Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结
本课主题
- Master 资源调度的源码鉴赏
资源调度管理
- 任务调度与资源是通过 DAGScheduler、TaskScheduler、SchedulerBackend 等进行的作业调度
- 资源调度是指应用程序如何获得资源
- 任务调度是在资源调度的基础上进行的,没有资源调度那么任务调度就成为了无源之水无本之木
Master 资源调度的源码鉴赏
- 因为 Master 负责资源管理和调度,所以资源调度方法 scheduer 位于 Master.scala 这个类中,当注册程序或者资源发送改变的时候都会导致 Scheduler 的调用,例如注册的时候。
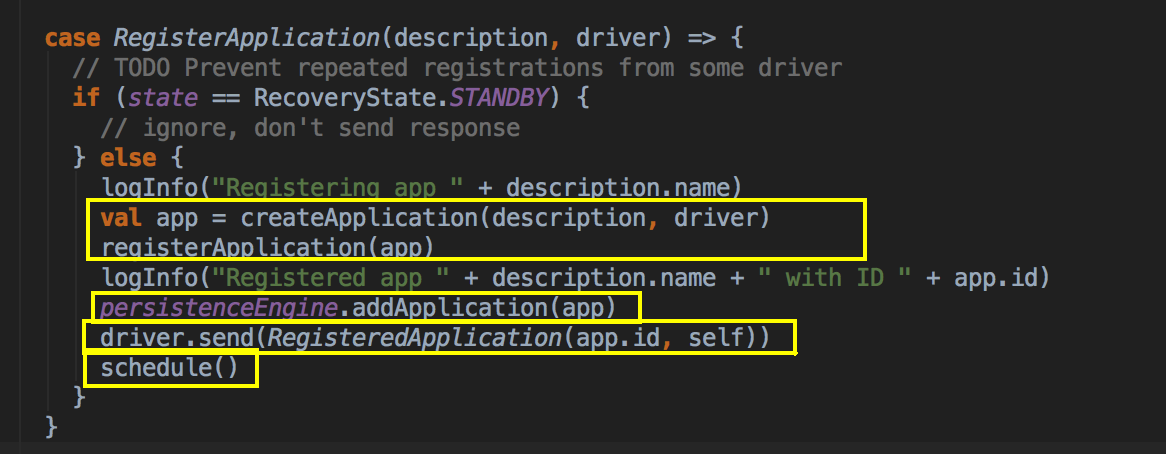
当这个应用程序向 Master 注册的时候,会把 ApplicationInfo 的信息放在一个 case class 里,过程中会新增新的 AppId,当注册的时候会分发给不同的数据结构记录起来,比如说 idToApp、endpointToApp、



