深入学习Heritrix---解析Frontier(链接工厂)(转)
深入学习Heritrix---解析Frontier(链接工厂)
Frontier是Heritrix最核心的组成部分之一,也是最复杂的组成部分.它主要功能是为处理链接的线程提供URL,并负责链接处理完成后的一些后续调度操作.并且为了提高效率,它在内部使用了Berkeley DB.本节将对它的内部机理进行详细解剖.
在Heritrix的官方文档上有一个Frontier的例子,虽然很简单,但是它却解释Frontier实现的基本原理.在这里就不讨论,有兴趣的读者可以参考相应文档.但是不得不提它的三个核心方法:
(1)next(int timeout):为处理线程提供一个链接.Heritrix的所有处理线程(ToeThread)都是通过调用该方法获取链接的.
(2)schedule(CandidateURI caURI):调度待处理的链接.
(3)finished(CrawlURI cURI):完成一个已处理的链接.
整体结构如下:
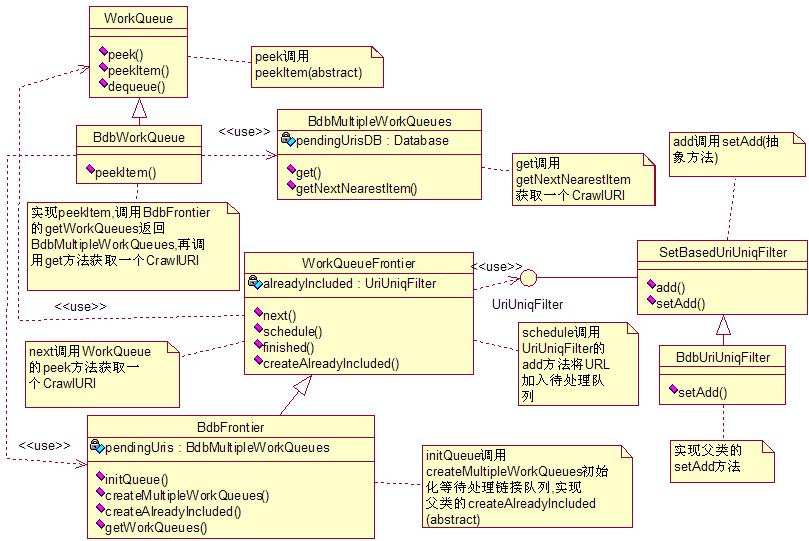
BdbMultipleWorkQueues:
它是对Berkeley DB的简单封装.在内部有一个Berkeley Database,存放所有待处理的链接.
package org.archive.crawler.frontier;
public class BdbMultipleWorkQueues
{
//存放所有待处理的URL的数据库
private Database pendingUrisDB = null; //由key获取一个链接
public CrawlURI get(DatabaseEntry headKey)
throws DatabaseException {
DatabaseEntry result = new DatabaseEntry();
// From Linda Lee of sleepycat:
// "You want to check the status returned from Cursor.getSearchKeyRange
// to make sure that you have OperationStatus.SUCCESS. In that case,
// you have found a valid data record, and result.getData()
// (called by internally by the binding code, in this case) will be
// non-null. The other possible status return is
// OperationStatus.NOTFOUND, in which case no data record matched
// the criteria. "
//由key获取相应的链接
OperationStatus status = getNextNearestItem(headKey, result);
CrawlURI retVal = null;
if (status != OperationStatus.SUCCESS) {
LOGGER.severe("See '1219854 NPE je-2.0 "
+ "entryToObject'. OperationStatus "
+ " was not SUCCESS: "
+ status
+ ", headKey "
+ BdbWorkQueue.getPrefixClassKey(headKey.getData()));
return null;
}
try {
retVal = (CrawlURI)crawlUriBinding.entryToObject(result);
} catch (RuntimeExceptionWrapper rw) {
LOGGER.log(
Level.SEVERE,
"expected object missing in queue " +
BdbWorkQueue.getPrefixClassKey(headKey.getData()),
rw);
return null;
}
retVal.setHolderKey(headKey);
return retVal;//返回链接
} //从等处理列表获取一个链接
protected OperationStatus getNextNearestItem(DatabaseEntry headKey,
DatabaseEntry result) throws DatabaseException {
Cursor cursor = null;
OperationStatus status;
try {
//打开游标
cursor = this.pendingUrisDB.openCursor(null, null);
// get cap; headKey at this point should always point to
// a queue-beginning cap entry (zero-length value)
status = cursor.getSearchKey(headKey, result, null);
if(status!=OperationStatus.SUCCESS || result.getData().length > 0) {
// cap missing
throw new DatabaseException("bdb queue cap missing");
}
// get next item (real first item of queue)
status = cursor.getNext(headKey,result,null);
} finally {
if(cursor!=null) {
cursor.close();
}
}
return status;
} /**
* Put the given CrawlURI in at the appropriate place.
* 添加URL到数据库
* @param curi
* @throws DatabaseException
*/
public void put(CrawlURI curi, boolean overwriteIfPresent)
throws DatabaseException {
DatabaseEntry insertKey = (DatabaseEntry)curi.getHolderKey();
if (insertKey == null) {
insertKey = calculateInsertKey(curi);
curi.setHolderKey(insertKey);
}
DatabaseEntry value = new DatabaseEntry();
crawlUriBinding.objectToEntry(curi, value);
// Output tally on avg. size if level is FINE or greater.
if (LOGGER.isLoggable(Level.FINE)) {
tallyAverageEntrySize(curi, value);
}
OperationStatus status;
if(overwriteIfPresent) {
//添加
status = pendingUrisDB.put(null, insertKey, value);
} else {
status = pendingUrisDB.putNoOverwrite(null, insertKey, value);
}
if(status!=OperationStatus.SUCCESS) {
LOGGER.severe("failed; "+status+ " "+curi);
}
}
}
BdbWorkQueue:
代表一个链接队列,该队列中所有的链接都具有相同的键值.它实际上是通过调用BdbMultipleWorkQueues的get方法从等处理链接数据库中取得一个链接的.
