13_数据的划分和介绍之sklearn数据集
1.数据集是如何划分?训练数据和评估数据不能使用相同数据,不然自己测自己,会使得准确率虚高,在遇到陌生数据时,不够准确。
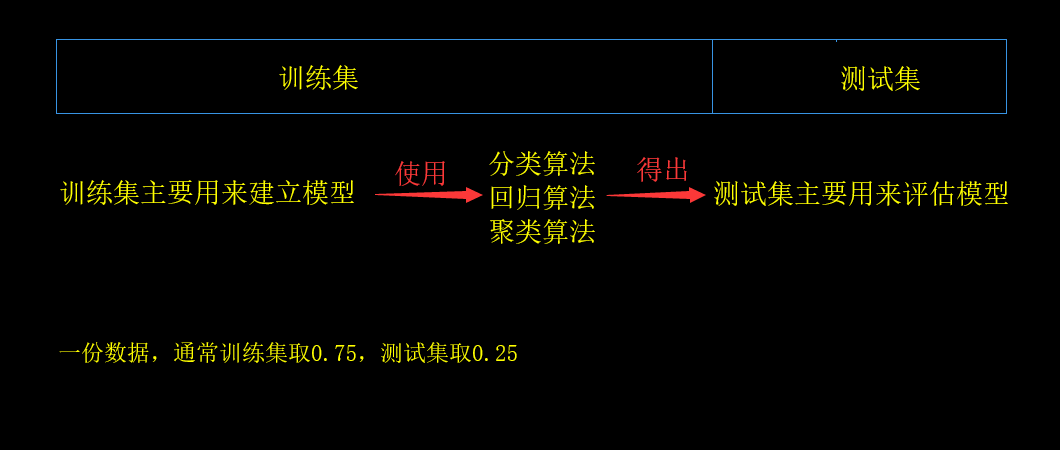
2.数据集的获取: 通过load或者fetch方法。
3.数据集进行分割:

训练集的数据分为特征值和目标值,测试集的数据也分为特征值和目标值,训练集中的x_test、测试集中的y_test、训练集中的x_train、测试集中的y_train。
训练集:x_train,y_train,分别表示训练集里面的特征值、目标值
测试集:x_test,y_test,分别表示测试集里面的特征值、目标值
注意返回格式:x_train , x_test, y_train , y_test = train_test_split(li.data,li.target,test_size=0.25)
print("训练集的特征值和目标值",x_train,y_train)
print("测试集的特征值和目标值",y_test,y_test)
案例1:鸢尾花(分类数据集,数据离散)
# 鸢尾花
from sklearn.datasets import load_iris li = load_iris()
# 获取特征值
print(li.data)
# 获取目标值
print(li.target)
# 获取描述
print(li.DESCR)
获取描述信息:鸢尾花的属性,类别(属于那种鸢尾花)

鸢尾花的训练值和测试集
# 鸢尾花
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
li = load_iris()
# # 获取特征值
# print(li.data)
# # 获取目标值
# print(li.target)
# # 获取描述
# print(li.DESCR)
# # 数据集进行分割 # 注意返回值,训练集train x_train,y_train 测试集 test x_test,y_test
x_train , x_test, y_train , y_test = train_test_split(li.data,li.target,test_size=0.25) print("训练集的特征值和目标值",x_train,y_train)
print("测试集的特征值和目标值",y_test,y_test)
案例2:新闻组类别(分类数据集,数据离散)
subset='all':表示既获取训练数据,又获取测试数据。
from sklearn.datasets import fetch_20newsgroups
news = fetch_20newsgroups(subset='all')
print(news.data)
print(news.target)
注:fetch_20newsgroups,会从网上下载大约14MB的数据集
案例3:波士顿房价(回归数据集,数据连续)
from sklearn.datasets import load_boston lb = load_boston()
print("获取特征值")
print(lb.data)
print("获取目标值")
print(lb.target)
print("获取描述信息")
print(lb.DESCR)

