bash基础——grep、基本正则表达式、扩展正则表达式、fgrep
grep
grep全称:Globally search a Regular Expression and Print 全局搜索正则表达式
正规表达式本质上是一种"表示方法", 只要工具程序支持这种表示方法,那么该工具就可以使用正则表达式处理字符串。 例如 vi, grep, awk ,sed 等等工具,因为她们有支持正规表示法, 所以,这些工具就可以使用正规表示法的特殊字节来进行字串的处理。但例如 cp, ls 等命令并未支持正规表示法, 所以就只能使用 bash 自己本身的wildcards(通配符)。通配符与正则表达式是两个完全不同的东西,通配符只是bash提供的一个功能,正则表达式是一种字符串处理的表达方式。千万不要将而这混淆。
正则表达式在表示字符串时,依据不同的严谨程度可以分为基础正则表达式和扩展正则表达式。
grep在查找字符串的时候,是以整行为单位进行数据选取的。举例:一个文件有10行,其中2行包含匹配关键字,那么grep只输出命中的那两行,其他全部丢掉。
--color=auto 将匹配到的关键字高亮。一般来说这个不用我们指定,因为Linux distribution已经为我们alias指定好了。

-n:显示命中关键字在原文件中的行数
-v显示非关键字的那些行
[root@51cto ~]# cat uniqtest -n
wang student
wang student
han teacher
liu teacher
zhang student
wang student
[root@51cto ~]# grep "wang" uniqtest -v
han teacher
liu teacher
zhang student
-o只显示关键字
[root@51cto ~]# cat uniqtest -n
wang student
wang student
han teacher
liu teacher
zhang student
wang student
[root@51cto ~]# grep "wang" uniqtest -o
wang
wang
wang
-i 不区分大小写
[root@51cto ~]# cat uniqtest
wang student
wang student
han teacher
liu teacher
zhang student
wang student
Wang student
[root@51cto ~]# grep "wang" uniqtest -i
wang student
wang student
wang student
Wang student
-A# 将命中的那一行下面#行也显示出来;
-B# 将命中的那一行上面#行也显示出来。如果,则
-C# 前后都要显示#行
1只是做个例子,可以是任何数字
[root@51cto ~]# cat uniqtest
wang student
wang student
han teacher
liu teacher
zhang student
wang student
Wang student
[root@51cto ~]# grep "wang" uniqtest -A1
wang student
wang student
han teacher
--
wang student
Wang student
-q 安静模式,不现实任何输出
[root@localhost ~]# cat >a.txt <<EOF
> nihao
> nihaooo
> hello
> EOF
[root@localhost ~]# if grep -q hello a.txt ; then echo yes;else echo no; fi
yes
[root@localhost ~]# if grep -q word a.txt; then echo yes; else echo no; fi
no
-E 表示后面的表达式是扩展的正则表达式
基本正则表达式
参考:bash功能——命令行编辑、内部命令 外部命令、命令补全 、命令历史、文件名通配符、命令别名 文件名通配符
文件名通配符
* 代表任意长度任意字符
?代表任意单个字符
[] 指定范围的任意单个字符
[^ ] 指定范围外的任意单个字符
正则表达式元字符
. 匹配任意单个字符
[] 匹配指定范围内的任意单个字符
[^ ] 匹配指定范围外的任意单个字符
正则表达式匹配次数
+ 匹配前面≥1次
* 匹配前一个字符≥0次

? 匹配前一个字符0次或1次

\{m,n\} 匹配前一个字符最少m次 最多n次
\{0,n\} 最多n次
\{m\} 最少m次




更新——Thu Jun 14 22:20:33 EDT 2018
上面这个结果一直不理解,今天突然对这个问题有了新的理解
以前我的理解(错误的)
a[a-z]\{0,2\}c a后面跟26个字母中任何一个,后面\{0,2\}限定这个字母出现次数(0-2次)。那么这样的话asssc也应该命中,但实际上没有,这个困扰我好久
现在理解(正确)
a[a-z]\{0,2\}c [a-z]\{0,2\}应该看成一组一起理解,这一组可以表示aa,ab这种,加下图

