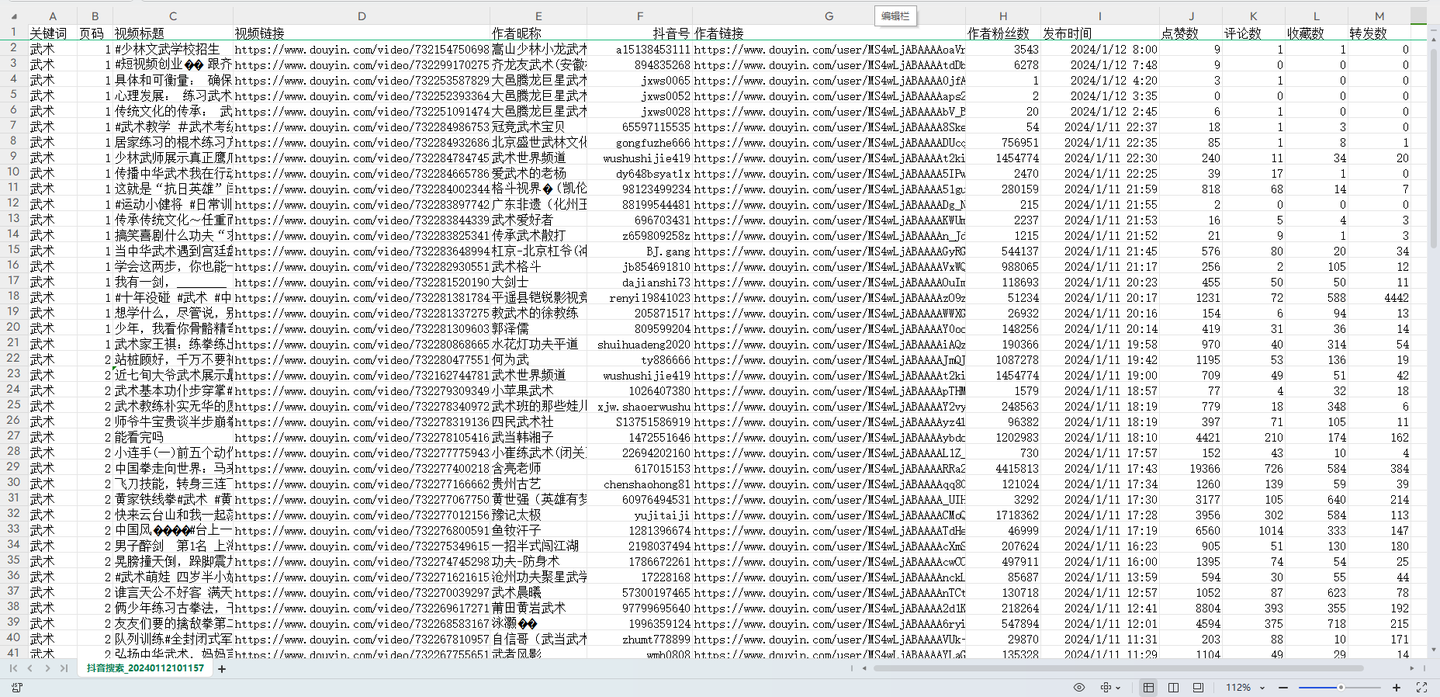
结果截图2:
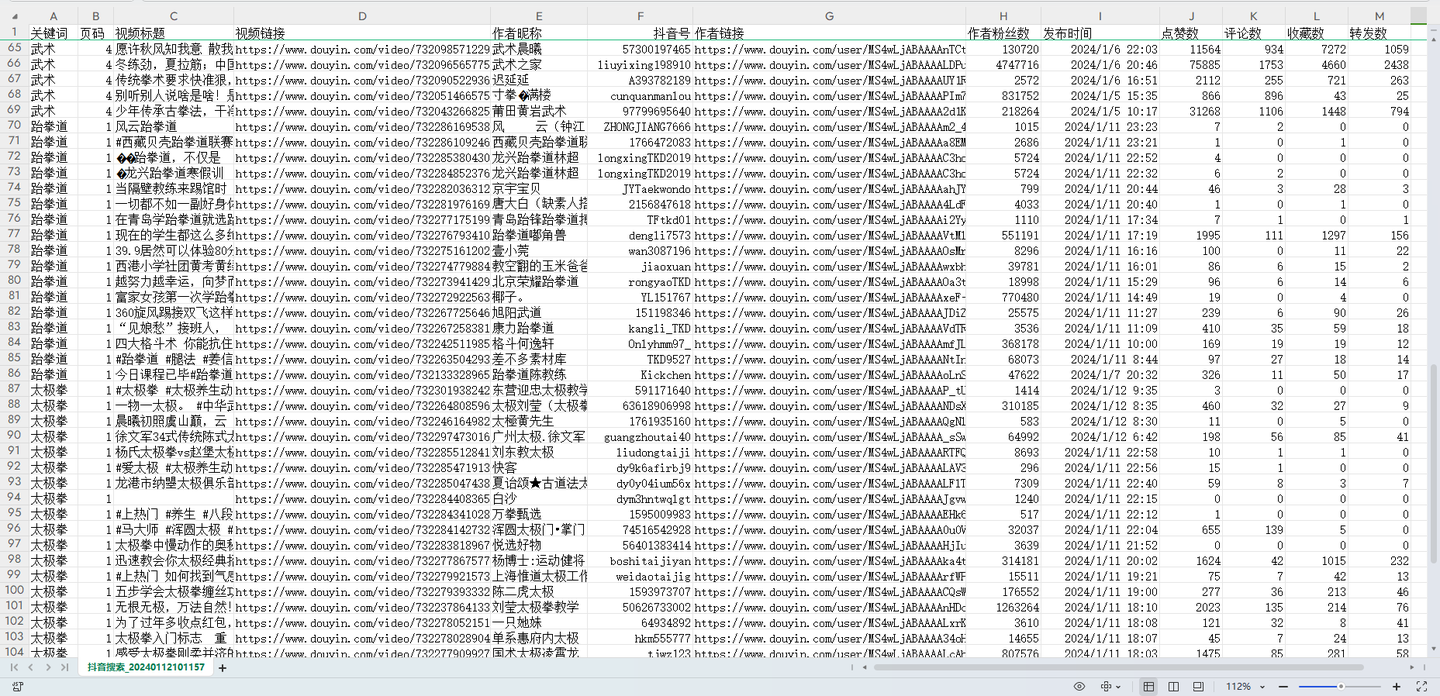
结果截图3:
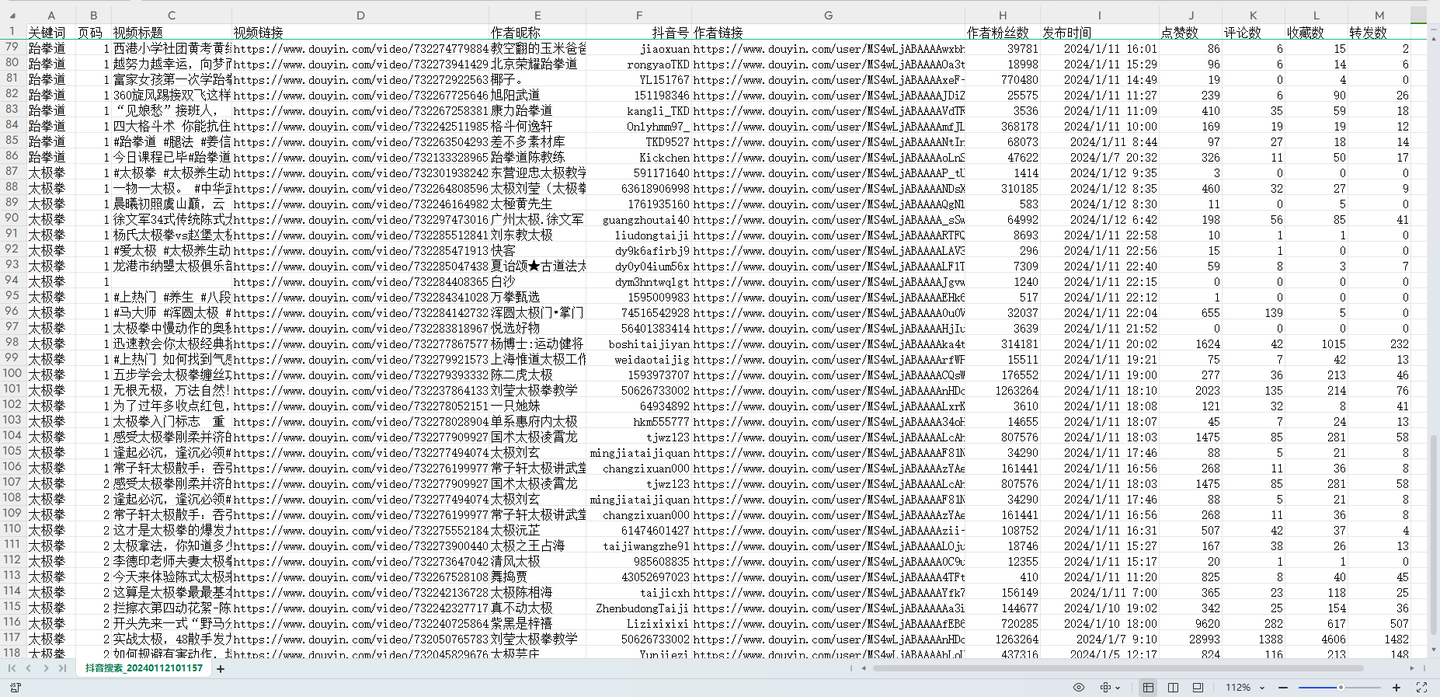
以上。
1.2 演示视频
软件使用演示:
【软件演示】抖音搜索采集工具,支持多个关键词、排序方式、发布时间等
1.3 软件说明
几点重要说明:
- Windows用户可直接双击打开使用,无需Python运行环境,非常方便!
- 需要填入个人cookie和目标视频链接
- 支持筛选:排序方式(综合排序/最新发布/最多点赞)和发布时间(不限/一天内/一周内/半年内)
- 支持同时爬多个关键词
- 爬取过程中,有log文件详细记录运行过程,方便回溯
- 爬取完成后,自动导出结果到csv文件
- 可爬13个字段,含:关键词,页码,视频标题,视频链接,作者昵称,抖音号,作者链接,作者粉丝数,发布时间,点赞数,评论数,收藏数,转发数。
以上。
二、代码讲解
2.1 爬虫采集模块
首先,定义接口地址作为请求地址:
# 请求地址
url = 'https://www.douyin.com/aweme/v1/web/search/item/'
定义一个请求头,用于伪造浏览器:
# 请求头
h1 = {
"Accept": 'application/json, text/plain, */*',
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Cookie": self.cookie_val,
"Referer": "",
"Sec-Ch-Ua": 'Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": "Windows",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
说明一下,cookie是个关键参数。
cookie的获取方法,如下:
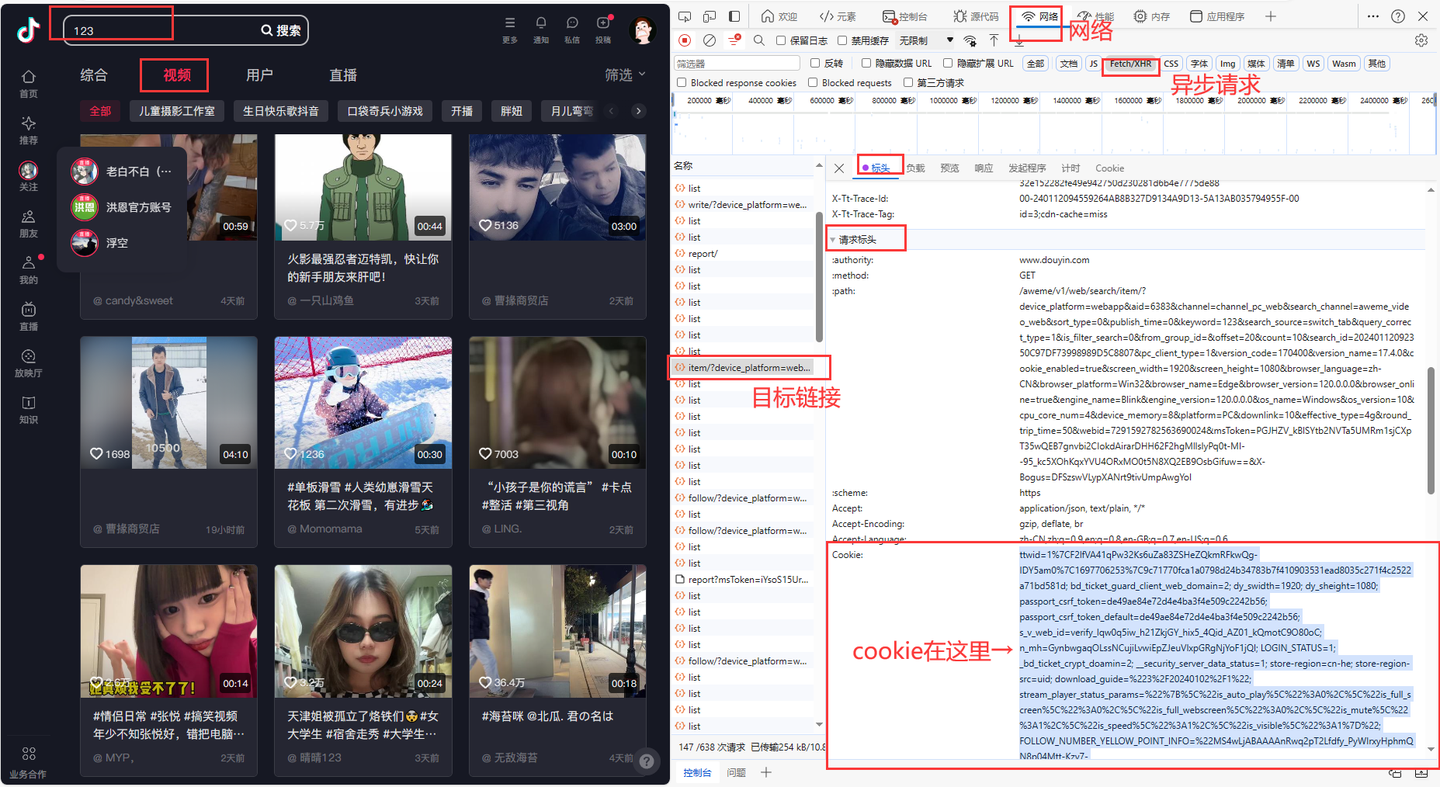
这个值非常重要,软件界面需要填写!!
加上请求参数,告诉程序你的爬取条件是什么:
# 请求参数
params = {
