Gluon 实现 dropout 丢弃法
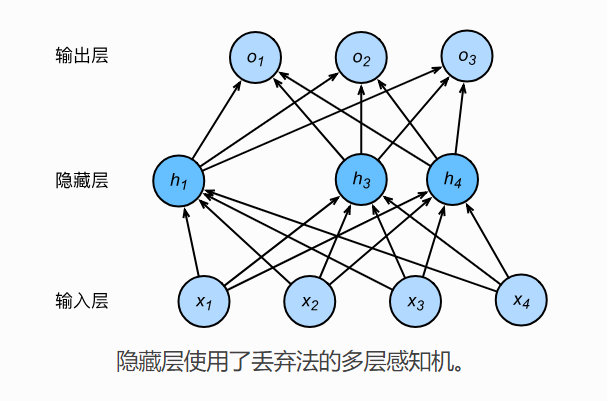
多层感知机中:
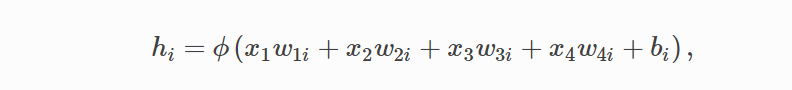
hi 以 p 的概率被丢弃,以 1-p 的概率被拉伸,除以 1 - p
import mxnet as mx
import sys
import os
import time
import gluonbook as gb
from mxnet import autograd,init
from mxnet import nd,gluon
from mxnet.gluon import data as gdata,nn
from mxnet.gluon import loss as gloss '''
# 模型参数
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784,10,256,256 W1 = nd.random.normal(scale=0.01,shape=(num_inputs,num_hiddens1))
b1 = nd.zeros(num_hiddens1) W2 = nd.random.normal(scale=0.01,shape=(num_hiddens1,num_hiddens2))
b2 = nd.zeros(num_hiddens2) W3 = nd.random.normal(scale=0.01,shape=(num_hiddens2,num_outputs))
b3 = nd.zeros(num_outputs) params = [W1,b1,W2,b2,W3,b3] for param in params:
param.attach_grad() # 定义网络 '''
# 读取数据
# fashionMNIST 28*28 转为224*224
def load_data_fashion_mnist(batch_size, resize=None, root=os.path.join(
'~', '.mxnet', 'datasets', 'fashion-mnist')):
root = os.path.expanduser(root) # 展开用户路径 '~'。
transformer = []
if resize:
transformer += [gdata.vision.transforms.Resize(resize)]
transformer += [gdata.vision.transforms.ToTensor()]
transformer = gdata.vision.transforms.Compose(transformer)
mnist_train = gdata.vision.FashionMNIST(root=root, train=True)
mnist_test = gdata.vision.FashionMNIST(root=root, train=False)
num_workers = 0 if sys.platform.startswith('win32') else 4
train_iter = gdata.DataLoader(
mnist_train.transform_first(transformer), batch_size, shuffle=True,
num_workers=num_workers)
test_iter = gdata.DataLoader(
mnist_test.transform_first(transformer), batch_size, shuffle=False,
num_workers=num_workers)
return train_iter, test_iter # 定义网络
drop_prob1,drop_prob2 = 0.2,0.5
# Gluon版
net = nn.Sequential()
net.add(nn.Dense(256,activation="relu"),
nn.Dropout(drop_prob1),
nn.Dense(256,activation="relu"),
nn.Dropout(drop_prob2),
nn.Dense(10)
)
net.initialize(init.Normal(sigma=0.01)) # 训练模型 def accuracy(y_hat, y):
return (y_hat.argmax(axis=1) == y.astype('float32')).mean().asscalar()
def evaluate_accuracy(data_iter, net):
acc = 0
for X, y in data_iter:
acc += accuracy(net(X), y)
return acc / len(data_iter) def train(net, train_iter, test_iter, loss, num_epochs, batch_size,
params=None, lr=None, trainer=None):
for epoch in range(num_epochs):
train_l_sum = 0
train_acc_sum = 0
for X, y in train_iter:
with autograd.record():
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
if trainer is None:
gb.sgd(params, lr, batch_size)
else:
trainer.step(batch_size) # 下一节将用到。
train_l_sum += l.mean().asscalar()
train_acc_sum += accuracy(y_hat, y)
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (epoch + 1, train_l_sum / len(train_iter),
train_acc_sum / len(train_iter), test_acc)) num_epochs = 5
lr = 0.5
batch_size = 256
loss = gloss.SoftmaxCrossEntropyLoss()
train_iter, test_iter = load_data_fashion_mnist(batch_size) trainer = gluon.Trainer(net.collect_params(),'sgd',{'learning_rate':lr})
train(net,train_iter,test_iter,loss,num_epochs,batch_size,None,None,trainer)

Gluon 实现 dropout 丢弃法的更多相关文章
- 【神经网络】丢弃法(dropout)
丢弃法是一种降低过拟合的方法,具体过程是在神经网络传播的过程中,随机"沉默"一些节点.这个行为让模型过度贴合训练集的难度更高. 添加丢弃层后,训练速度明显上升,在同样的轮数下测试集 ...
