Pandas使用细则
本文介绍pandas的使用,总结了我在机器学习过程中常使用到的一些方法等。
#pandas学习
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# 设置pandas显示全部行和列,特征较多时使用比较好
pd.set_option('display.max_columns',None)
# pd.set_option('display.max_rows',None)# 这个一般感觉不需要
1,创建数据
1.1 创建一个DataFrame,DataFrame为pandas的数据容器,其实就是数组加上了列名、索引名等。
# 参数data,columns,index
# 方式1
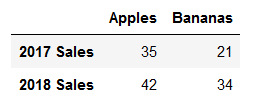
fruit_sales = pd.DataFrame([[35, 21],[41,34]], columns=['Apples', 'Bananas'],index=['2017 Sales','2018 Sales'])
fruit_sales # 方式2
fruit_sales2 = pd.DataFrame({'Apples':[35,42],'Bananas':[21,34]},index=['2017 Sales','2018 Sales'])
fruit_sales2
以上2种方式结果都一样:
如果不指定index和columns,自动以数字赋值:

1.2,Series。DataFrame是表示多行多列的,其中每一行或每一列都是一个Series。
#Series,只能表示一列数据,多列还是用DataFrame
items=['apple','banana','orange']
nums=[10,12,34]
fruit2 = pd.Series(nums, index=items, name='fruit')
fruit2
结果为:

2,读取/存储为csv文件,这里以kaggle中Titanic项目训练数据为示例。
train_data=pd.read_csv('train.csv',index_col=0)# 读取
train_data.to_csv('train_data.csv')# 存储
此方法常见参数如下:
filepath_or_buffer:文件目录地址
index_col:以哪一列作为index
skiprows:跳过开头多少行
skipfooter:跳过末尾多少行
parse_dates:解析日期,有多种输入格式,具体参考文档。建议输入list,如[1,2,3],表示对第2,3,4列进行日期的解析
encoding:编码,如中文可用gbk等,如报编码错误请检查这个。
3,数据概览及操作
3.1 主要方法为describe,info,head,columns,index,values等
- head
train_data.head()#查看开头几行,默认5

- describe
train_data.describe()#查看描述信息,默认只对数值列起作用,你可以像第二行一样包含所有,或指定一个list的列
#train_data.describe(include='all')
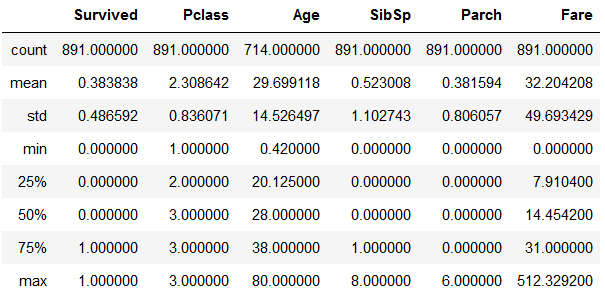
以上,有统计数量,最大最小,平均值,标准差,以及若干百分位的值(百分比可用list指定)
- info
train_data.info(verbose=True,null_counts=True)#查看各列数据类型,null值数量等
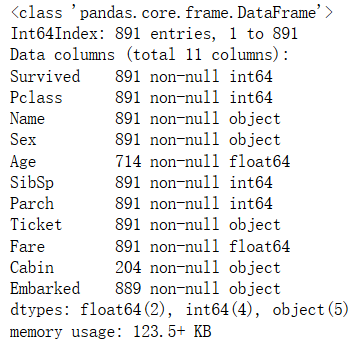
查看shape,类型,行,列
# 维度
train_data.shape
# size为shape 2个维度乘积
train_data.size # DataFrame转np array
train_data.values# 即可 # 获取所有列名,行index
train_data.columns/index # 查看所有数据类型
data.dtypes # 一列或多列(多列时给个list)
ages=train_data.Age
ages=train_data['Age'] # 一行或多行
# 这2个相同
first_row=train_data.loc[0]
first_row=train_data.iloc[0] # 多个行时不同
rows=train_data.iloc[1:3]# 第2,3行
rows=train_data.loc[1:3]# 第1,2,3行 # 同时筛选行和列。前面是选取的行,后面是选取的列
train_data.iloc[[1,2],[1,2]]
train_data.iloc[1:2,1:2]
3.2 复杂查询
#联合查询
a=train_data.loc[train_data.Pclass.isin([1,2]) & (train_data.Age<=30)]
#中位数
train_data.Age.median()
#平均值
train_data.Age.mean()
#查看该列包含种类(相当于set操作)
train_data.Pclass.unique()
#统计该列各个种类的数量(统计set后各元素出现的次数)
train_data.groupby('Pclass').size()# 结果按索引排序
train_data.Pclass.value_counts()# 这种方式更好,结果是按值排序的
#票价与年龄的比例,求比例最大的行号
idx=(train_data.Fare/train_data.Age).idxmax()
#查看此人是否存活
train_data.loc[idx,'Survived']