- Scheduler 调用的时机,每次都有新的应用程序提交或者集群資源狀況发生改变的时候(包括 Executor 增加或者減少、Worker 增加或者減少等)具体代码运行顺序:scheduler( ) --> Random.shuffle( ) --> 有一个for循环过滤出ALIVE的Worker --> 过滤出付合Memory和Cores的Worker --> 然后调用 lanuchDriver( ) --> startExecutorsOnWorker( )

WorkerState 有以下几种:ALIVE, DEAD, DECOMMISSIONED, UNKNOWN
- 当前 Master 必需是 Alive 的方式才可以进行资源调度,一开始的时候会判断一下状态,如果不是 Alive 的状态会直接返回,也就是 StandByMaster 不会进行 Application 的资源调用
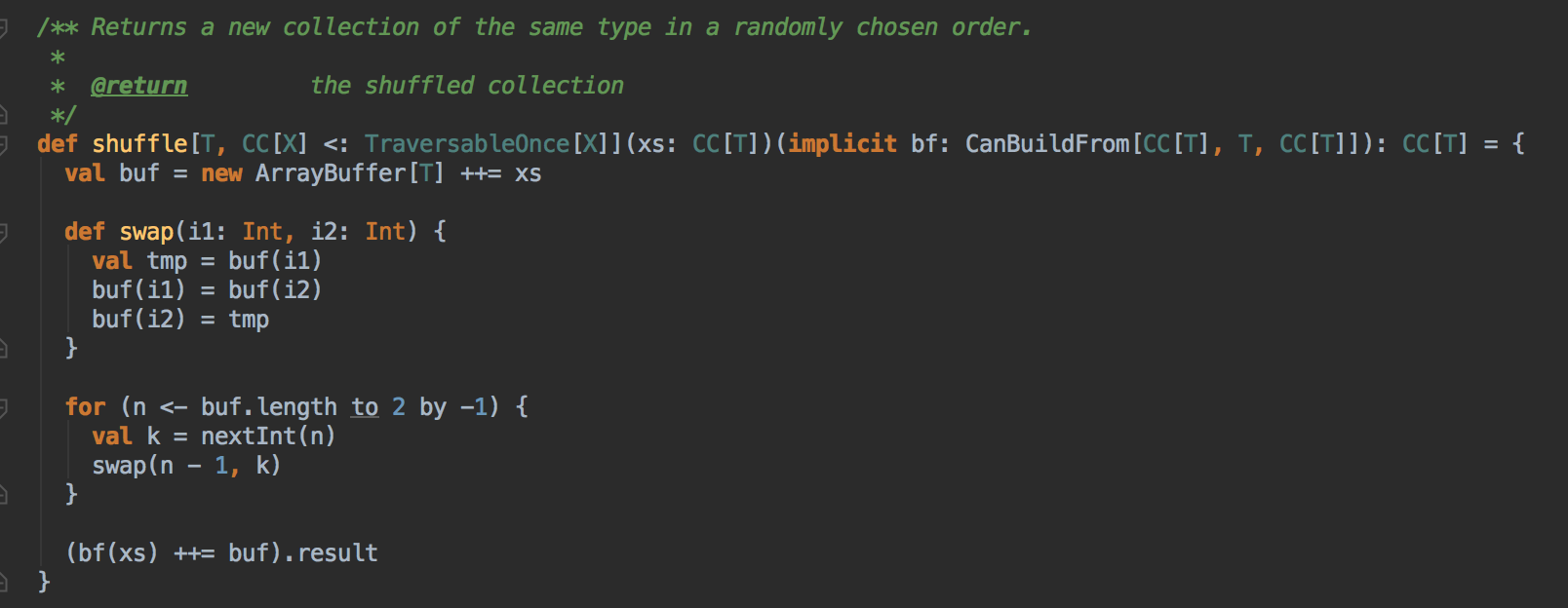
- 使用 Random.shuffle 把 Master 中保留的集群中所有 Worker 的信息随机打乱;其算法內部是循环随机交换所有 Worker 在 Master 緩存的數数据结构中的位置
- 接下来要判断所有 Worker 中哪些是 ALIVE 级別的 Worker 才能夠参与资源的分配工作
- 当 SparkSubmit 指定 Driver 在 Cluster 模式的情況下,此时 Driver 会加入 waitingDrivers 等待列表中,在每个 DriverInfo 中的 DriverDescription 中要启动 Driver 时候对 Worker 的內存及 CPU 要求等內容:


- 在符合资源要求的情況下然后采用随机打乱后的的一个 Worker 来启动 Driver,Master 发指令给 Worker 让远程的 Worker 启动 Driver,这就可以保证负载均衡。先启动 Driver 才会发生后续的一切的资源调度的模式