- MXNET:丢弃法
除了前面介绍的权重衰减以外,深度学习模型常常使用丢弃法(dropout)来应对过拟合问题. 方法与原理 为了确保测试模型的确定性,丢弃法的使用只发生在训练模型时,并非测试模型时.当神经网络中的某一层使 ...
- 小白学习之pytorch框架(6)-模型选择(K折交叉验证)、欠拟合、过拟合(权重衰减法(=L2范数正则化)、丢弃法)、正向传播、反向传播
下面要说的基本都是<动手学深度学习>这本花书上的内容,图也采用的书上的 首先说的是训练误差(模型在训练数据集上表现出的误差)和泛化误差(模型在任意一个测试数据集样本上表现出的误差的期望) ...
- dropout——gluon
https://blog.csdn.net/lizzy05/article/details/80162060 from mxnet import nd def dropout(X, drop_prob ...
- 动手学深度学习14- pytorch Dropout 实现与原理
方法 从零开始实现 定义模型参数 网络 评估函数 优化方法 定义损失函数 数据提取与训练评估 pytorch简洁实现 小结 针对深度学习中的过拟合问题,通常使用丢弃法(dropout),丢弃法有很多的 ...
- 神经网络优化算法:Dropout、梯度消失/爆炸、Adam优化算法,一篇就够了!
1. 训练误差和泛化误差 机器学习模型在训练数据集和测试数据集上的表现.如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不⼀定更准确.这是为什么呢 ...
- 从头学pytorch(七):dropout防止过拟合
上一篇讲了防止过拟合的一种方式,权重衰减,也即在loss上加上一部分\(\frac{\lambda}{2n} \|\boldsymbol{w}\|^2\),从而使得w不至于过大,即不过分偏向某个特征. ...
- dropout总结
1.伯努利分布:伯努利分布亦称“零一分布”.“两点分布”.称随机变量X有伯努利分布, 参数为p(0<p<1),如果它分别以概率p和1-p取1和0为值.EX= p,DX=p(1-p). 2. ...
- mxnet(gluon)—— 模型、数据集、损失函数、优化子等类、接口大全
1. 数据集 dataset_train = gluon.data.ArrayDataset(X_train, y_train) data_iter = gluon.data.DataLoader(d ...
随机推荐
- js运动缓动效果
http://www.cnblogs.com/hongru/archive/2012/03/16/2394332.html 转分享地址
- entity framework 查看自动生成的sql
public MesDbContext() : base("name=mysql") { Database.Log = new Action<string>(msg = ...
- Messenger和MVVM中的View Services
在前面的文章IoC容器和MVVM中, 介绍了IoC容器如何在大量用户类中帮助创建和分配用户类的实例.本文将介绍IoC容器如何帮助应用程序解耦,比如那些根据MVVM模式开发的应用.此模 式广泛应用在基于 ...
- Asp.Net MVC4通过id更新表单
用户需求是:一个表单一旦创建完,其中大部分的字段便不可再编辑.只能编辑其中部分字段. 而不可编辑是通过对input输入框设置disabled属性实现的,那么这时候直接向数据库中submit表单中的内容 ...
- 了解:C#三维数组和锯齿数值
此文章,只需了解,用到的不多. string[,,] three = new string[2, 3, 5]; //定义一个三维数组,给数组分别辅助2,3,5 对此数组的解释://有2个二维数组,每 ...
- JDK12 concurrenthashmap源码阅读
本文部分照片和代码分析来自文末参考资料 java8中的concurrenthashmap的方法逻辑和注解有些问题,建议看最新的JDK版本 建议阅读 concu ...
- MongoDB 学习(三)MongoDB 和 Spring 整合(Maven)
一.MongoDB 和 Spring 整合(Maven) 1.相关 jar 包准备 2.用 Maven 创建项目,pom.xml 文件 <project xmlns="http://m ...
- CentOS Linux 7.3 1611 (Core) 配置静态IP地址
详见: http://blog.csdn.net/johnnycode/article/details/50184073 设置静态IP 关于静态IP设置官方已经给出答案有兴趣的可以看官方WIKI指导, ...
- 十二 NIO和IO
NIO和IO的区别,应用场景? NIO和IO的主要区别 IO NIO 面向流 面向缓冲 阻塞IO 非阻塞IO 无 选择器 面向流和面向缓冲 Java NIO和IO之间第一个最大的区别是,IO是面向流的 ...
- mongodb使用实践---mongodb+mongo-java-driver+morphia
package com.lolaage.dals.dbfactory.mongodb; import java.net.UnknownHostException; import java.util.A ...