"device_platform": "webapp",
"aid": "6383",
"channel": "channel_pc_web",
"search_channel": "aweme_video_web",
"sort_type": self.trans_sort_type(v_str=self.sort_type),
"publish_time": self.trans_time_range(v_str=self.time_range),
"keyword": search_keyword,
"search_source": "tab_search",
"query_correct_type": "1",
"is_filter_search": "1",
"from_group_id": "",
"offset": cursor,
"count": "20",
"pc_client_type": "1",
"version_code": "170400",
"version_name": "17.4.0",
"cookie_enabled": "true",
"screen_width": "1536",
"screen_height": "864",
"browser_language": "zh-CN",
"browser_platform": "Win32",
"browser_name": "Chrome",
"browser_version": "120.0.0.0",
"browser_online": "true",
"engine_name": "Blink",
"engine_version": "120.0.0.0",
"os_name": "Windows",
"os_version": "10",
"cpu_core_num": "8",
"device_memory": "8",
"platform": "PC",
"downlink": "10",
"effective_type": "4g",
"round_trip_time": "50",
"webid": "7249265465250973217",
"msToken": "Sx2PzLIz0YGvM_wrIkaUaaeUb1JUutgo3ERiWmwV1w6VC1naW15lFM6N3nanMZRZYfaHLvXrDNzGqkAyvvCpdO3d6u0u_kNmmZZHeMIsDqga2eWnjTzp5g==",