正式启动在Worker中启动Executor
Spark 默认为应用程序启动 Executor 的方式是 FIFO 的方式,也就是说所有的提交的应用程序都是放在调度的等待队列中的,先进先出,只有满足了前面应用程序的分配的基础上才能夠满足下一各应用程序资源的分配。正式启动在Worker中启动Executor:为应用程序具体分配 Executor 之前要判断应用程序是否还需要分配 core 如果不需要则不会会应用程序分配 Executor
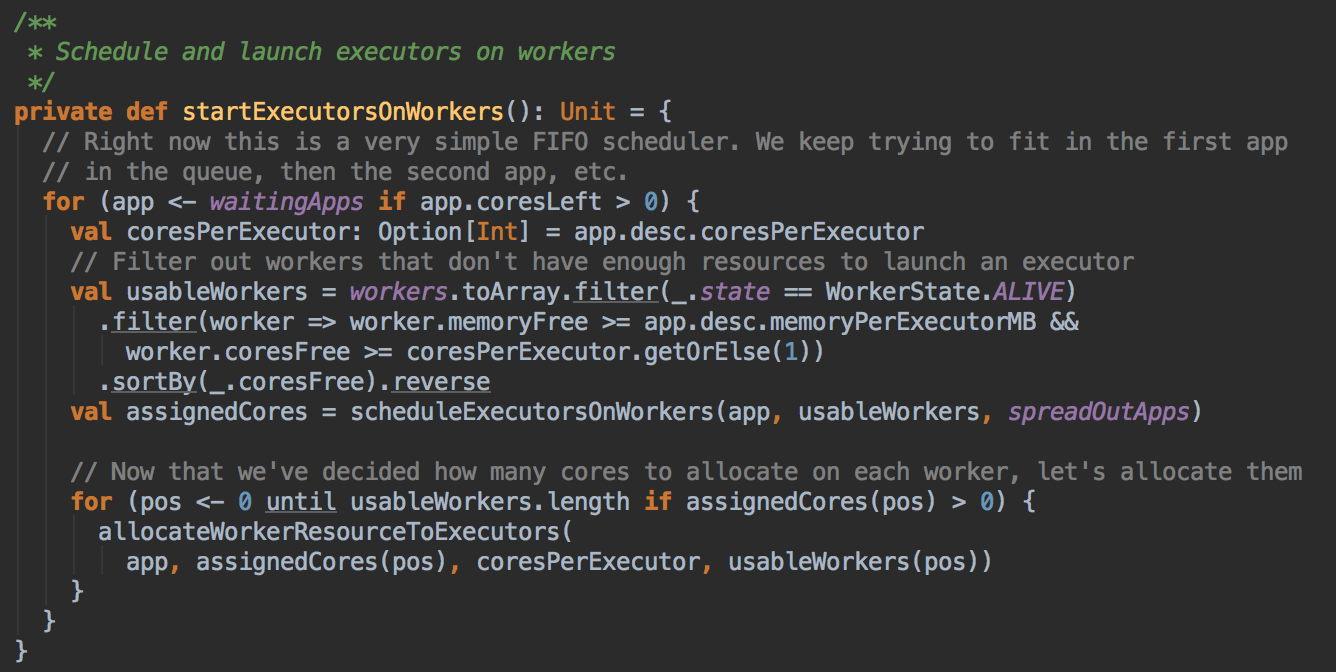
- 具体分配 Executor 之前要求 Worker 必需是 Alive 的状态且必需满足 Application 对每个 Executor 的內存和 Cores 的要求,并且在此基础上进行排序,谁的 Cores 多就排在前面。计算资源由大到小的 usableWorkers 数据库结构。把最好的资源放在前面。