# 统计指定列为NaN的行数
train_data[train_data.Embarked.isna()]
# 统计指定列某条件下的行数
(train_data['Age']<50).sum()
# 统计所有Ticket中出现PC的次数
train_data.Ticket.map(lambda ticket:'PC' in ticket).sum()
3.3 数据操作
- DataFrame合并
# DataFrame合并
df1=pd.DataFrame(data={'price':[6,6.5,7],'count':[10,9,8]})
df2=pd.DataFrame(data={'name':['a','b'],'married':['Yes','Yes'],'price':[1,2]})
# 列名不同的添加列,相同列名的合并,数据按行合并
df=pd.concat([df1,df2],sort=False) # 以2个df中指定列进行合并,合并的列名不必相同(此时第一列的列名为空),如果相同则作为index并将index排序
df1=pd.DataFrame(data={'price':[6,6.5,7],'count':[10,9,8],'sth':[2,3,4]})
df2=pd.DataFrame(data={'name':['yanfang','chenlun'],'married':['Yes','Yes'],'price':[1,10],'sth':[2,8]}) # 默认合并方式为left,即df1合并列(price,3)有多少行,结果就是多少行
# 除合并的列外,2个df不允许再出现同名的列
df=df1.set_index('price').join(df2.set_index('sth'),how='outer',sort=False)
# df=df1.set_index('price').join(df2.set_index('price'),how='outer',sort=False) 不允许重复列sth
- DataFrame属性修改
# 改变某列的数据类型,如将Age通过cut分段后,它的数据类型为categorical,而你想做PCA降维,那么只能转化为数值型
train_data['Age_bin']=train_data['Age_bin'].astype('float')
# 重命名列
data=data.rename(columns=dict(Pclass='Class',Fare='Ticket_price'))
# 重命名index
data=data.rename_axis("Id",axis=0)# 注意axis=1也可行,此时并未重命名index,而是将index作为一列,给予它一个列名
- groupby 分类(查询)
# groupby分类
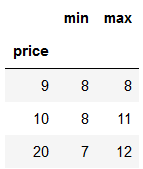
df=pd.DataFrame(data=[[20,7],[10,11],[10,8],[20,12],[9,8]],columns=['price','points'])
# 输出各价钱对应的最高分数
df.groupby('price')['points'].max().sort_index(axis=0)#对于Series,它只有一列数据,axis必须为0
# agg:以多个函数操作的结果作为各个列
both=df.groupby('price').points.agg([min,max])
both
- 联合排序
# 多个列的排序
data=train_data.iloc[:10,4:6]
data.sort_values(by=['Age','SibSp'])

- 数据修改
# map修改数据,apply是另一个修改方法
train_datan['Ticket']=train_data.Ticket.map(lambda ticket:'PC' in ticket)# 变为布尔类型 # 增加列:将Age按年龄段分类,此时该列的数据类型为categorical
train_data['Age_bin']=pd.cut(train_data['Age'],bins=[0,25,40,55,95],labels=[1,2,3,4])
# get_dummies对类别型的列做one-hot处理,之后我们就可以如下查看相关系数了
data_show=pd.get_dummies(train_data,columns=['Age_bin'])
sns.heatmap(data_show.corr(),annot=True,cmap='RdYlGn',linewidths=0.2) # 缺失值处理:之前的map,apply,以及此处的fillna,replace等都可以修改数据。
# 以中位数填充None/NaN值
train_data.Age.fillna(train_data.Age.median(),inplace=True)
# 如果该列缺少太多数据,可直接原地(inplace)删除该列
train_data.drop(['Age'],axis=1,inplace=True)
# 使用replace替换属性中的值
train_data.Age.replace(28,30)
4 可视化
df可以直接用matplotlib可视化
train_data['Age'].hist()# 统计各个年龄的数量,作直方图
Pandas使用细则的更多相关文章
- pandas基础-Python3
未完 for examples: example 1: # Code based on Python 3.x # _*_ coding: utf-8 _*_ # __Author: "LEM ...