13_数据的划分和介绍之sklearn数据集的更多相关文章
- (数据科学学习手札27)sklearn数据集分割方法汇总
一.简介 在现实的机器学习任务中,我们往往是利用搜集到的尽可能多的样本集来输入算法进行训练,以尽可能高的精度为目标,但这里便出现一个问题,一是很多情况下我们不能说搜集到的样本集就能代表真实的全体,其分 ...
- (数据科学学习手札21)sklearn.datasets常用功能详解
作为Python中经典的机器学习模块,sklearn围绕着机器学习提供了很多可直接调用的机器学习算法以及很多经典的数据集,本文就对sklearn中专门用来得到已有或自定义数据集的datasets模块进 ...
- JVM 运行时数据区域划分
目录 前言 什么是JVM JRE/JDK/JVM是什么关系 JVM执行程序的过程 JVM的生命周期 JVM垃圾回收 JVM的内存区域划分 一.运行时数据区包括哪几部分? 二.运行时数据区的每部分到底存 ...
- sklearn数据集划分
sklearn数据集划分方法有如下方法: KFold,GroupKFold,StratifiedKFold,LeaveOneGroupOut,LeavePGroupsOut,LeaveOneOut,L ...
- [转,讲的非常精彩]CIDR地址块及其子网划分(内含原始IP地址分类及其子网划分的介绍)
http://blog.csdn.net/dan15188387481/article/details/49873923 CIDR地址块及其子网划分(内含原始IP地址分类及其子网划分的介绍) 1. ...
- 转 Nmon 监控生成数据文件字段的介绍
##发现nomon 一个好用的功能 数据透视图 PIVOTCHART:这些参数被用来构建数据透视图.所需的参数:Sheetname,PageField,rowfield,columnfield,Dat ...
- 大数据和Hadoop平台介绍
大数据和Hadoop平台介绍 定义 大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获.管理和处理的数据集.这些困难包括数据的收入.存储.搜索.共享.分析和 ...
- 【学习笔记】sklearn数据集与估计器
数据集划分 机器学习一般的数据集会划分为两个部分: 训练数据:用于训练,构建模型 测试数据:在模型检验时使用,用于评估模型是否有效 训练数据和测试数据常用的比例一般为:70%: 30%, 80%: 2 ...
- SKLearn数据集API(一)
注:本文是人工智能研究网的学习笔记 数据集一览 类型 获取方式 自带的小数据集 sklearn.datasets.load_ 在线下载的数据集 sklearn.datasets.fetch_ 计算机生 ...
随机推荐
- 2019-9-11-在-P2P-文件分享应用以文件或文件段为单位的优缺
title author date CreateTime categories 在 P2P 文件分享应用以文件或文件段为单位的优缺 lindexi 2019-09-11 10:23:27 +0800 ...
- SPN扫描利用
一.利用环境: 在内网渗透的信息收集中,机器服务探测一般都是通过端口扫描去做的,但是有些环境不允许这些操作.通过利用 SPN 扫描可快速定位开启了关键服务的机器,这样就不需要去扫对应服务的端口,有效规 ...
- c++11 Thread库写多线程程序
一个简单的使用线程的Demo c++11提供了一个新的头文件<thread>提供了对线程函数的支持的声明(其他数据保护相关的声明放在其他的头文件中,暂时先从thread头文件入手吧),写一 ...
- mysql出现You can’t specify target table for update in FROM clause
在mysql执行下面语句时报错: You can’t specify target table for update in FROM clause UPDATE edu_grade_hgm_1 ' W ...
- jq给页面添加覆盖层遮罩的实例
先引入jq代码,然后代码如下: $(function(){ var docHeight = $(document).height(); //获取窗口高度 $('body').append('<d ...
- Html标签学习笔记二
1.常用标签 <a></a>超链接 功能 做链接 :在href属性里面写明指向的地方 做下载:href指向文件(注意:不能下载的文件是因为浏览器可以直 ...
- SpringBoot生产/开发/测试多环境的选择
多环境选择 一般一套程序会被运行在多部不同的环境中,比如开发.测试.生产环境,每个环境的数据库地址,服务器端口这些都不经相同,若因为环境的变动而去改变配置的的参数,明显是不合理且易造成错误的 对于不同 ...
- RocketMQ源码分析之从官方示例窥探:RocketMQ事务消息实现基本思想
摘要: RocketMQ源码分析之从官方示例窥探RocketMQ事务消息实现基本思想. 在阅读本文前,若您对RocketMQ技术感兴趣,请加入RocketMQ技术交流群 RocketMQ4.3.0版本 ...
- 1003CSP-S模拟测试赛后总结
我是垃圾……我只会骗分. 拿到题目通读一遍,感觉T3(暴力)是个树剖+线段树. 刚学了树刨我这个兴奋啊.然而手懒决定最后再说. 对着T1一顿yyxjb码了个60pts的测试点分治就失去梦想了.(顺便围 ...
- golang中time包的使用
一.代码 package main; import ( "time" "fmt" ) func main() { //time.Time代表一个纳秒精度的时间点 ...