在 FIFO 的情況下默认是 spreadOutApps 来让应用程序尽可能多的运行在所有的 Node 上。
- 然后调用 scheduleExecutorsOnWorkers 方法,为应用程序分配 executor 有两种情況,第一种方式是尽可能在集群的所有 Worker 上分配 Executor ,这种方式往往会来带潜在的更好的数据本地性。具体在集群上分配 Cores 的时候会尽可能的满足我们的要求,如果是每个 Worker 下面只能够为当前的应用程序分配一个 Executor 的话,每次是分配一个 Core! (每次为这个 Executor 增加一个 Core)。每次给 Executor 增加的时候都是增加一个 Core, 如果是 spreadout 的方式,循环一轮下一轮,假设有4个 Executors,如果 spreadout 的方式,它会在每个 Worker 中启动一个 Executor, 第一次为每个 Executor 分配一个线程,第二次再次循环后再分配一个线程。
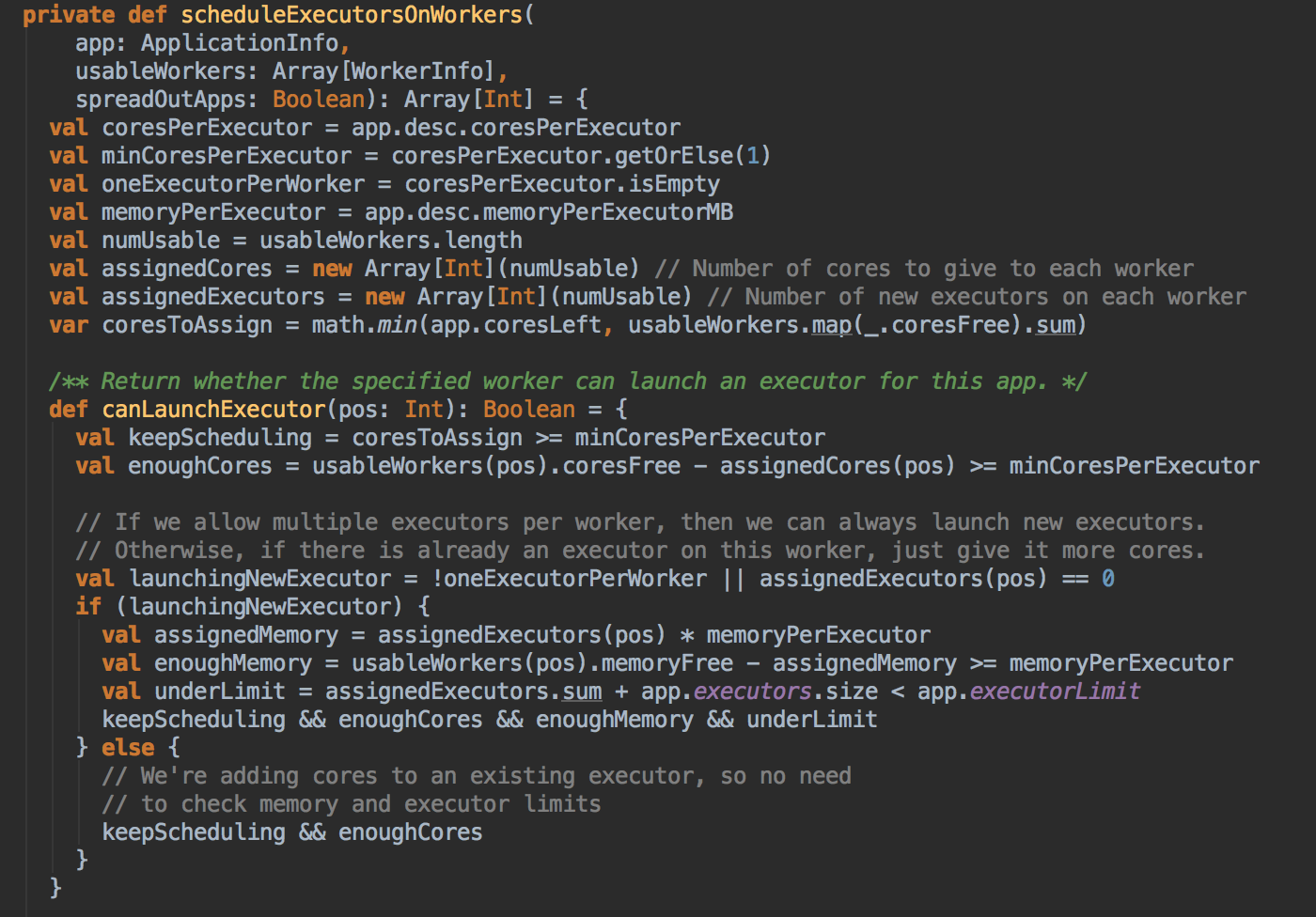