"X-Bogus": "DFSzswVuketAN9oEt7PfdSlls7YT"
}
下面就是发送请求和接收数据:
# 发送请求
r = requests.get(url, headers=h1, params=params)
print(r.status_code)
# 以json格式接收返回数据
json_data = r.json()
定义一些空列表,用于存放解析后字段数据:
# 定义空列表
title_list = [] # 视频标题
link_list = [] # 视频链接
author_name_list = [] # 作者昵称
author_id_list = [] # 抖音号
author_link_list = [] # 作者链接
follower_count_list = [] # 作者粉丝数
create_time_list = [] # 发布时间
like_count_list = [] # 点赞数
comment_count_list = [] # 评论数
collect_count_list = [] # 收藏数
share_count_list = [] # 转发数
循环解析字段数据,以"视频标题"为例:
for v in video_list:
# 视频标题
title = v['aweme_info']['desc']
self.tk_show('视频标题:' + title)
title_list.append(title)
其他字段同理,不再赘述。
最后,是把数据保存到csv文件:
# 保存数据到DF
df = pd.DataFrame(
{
'关键词': search_keyword,
'页码': page,
'视频标题': title_list,
'视频链接': link_list,
'作者昵称': author_name_list,
'抖音号': author_id_list,
'作者链接': author_link_list,
'作者粉丝数': follower_count_list,
'发布时间': create_time_list,
'点赞数': like_count_list,