Code
WorkQueueFrontier:
实现了最核心的三个方法.
Code
BdbFrontier:
继承了WorkQueueFrontier,是Heritrix唯一个具有实际意义的链接工厂.
Code
BdbUriUniqFilter:
实际上是一个过滤器,它用来检查一个要进入等待队列的链接是否已经被抓取过.
Code
深入学习Heritrix---解析Frontier(链接工厂)(转)的更多相关文章
- 深入学习Python解析并解密PDF文件内容的方法
前面学习了解析PDF文档,并写入文档的知识,那篇文章的名字为深入学习Python解析并读取PDF文件内容的方法. 链接如下:https://www.cnblogs.com/wj-1314/p/9429 ...
- CS学习资料百度云链接
CS学习资料百度云链接 [0]Springboot微服务开发天气预报系统视频教程https://pan.baidu.com/s/1joz7flyztCq8oklBlsz8dQ提取密码:cpz7 [1] ...
- 小菜学习设计模式(三)—工厂方法(Factory Method)模式
前言 设计模式目录: 小菜学习设计模式(一)—模板方法(Template)模式 小菜学习设计模式(二)—单例(Singleton)模式 小菜学习设计模式(三)—工厂方法(Factory Method) ...
- Delphi之通过代码示例学习XML解析、StringReplace的用法(异常控制 good)
*Delphi之通过代码示例学习XML解析.StringReplace的用法 这个程序可以用于解析任何合法的XML字符串. 首先是看一下程序的运行效果: 以解析这样一个XML的字符串为例: <? ...
- jquery源码学习笔记三:jQuery工厂剖析
jquery源码学习笔记二:jQuery工厂 jquery源码学习笔记一:总体结构 上两篇说过,query的核心是一个jQuery工厂.其代码如下 function( window, noGlobal ...
- 分布式深度学习DDL解析
分布式深度学习DDL解析 一.概述 给一个庞大的GPU集群,在实际的应用中,现有的大数据调度器会导致长队列延迟和低的性能,该文章提出了Tiresias,即一个GPU集群的调度器,专门适应分布式深度学习 ...
- 深入学习python解析并读取PDF文件内容的方法
这篇文章主要学习了python解析并读取PDF文件内容的方法,包括对学习库的应用,python2.7和python3.6中python解析PDF文件内容库的更新,包括对pdfminer库的详细解释和应 ...
- 【javaweb学习】解析XML
XML解析方式有两种 dom:Document Object Model文档对象模型,是w3c组织推荐的解析方式 sax:Simple Api XML不是官方标准,但它是XML社区实际上的标准,几乎所 ...
- python学习(解析python官网会议安排)
在学习python的过程中,做练习,解析https://www.python.org/events/python-events/ HTML文件,输出Python官网发布的会议时间.名称和地点. 对ht ...
随机推荐
- HYSBZ - 2243 染色 (树链剖分+线段树)
题意:树上每个结点有自己的颜色,支持两种操作:1.将u到v路径上的点颜色修改为c; 2.求u到v路径上有多少段不同的颜色. 分析:树剖之后用线段树维护区间颜色段数.区间查询区间修改.线段树结点中维护的 ...
- Spring @Qualifier l转
当候选 Bean 数目不为 1 时的应对方法 在默认情况下使用 @Autowired 注释进行自动注入时,Spring 容器中匹配的候选 Bean 数目必须有且仅有一个.当找不到一个匹配的 Bean ...
- Mybatis${}、#{}及使用#{}时指定jdbcType
一.Mybatis 的Mapper.xml语句中parameterType向SQL语句传参有两种方式:#{}和${} 我们经常使用的是#{},一般解说是因为这种方式可以防止SQL注入,简单的说#{}这 ...
- Maven的SSM框架配置文件:
applicationContext.xml: <?xml version="1.0" encoding="UTF-8"?> <beans x ...
- SpringBoot 定义通过字段验证
第一步:定义ValidationResult类 public class ValidationResult { // 校验结果是否有错 private boolean hasErrors = fals ...
- spring security采用自定义登录页和退出功能
更新... 首先采用的是XML配置方式,请先查看 初识Spring security-添加security 在之前的示例中进行代码修改 项目结构如下: 一.修改spring-security.xml ...
- RQN 273 马棚问题 dp
PID273 / 马棚问题 2016-07-29 18:21:55 运行耗时:1624 ms 运行内存:16248 KB 题目描述 每天,小明和他的马外出,然后他们一边跑一边玩耍.当他们结束的时候, ...
- Web Service简介
1.1.Web Service基本概念 Web Service也叫XML Web Service WebService是一种可以接收从Internet或者Intranet上的其它系统中传递过来的请求, ...
- 新东方雅思词汇---7.3、dioxide
新东方雅思词汇---7.3.dioxide 一.总结 一句话总结: di(双)+oxide 英 [daɪ'ɒksaɪd] 美 [daɪ'ɑksaɪd] n. 二氧化物 词组短语 carbon di ...
- Spring mvc使用不了jstl 或者 Spring mvc不解析jstl
最近我搭了一个maven的springMVC的项目发现前端怎么也识别不了我的jstl,我查询了很多方法,导致这种情况的原因有很多 1.jar引用不对,maven中的正确导入可用的jar <dep ...