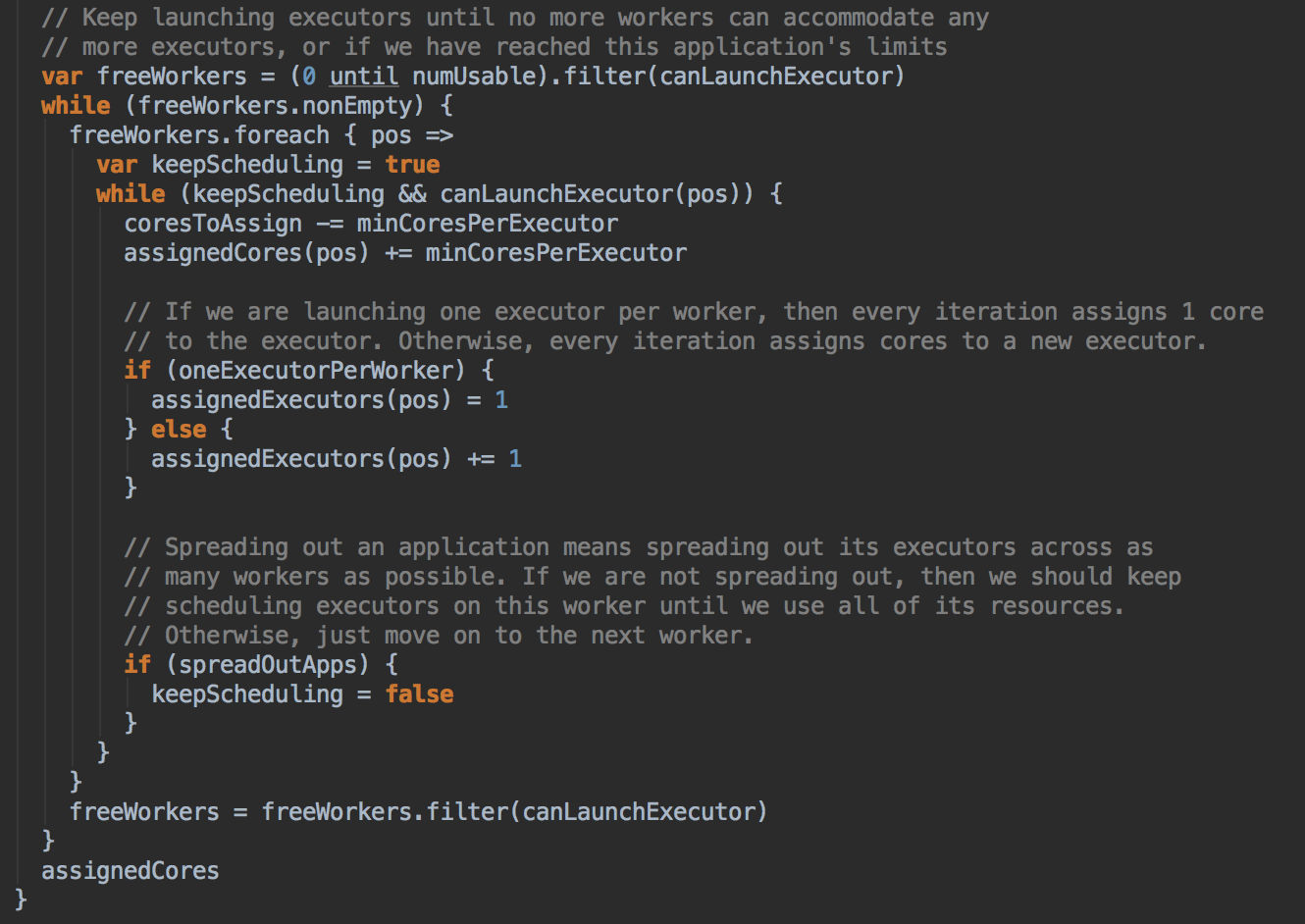
- 然后调用 allocateWorkerResourceToExecutors 方法
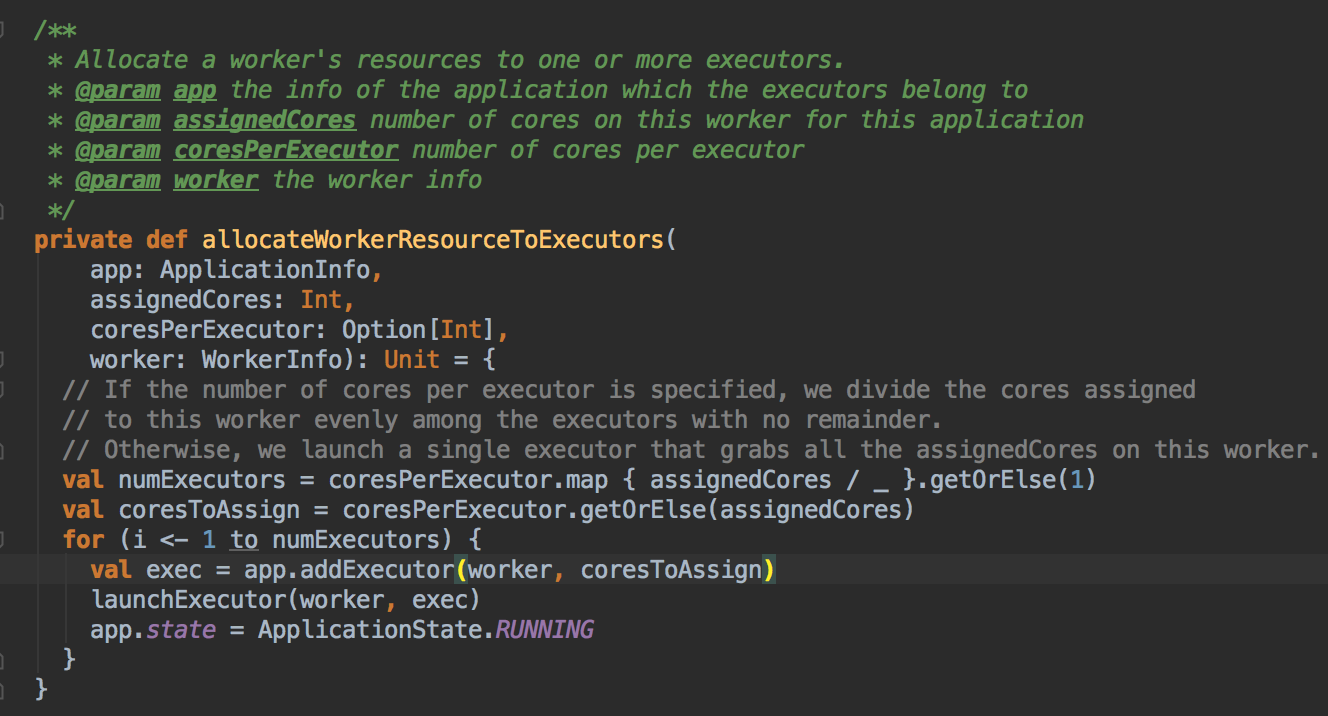
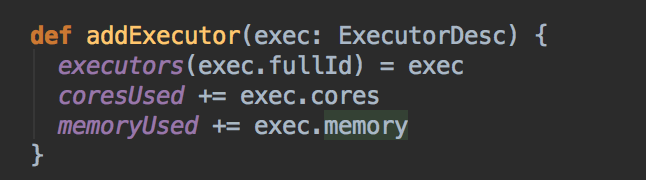
- 然后会调用 addExecutor 方法
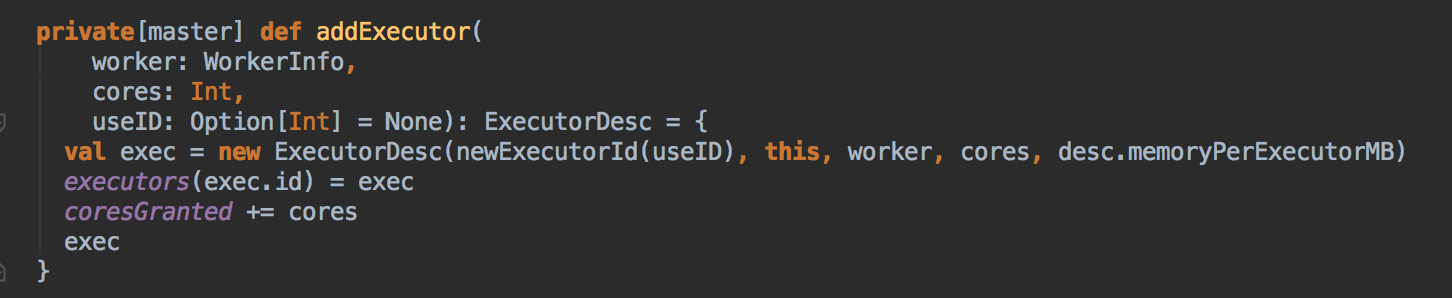
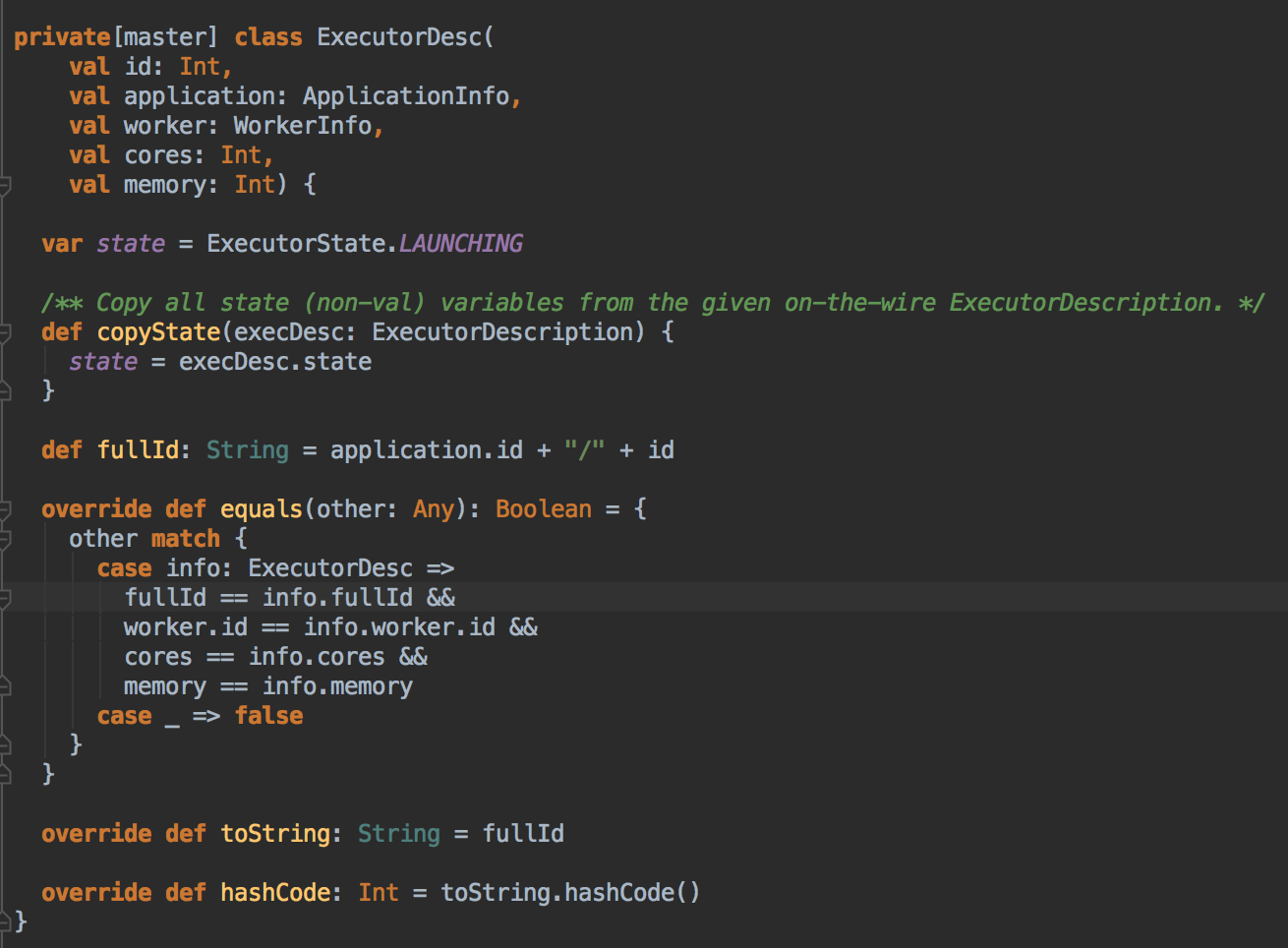
- 新增 Executor 后然后就真正的启动 Executor,准备具体要为当前应用程序分配的 Executor 信息后,Master 要通过远程通信发指令给 Worker 來具体启动 ExecutorBackend 进程,紧接给我们应用程序的 Driver 发送一个 ExecutorAdded 的信息。(Worker收到由Master发送LaunchExector信息之后如何处理可以参考我的下一篇博客!)
