step5: 编写spider爬取
改写parse函数
实现功能:
1.获取文章列表页中的文章url并交给scrapy下载后,交给解析函数进行具体字段的解析
2.获取下一页的url并交给scrapy进行下载,下载完成后交给parse
提取一页列表中的文章url
#解析列表页中所有文章的url,遍历出来
def parse(self, response):
# 解析列表页中的所有url并交给scrapy下载后进行解析
post_urls = response.css('#archive .floated-thumb .post-thumb a::attr(href)').extract()
for post_url in post_urls:
print(post_url)
调试输出结果

如何让scrapy进行下载
引入request对象
from scrapy.http import Request
修改提取字段类类名为parse_detail,引入parse类进行域名拼接,yield下载
from urllib import parse
def parse(self, response):
#获取文章列表页中的文章url并交给解析函数进行具体字段的解析
#获取下一页的url并交给scrapy进行下载,下载完成后交给parse
post_urls = response.css('#archive .floated-thumb .post-thumb a::attr(href)').extract()
for post_url in post_urls:
#yield Request(url=post_url,callback=self.parse_detail)
yield Request(url=parse.urljoin(response.url, post_url),callback=self.parse_detail) #域名拼接 下载 下载完成后调用parse_detail解析字段
获取下一页并交给scrapy进行下载
#提取下一页并交给scrapy下载
next_url = response.css('.next.page-numbers::attr(href)').extract_first("")#空格去掉表示同时拥有两个属性
if next_url:
yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse) #继续调用parse解析出列表页中具体文章的url
调试前修改start_url为all-posts
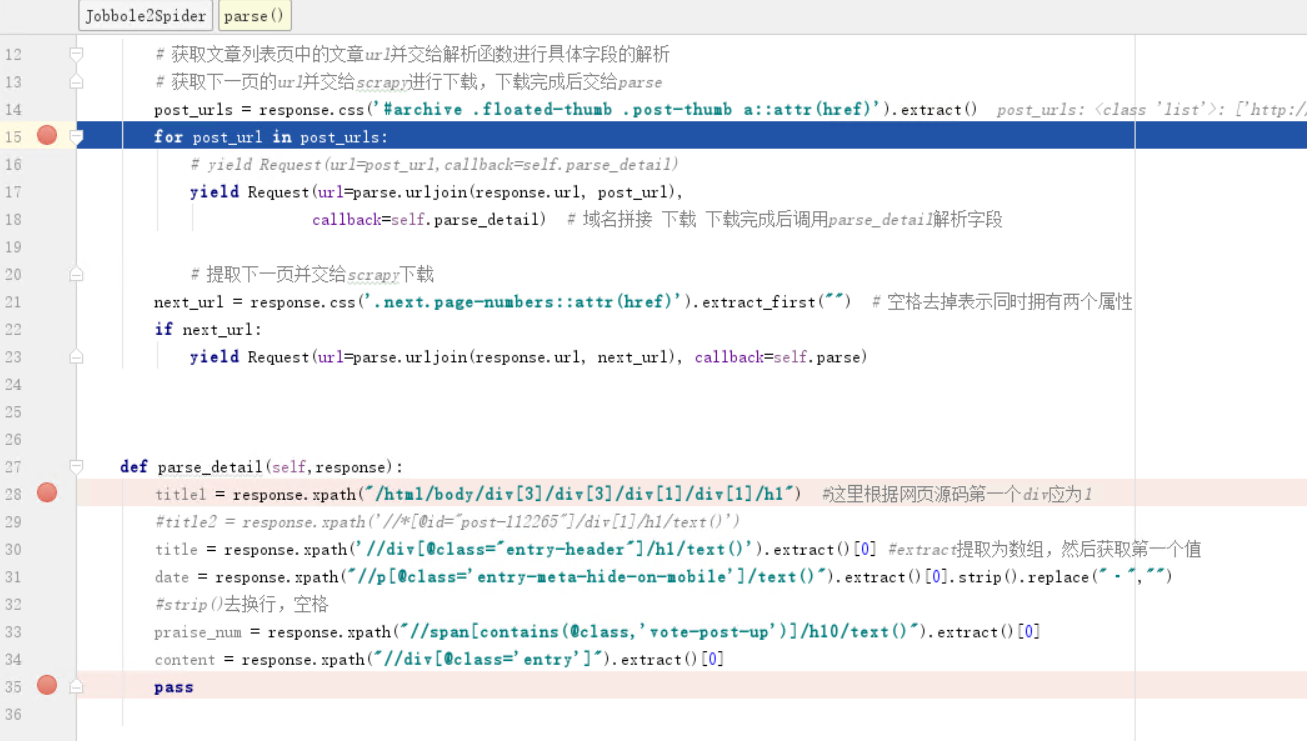
调试结果
step5: 编写spider爬取的更多相关文章
- 第八篇 编写spider爬取jobbole的所有文章
通过scrapy的Request和parse,我们能很容易的爬取所有列表页的文章信息. PS:parse.urljoin(response.url,post_url)的方法有个好处,如果post_ur ...