更新——Thu Jun 14 22:20:33 EDT 2018
任意长度任意字符 .*

分组匹配

[root@51cto ~]# cat student
zhangsan,math=good,english=band
hanligang,math=good,english=good
yixiu,math=bad,english=good
xiaomo,math=bad,english=bad,music=good,geography=good
yuanzi,math=good,english=bad,music=good,geography=good
匹配数学、英语成绩一样的人(即数学好英语就好,数学坏英语就坏)使用了向后引用
grep '.*,math=\(.*\),english=\1' student --color

匹配数学成绩和英语成绩一样,音乐成绩和地理成绩一样。使用了向后引用
grep '.*,math=\(.*\),english=\1,music=\(.*\),geography=\2' student --color
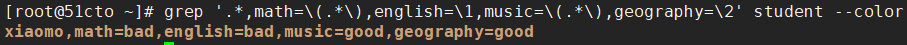
锚定符
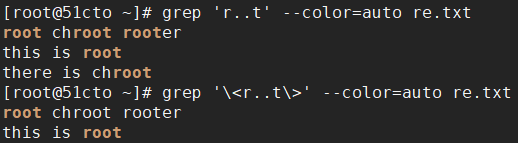
[root@51cto ~]# cat re.txt
root chroot rooter
this is root
there is chroot
\< 锚定词首
\> 锚定词尾
\< \> 锚定单词
^ 锚定行首
$ 锚定行尾

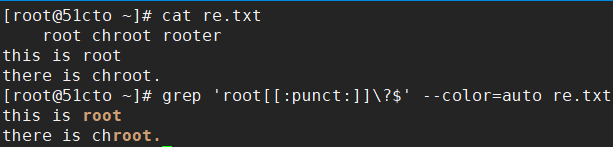
锚定行首 前面有空格的root开头的行

锚定行尾 有标点符号
字符类
POSIX定义了一些只能在正则表达式中使用的字符类
alnum 字母和数字
alpha 字母
blank 仅表示空格或制表符
cntrl 控制字符
digit 十进制数
graph 打印字符,不包含空格
lower 小写字母
print 打印字符,包含空格
punct 打印字符,不包含字母和数字
space 空白
upper 大写字母
xdigit 十六进制数
使用方法:
[[:space:]]
[[:digit:]]
[[:alpha:]]
echo '.,.,?.!123abcABC abcA123..?1 2' | grep '[[:punct:]]\{4,8\}[[:digit:]]\{1,3\}[[:lower:]]*[[:upper:]]*[[:space:]]*[[:graph:]]*' --color=auto

扩展正则表达式
扩展正则表达式元字符(与基本正则表达式一样)
.
[]
[^]
匹配次数
*
?
+ 至少匹配一次
{m,n} 括号前不需要转义字符\

锚定符
^ 行首锚定
$ 行尾锚定
\< 词首锚定新增 \b
\> 词尾锚定新增 \b

或者
表示符号 |

分组
分组不用转义

查找a=c b=d的行
echo 'a=10b=20c=10d=20' | egrep 'a=(..)b=(..)c=\1d=\2' --color

这里使用的都是egrep,使用grep -E效果是一样的
fgrep
不解析正则表达式 直接搜索文本

写正则表达式需要注意的两点
1. 转义字符 \
将正则表达式中元字符 转换成字符本身



2. 如果正则表达式中有命令替换 正则表达式只能使用” ”弱引用
如果正则表达式中没有命令替换 ‘ ’ “”