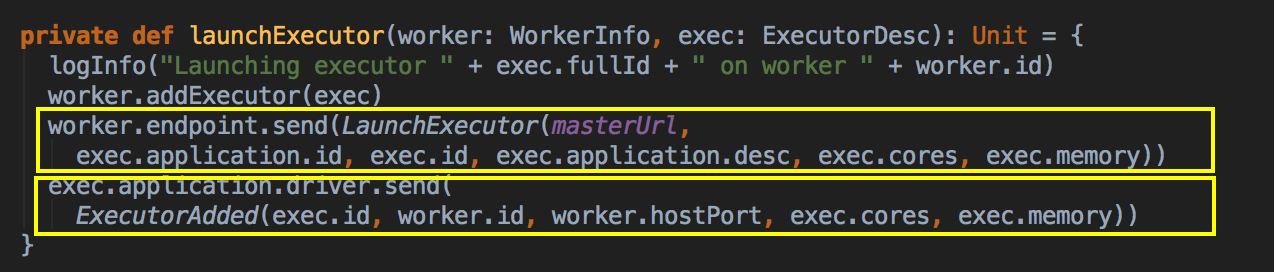
LaunchExecutor case class 数据结构,Master 会把这个数据发送到 Worker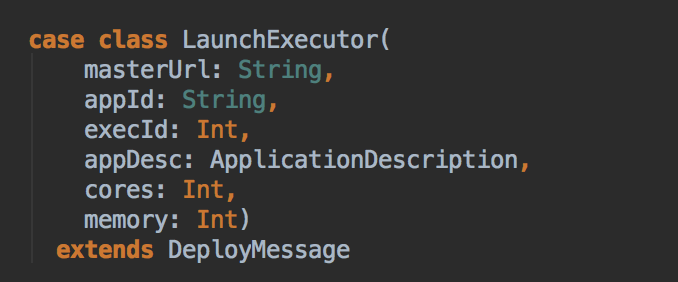
Master 会把这个数据发送到 Driver
[总结部份]
更新中......
Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结的更多相关文章
- [Spark内核] 第31课:Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结
本課主題 Master 资源调度的源码鉴赏 [引言部份:你希望读者看完这篇博客后有那些启发.学到什么样的知识点] 更新中...... 资源调度管理 任务调度与资源是通过 DAGScheduler.Ta ...