'评论数': comment_count_list,
'收藏数': collect_count_list,
'转发数': share_count_list,
}
)
if os.path.exists(self.result_file): # 如果文件存在,不再设置表头
header = False
else: # 否则,设置csv文件表头
header = True
df.to_csv(self.result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
self.tk_show('保存csv文件成功:' + self.result_file)
完整代码中,还含有:判断循环结束条件、排序方式(综合排序/最新发布/最多点赞)、发布时间(不限/一天内/一周内/半年内)等关键实现逻辑。
2.2 软件界面模块
主窗口部分:
# 创建主窗口
root = tk.Tk()
root.title('抖音搜索采集软件v1.1 | 马哥python说 |')
# 设置窗口大小
root.minsize(width=850, height=650)
输入控件部分:
# 搜索关键词
tk.Label(root, justify='left', text='搜索关键词:').place(x=30, y=160)
entry_kw = tk.Text(root, bg='#ffffff', width=60, height=2, )
entry_kw.place(x=125, y=160, anchor='nw') # 摆放位置
底部版权部分:
# 版权信息
copyright = tk.Label(root, text='@马哥python说 All rights reserved.', font=('仿宋', 10), fg='grey')
copyright.place(x=290, y=625)
以上。
2.3 日志模块
好的日志功能,方便软件运行出问题后快速定位原因,修复bug。
核心代码:
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日志格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日志级别
self.logger.setLevel(logging.DEBUG)