- 10 Minutes to pandas
摘要 一.创建对象 二.查看数据 三.选择和设置 四.缺失值处理 五.相关操作 六.聚合 七.重排(Reshaping) 八.时间序列 九.Categorical类型 十.画图 十一 ...
- 利用Python进行数据分析(15) pandas基础: 字符串操作
字符串对象方法 split()方法拆分字符串: strip()方法去掉空白符和换行符: split()结合strip()使用: "+"符号可以将多个字符串连接起来: join( ...
- 利用Python进行数据分析(10) pandas基础: 处理缺失数据
数据不完整在数据分析的过程中很常见. pandas使用浮点值NaN表示浮点和非浮点数组里的缺失数据. pandas使用isnull()和notnull()函数来判断缺失情况. 对于缺失数据一般处理 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- pandas.DataFrame对行和列求和及添加新行和列
导入模块: from pandas import DataFrame import pandas as pd import numpy as np 生成DataFrame数据 df = DataFra ...
随机推荐
- mongodb为集合新增字段、删除字段、修改字段(转)
新增字段 为atest集合新增一个字段content db.atest.update({},{$set:{content:""}},{multi:1}) 删除uname字段 db. ...
- Laravel进行数据库迁移(migration)
迁移(migration) 文档的简介是:迁移就像数据库的版本控制,允许团队简单轻松的编辑并共享应用的数据库表结构,迁移通常和 Laravel 的结构构建器结对从而可以很容易地构建应用的数据库表结构. ...
- 题解 【POJ1187】 陨石的秘密
解析 考虑到数据范围,其实我们可以用记搜. 设\(f[a][b][c][d]\)表示还剩\(a\)个'{}',\(b\)个"[]",\(c\)个"()",深度\ ...
- 【Winform-自定义控件】自定义控件学习+一个笑脸控件例子
1.CompositeControls组合控件:在原有控件的基础上根据需要进行组合 2.ExtendedControls 扩展控件:继承自原有控件,添加一些新的属性和方法,绘制一些新元素 当每个But ...
- docker安装redis并允许外网访问
拉取redis镜像 docker pull redis:3.2 本地新建redis配置文件 redis.conf ,写入以下内容 #允许外网访问bind 0.0.0.0 daemonize NO pr ...
- [Flask]sqlalchemy使用count()函数遇到的问题
sqlalchemy使用count()函数遇到的问题 在使用flask-sqlalchemy对一个千万级别表进行count操作时,出现了耗时严重.内存飙升的问题. 原代码: # 统计当日登陆次数 co ...
- jsp大文件传输断点续传源码
这里只写后端的代码,基本的思想就是,前端将文件分片,然后每次访问上传接口的时候,向后端传入参数:当前为第几块文件,和分片总数 下面直接贴代码吧,一些难懂的我大部分都加上注释了: 上传文件实体类: 看得 ...
- 【IOI2018】机械娃娃
看到的时候感到很不可做,因为所有的开关都要状态归零.因此可以得到两分的好成绩. --然后 yhx-12243 说:这不是线段树优化建图吗? 于是我获得了启发,会做了-- 还不是和上次一样,通过提示做出 ...
- Spring——顾问封装通知
通知(advice)是Spring中的一种比较简单的切面,只能将切面织入到目标类的所有方法中,而无法对指定方法进行增强 顾问(advisor)是Spring提供的另外一种切面,可以织入到指定的方法中 ...
- HDU6140--Hybrid Crystals(思维)
Hybrid Crystals Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)T ...