- Apache Spark源码走读之19 -- standalone cluster模式下资源的申请与释放
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文主要讲述在standalone cluster部署模式下,Spark Application在整个运行期间,资源(主要是cpu core和内存)的申请与 ...
- spark yarn cluster模式下任务提交和计算流程分析
spark可以运行在standalone,yarn,mesos等多种模式下,当前我们用的最普遍的是yarn模式,在yarn模式下又分为client和cluster.本文接下来将分析yarn clust ...
- Spark Streaming源码解读之JobScheduler内幕实现和深度思考
本期内容 : JobScheduler内幕实现 JobScheduler深度思考 JobScheduler 是整个Spark Streaming调度的核心,需要设置多线程,一条用于接收数据不断的循环, ...
- netty源码解解析(4.0)-23 ByteBuf内存管理:分配和释放
ByteBuf内存分配和释放由具体实现负责,抽象类型只定义的内存分配和释放的时机. 内存分配分两个阶段: 第一阶段,初始化时分配内存.第二阶段: 内存不够用时分配新的内存.ByteBuf抽象层没有定义 ...
- Spark基本工作流程及YARN cluster模式原理(读书笔记)
Spark基本工作流程及YARN cluster模式原理 转载请注明出处:http://www.cnblogs.com/BYRans/ Spark基本工作流程 相关术语解释 Spark应用程序相关的几 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- spark源码解析大全
第1章 Spark 整体概述 1.1 整体概念 Apache Spark 是一个开源的通用集群计算系统,它提供了 High-level 编程 API,支持 Scala.Java 和 Pytho ...
- spark源码分析以及优化
第一章.spark源码分析之RDD四种依赖关系 一.RDD四种依赖关系 RDD四种依赖关系,分别是 ShuffleDependency.PrunDependency.RangeDependency和O ...
随机推荐
- 使用express、react、webpack打包、socket.io、mongodb、ant.design、less、es6实现聊天室
拿到一个项目,我们应该如何去完成这个项目呢. 是直接上手? 还是先进行分析,然后再去解决呢?毫无疑问,如果直接上手解决,那么可能会因为知道目标所在,而导致出现各种问题. 所以,我们应该系统的分析这个项 ...
- Case When ELSE END语句
一.简介.Case When ELSE END共有两种用法: 说实话,这种就是数据库版的switch语句,但是只是形式上很像,实际上还是有差别的!!! Create Table Test6( ...
- Linux将MySQL数据库目录挂载至新数据盘
对于Linux系统来说,挂载磁盘的方法其实都大同小异,所以本文以CentOS系统为例,介绍下Linux系统磁盘挂载方法,前面大部分内容源于天翼云的论坛.1.查看磁盘情况使用命令fdisk -l # 列 ...
- JSONP原理及简单实现
在web2.0时代,熟练的使用ajax是每个前端攻城师必备的技能.然而由于受到浏览器的限制,ajax不允许跨域通信. JSONP就是就是目前主流的实现跨域通信的解决方案. 虽然在在jquery中,我们 ...
- 入门Promise的正确姿势
Promise是异步编程的一种解决方案,从语法上说,Promise是一个对象,从它可以获取异步操作的消息. Promise的基本用法 Promise构造函数接受一个函数作为参数,该函数的两个参数分别是 ...
- [转]MSBuild Target Framework and Target Platform
本文转自;https://msdn.microsoft.com/en-us/library/hh264221.aspx A project can be built to run on a targe ...
- vue项目中总结用到的方法。
依赖 vue-router 获得当前字符串,对应当前路由的路径,总是解析为绝对路径. computed: { productIcon () { return this.imgMap[this.$rou ...
- JavaMail 邮件发送
jar包部署 /** * 通过SMTP进行邮件集成 */ public class CmpSendMail { // 邮件发送服务器主机 private final static String HOS ...
- IntelliJ IDEA 安装配置
之前一直用的eclipse,以前公司的老大推荐过用这个,但是由于项目都比较赶,没及时学习. 后面这个公司的同时都用的idea,所以就换了 其实并没有那么难主要是刚刚切换时候快捷键不熟悉,打包什么的,有 ...
- android 动态库死机调试方法 .
原地址:http://blog.csdn.net/andyhuabing/article/details/7074979 这两种方法都不是我发明了,都是网上一些高手公共出来的调试方法,无奈找不到出处的 ...