# 控制台日志
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日志文件名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
# 将其保存到特定目录,ap方法就是寻找项目根目录,该方法博主前期已经写好。
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')
日志文件截图:

以上。
三、获取源码及软件
完整python源码及exe软件,微信公众号"老男孩的平凡之路"后台回复"爬抖音搜索软件"即可获取。点击直达
推荐阅读:【GUI界面软件】抖音评论采集:自动采集10000多条,含二级评论、展开评论!
【GUI软件】抖音搜索结果批量采集,支持多个关键词、排序方式、发布时间筛选等!的更多相关文章
- Python爬虫---爬取抖音短视频
目录 前言 抖音爬虫制作 选定网页 分析网页 提取id构造网址 拼接数据包链接 获取视频地址 下载视频 全部代码 实现结果 待解决的问题 前言 最近一直想要写一个抖音爬虫来批量下载抖音的短视频,但是经 ...
- E4A写的app,点按钮,直接进入抖音指定用户界面
今天在网上看到有一个人,直接进抖音某个指定用户的界面,一般模拟的方式,要先通过搜索的方式,再选用户,点进去 但是这样操作,不大友好,也影响速度 最理想的方式,是通过 "无障碍",直接控制抖音进入指定的 ...
- 视频剪辑软件调研:Adobe Premiere、会声会影、抖音短视频
Adobe Premiere.会声会影.抖音短视频基本功能特点对比: 特点 Adobe Premiere 会声会影 抖音短视频 运行平台 Win7/Win8/Win10.macOS Win7/Win ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- 今日头条、抖音、西瓜、火山、微视、陌陌等自媒体平台小视频批量下载工具v1.1.0(视频搬运福利)
前言 目前各大自媒体平台爆火,网络流量暴涨,各大自媒体平台的小视频为广大个广告主带来了如泉涌般的的视频流量,更给广大的自媒体小编带来了丰厚的利益回报,想要创做更多的自媒体内容着实不易,下面给广大的小视 ...