- 兴奋与沮丧并存spider爬取拉勾网
兴奋的开发除了爬取拉勾网的爬虫信息,可是当调试都成功了的那一刻,我被拉钩封IP了. 下面是spider的主要内容 import reimport scrapy from bs4 import Beau ...
- 用java编写爬虫爬取电影
一.爬取前提1)本地安装了mysql数据库2)安装了idea或者eclipse等开发工具 二.爬取内容 电影名称.电影简介.电影图片.电影下载链接 三.爬取逻辑1)进入电影网列表页, 针对列表的htm ...
- 第4章 scrapy爬取知名技术文章网站(2)
4-8~9 编写spider爬取jobbole的所有文章 # -*- coding: utf-8 -*- import re import scrapy import datetime from sc ...
- 第十六节:Scrapy爬虫框架之项目创建spider文件数据爬取
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取所设计的, 也可以应用在获取API所返回的数据或 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy-redis实现分布式爬取的过程与原理
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的时候,单个主机的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求 ...
- 爬虫入门之Scrapy框架基础框架结构及腾讯爬取(十)
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据. 如果安装了 IPyth ...
- Java爬取51job保存到MySQL并进行分析
大二下实训课结业作业,想着就爬个工作信息,原本是要用python的,后面想想就用java试试看, java就自学了一个月左右,想要锻炼一下自己面向对象的思想等等的, 然后网上转了一圈,拉钩什么的是动态 ...
随机推荐
- DATATable转为json
public static string DataTableToJson(DataTable dt) { StringBuilder jsonBuilder = new StringBuilder() ...
- 度度熊想去商场买一顶帽子,商场里有N顶帽子,有些帽子的价格可能相同。度度熊想买一顶价格第三便宜的帽子,问第三便宜的帽子价格是多少?
var data=[10,25,50,10,20,80,30,30,40,90]; function fun(arr,index){ var min=Math.min.apply(this,arr); ...
- 数据库_mysql多表操作
多表操作 实际开发中,一个项目通常需要很多张表才能完成.例如:一个商城项目就需要分类表(category).商品表(products).订单表(orders)等多张表.且这些表的数据之间 ...
- lua之base64加密和解密算法。
local function encodeBase64(source_str) local b64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnop ...
- POJ 3522 最小差值生成树(LCT)
题目大意:给出一个n个节点的图,求最大边权值减去最小边权值最小的生成树. 题解 Flash Hu大佬一如既往地强 先把边从小到大排序 然后依次加入每一条边 如果已经连通就把路径上权值最小的边删去 然后 ...
- Java类装载器ClassLoader
类装载器工作机制 类装载器就是寻找类的节码文件并构造出类在JVM内部表示对象的组件.在Java中,类装载器把一个类装入JVM中,要经过以下步骤: [1.]装载:查找和导入Class文件: [2.]链接 ...
- 网络CCNA基础了解
关于网络 CCNA.CCNP.CCIE 中的 CCNA 一.逻辑与.或.非 AND --> "与"计算 1 AND 1 = 1(取严) 1 AND 0 = 0 0 AND 1 ...
- 用JS实现汉字转拼音
<!DOCTYPE HTML> <html> <head> <title>用JS实现汉字转拼音</title> <meta chars ...
- 使用 webpack 搭建 React 项目
简评:相信很多开发者在入门 react 的时候都是使用 create-react-app 或 react-slingshot 这些脚手架来快速创建应用,当有特殊需求,需要修改 eject 出来的 we ...
- 【算法】禁忌搜索算法(Tabu Search,TS)超详细通俗解析附C++代码实例
01 什么是禁忌搜索算法? 1.1 先从爬山算法说起 爬山算法从当前的节点开始,和周围的邻居节点的值进行比较. 如果当前节点是最大的,那么返回当前节点,作为最大值 (既山峰最高点):反之就用最高的邻居 ...