bash基础——grep、基本正则表达式、扩展正则表达式、fgrep的更多相关文章
- linux正则表达式(基础正则表达式+扩展正则表达式)
正则表达式应用非常广泛,例如:php,Python,java等,但在linux中最常用的正则表达式的命令就是grep(egrep),sed,awk等,换句话 说linux三剑客要想能工作的更高效,就一 ...
- Linux学习笔记之grep命令和使用正则表达式
0x00 正则表达式概述 正则表达式是描述一些字符串的模式,是由一些元字符和字符组成的字符串,而这些元字符是一些表示特殊意义的字符,即被正则表达式引擎表达的字符表示与其本意不同的一些字符. 0x01 ...
- egrep及扩展正则表达式 与正则表达式不同处
egrep及扩展正则表达式与正则表达式不同处 正则表达式有两类,分为基本正则表达式和扩展正则表达式,是使用命令egrep来使用扩展正则表达式,它与grep很多功能相同,仅在元字符上实现了些扩展扩展,在 ...
- shell基础 -- grep、sed、awk命令简介
在 shell 编程中,常需要处理文本,这里介绍几个文本处理命令. 一.grep 命令 grep 命令由来已久,用 grep 命令来查找 文本十分方便.在 POSIX 系统上,grep 可以在两种正则 ...
- Linux通配符与基础正则表达式、扩展正则表达式
在Linux命令行操作或者SHELL编程中总是容易混淆一些特殊字符的使用,比如元字符‘*’号,作为通配符匹配文件名时表示0个到无穷多个任意字符.而作为正则表达式匹配字符串时,表示重复0个到无穷多个的前 ...
- 『忘了再学』Shell基础 — 25、扩展正则表达式
目录 1.扩展正则表达式说明 2.练习 (1)+和?练习 (2)|和()练习 3.注意(重点) 1.扩展正则表达式说明 熟悉正则表达式的童鞋应该很疑惑,在其他的语言中是没有扩展正则表达式说法的,在Sh ...
- 正则表达式RE与扩展正则表达式ERE——grep与egrep
grep 正则表达式规则: ^ 行首定位符,表示从行首开始进行模式匹配 . 一个非换行符的字符 [ ] 匹配属于此集合的任意一个字符 [^ ] 匹配不属于此集合的任意一个字符 [a-z] (其指定的集 ...
- Bash 通配符、正则表达式、扩展正则表达式
BASH中的通配符(wildcard) *:任意长度的任意字符. ?:任意单个字符 []:匹配范围 [^]:排除匹配范围 [:alnum:]:所有字母和数字 [:alpha:]:所有字母 [:digi ...
- grep命令及基本正则表达式
grep命令是Linux系统中一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来. grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功 ...
随机推荐
- Caché到MySQL数据同步方法!
随着医疗行业信息化的发展,积累了大量的业务数据,如何挖掘这些数据,实现数据的可视化被提上日程,医院中通常有许多的信息化系统,使用的又都是不同厂商的数据库产品,如何统一汇聚数据,实现数据互通也是一个大问 ...
- 【Kail 学习笔记】Dmitry信息收集工具
DMitry(Deepmagic Information Gathering Tool)是一个一体化的信息收集工具.它可以用来收集以下信息: 根据IP(或域名)来查询目标主机的Whois信息 在Net ...
- EOS 资源汇总
EOS 资源汇总 A curated list of EOS Ecosystem by [SuperONE](https://superone.io/) EOS 主网 超级节点 https:/ ...
- golang web框架 beego 学习 (五) 配置文件
app.conf: appname = gowebProject httpport = runmode = dev copyrequestbody = true [db] host= localhos ...
- 【数据库开发】Redis消息通知
消息通知 任务队列 使用任务队列的好处 松耦合.生产者和消费者无需知道彼此的实现细节,只需要约定好任务的描述格式.这使得生产者和消费者可以由不同的团队使用不同的编程语言编写 易于扩展.消费者可以有多个 ...
- AMD, CMD, CommonJS和UMD
我的Github(https://github.com/tonyzheng1990/tonyzheng1990.github.io/issues),欢迎star 今天由于项目中引入的echarts的文 ...
- Ant 构建 Jmeter脚本报错详解
在搭建Ant构建Jmeter脚本的时候,小组成员遇到了各种问题. 再这里总结一下,遇到类似问题的可以做个参考 1.提示 does not exist 解决方案: 出现这种的问题原因有很多. 先排除权限 ...
- 重新渲染layui的radio
修改后添加这一段 layui.use('form', function() { var form = layui.form; form.render(); }); 也可以用官方的方法:https:// ...
- java虚拟机栈(关于java虚拟机内存的那些事)
<深入理解 java 虚拟机> 读书扩展 作者:淮左白衣 写于 2018年4月13日16:26:51 目录 文章目录 java虚拟机栈是什么 特点 栈帧 局部变量表 什么时候抛出 `Sta ...
- PAT甲级 堆 相关题_C++题解
堆 目录 <算法笔记>重点摘要 1147 Heaps (30) 1155 Heap Paths (30) <算法笔记> 9.7 堆 重点摘要 1. 定义 堆是完全二叉树,树中每 ...