- 教你用 Python 实现抖音热门表白软件
之前在群里看到有人发了一个抖音上很火的小视频,就是一个不正经的软件,运行后问你是不是愿意做我的朋友,但你没法点击到「不同意」!并且没办法直接关闭窗口! 很不正经,很流氓,有点适合我. 效果大概是这样的 ...
- Puppeteer自动化批量上传抖音视频
前言:最近因为项目宣传,所以用Puppeteer写了一个批量上传抖音视频的自动化程序用于推广. 环境和依赖:node,puppeteer 废话不多说,直接上代码: const puppeteer =r ...
- Python实现抖音关键词热度搜索小程序(附源码)
今天给大家带来一个抖音热词小程序,废话不多说,直接上代码 import requests import json import urllib.parse import time ''' python知 ...
- 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
抖音很火,楼主使用python随机爬取抖音视频,并且无水印下载,人家都说天下没有爬不到的数据,so,楼主决定试试水,纯属技术爱好,分享给大家.. 1.楼主首先使用Fiddler4来抓取手机抖音app这 ...
- 抖音短视频爆火的背后到底是什么——如何快速的开发一个完整的直播app
前言 今年移动直播行业的兴起,诞生了一大批网红,甚至明星也开始直播了,因此不得不跟上时代的步伐,由于第一次接触的原因,因此花了很多时间了解直播,今天我来教你从零开始搭建一个完整的直播app,希望能帮助 ...
随机推荐
- parameter常数及常数函数的使用
模型功能 常数在verilog设计中具备特殊的含义 一个可以由编译器进行处理的数 和C语言中常数一个不变的变量的作用不同 在verilog中,常数更多地作为预编译变量以提高设计的灵活性 在上一篇文章中 ...
- 改Bug的经验
如果修复某个Bug花了很长时间,这时候就要问问自己为什么,怎么做才吸取经验教训,在类似的问题上不再出问题,以及采用的方法,使用的工具是否还有改进的地方: 当所有问题都解决之后,一定要梳理下从最初找Bu ...
- MySQL联结
创建联结 mysql> SELECT vend_name,prod_name,prod_price FROM vendors,products WHERE vendors.vend_id=pro ...
- #树状数组,并查集#CF920F SUM and REPLACE
题目 分析 由于\(a_i=1或2\)时\(d(a_i)=a_i\),且其余情况修改后答案只会越来越小, 考虑用树状数组维护区间和,用并查集跳过\(a_i=1或2\)的情况 代码 #include & ...
- #组合计数,容斥定理#U136346 数星星
题目 天上的繁星一闪一闪的,甚是好看.你和你的小伙伴们一起坐在草地上,欣赏这美丽的夜景. 我们假定天上有\(n\)颗星星,它们排成一排,从左往右以此编号为1到\(n\),但是天上的星星实在太多了,你和 ...
- webpack 4 快速搭建
安装 npm install --save-dev webpack@4.30.0 webpack-cli@3.3.2 更新 package.json 脚本 "scripts": { ...
- 深入探讨Java面试中内存泄漏:如何识别、预防和解决
引言 在编写和维护Java应用程序时,内存泄漏是一个重要的问题,可能导致性能下降和不稳定性.本文将介绍内存泄漏的概念,为什么它在Java应用程序中如此重要,并明确本文的目标,即识别.预防和解决内存泄漏 ...
- C# Break 和 Continue 语句以及数组详解
C# Break 它被用于"跳出" switch 语句. break 语句也可用于跳出循环. 以下示例在 i 等于 4 时跳出循环: 示例: for (int i = 0; i & ...
- 定时运行BAT文件
引用:https://www.cnblogs.com/lidj/archive/2012/07/07/2580598.html 1.Form.cs: using CC=System.Web.Mail; ...
- C++调用Python-3:调用Python函数,返回字符串
# mytest.pydef hello1(): print("this is test python print hello world 1") return "456 ...