第十六节:Scrapy爬虫框架之项目创建spider文件数据爬取
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取所设计的, 也可以应用在获取API所返回的数据或者通用的网络爬虫。
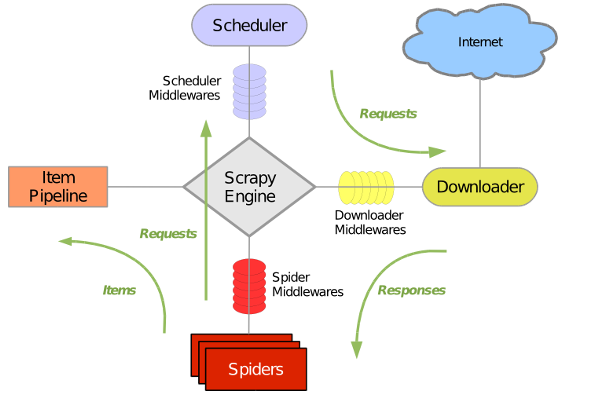
Scrapy原理图如下:
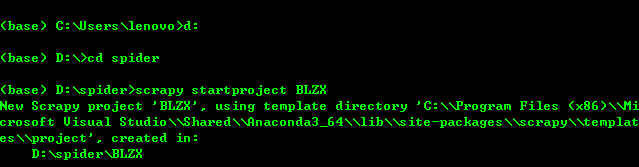
1、创建Scrapy项目:进入你需要创建scrapy项目的文件夹下,输入scrapy startproject BLZX(此处BLZX为爬虫项目名称)
项目创建完成后出现一个scrapy框架自动给你生成的爬虫目录

2、进入创建好的项目当中创建spider爬虫文件blzxSpider:
cd BLZX
scrapy genspider blzxSpider image.so.com (其中image.so.com为爬取数据的链接)
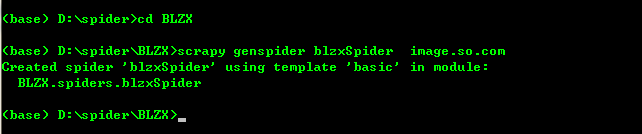
到此我们的scrapy爬虫项目已经创建完成,目录如下:

创建好了blzxSpider爬虫文件后scrapy将会在改文件当中自动生成 如下代码,我们就可以在这个文件当中进行编写代码爬取数据了。
# -*- coding: utf-8 -*-
import scrapy class BlzxspiderSpider(scrapy.Spider):
name = 'blzxSpider'
allowed_domains = ['image.so.com']
start_urls = ['http://image.so.com/'] def parse(self, response):
pass
3、爬取360图片玩转的图片,此时我们需要编写blzxSpiser文件进行爬取360图片
代码如下
import scrapy
import json class BoleSpider(scrapy.Spider):
name = 'boleSpider' def start_requests(self):
url = "https://image.so.com/zj?ch=photography&sn={}&listtype=new&temp=1"
page = self.settings.get("MAX_PAGE")
for i in range(int(page)+1):
yield scrapy.Request(url=url.format(i*30)) def parse(self,response):
photo_list = json.loads(response.text)
for image in photo_list.get("list"):
id = image["id"]
url = image["qhimg_url"]
title = image["group_title"]
thumb = image["qhimg_thumb_url"]
print(id,url,title,thumb)
抓取的结果为
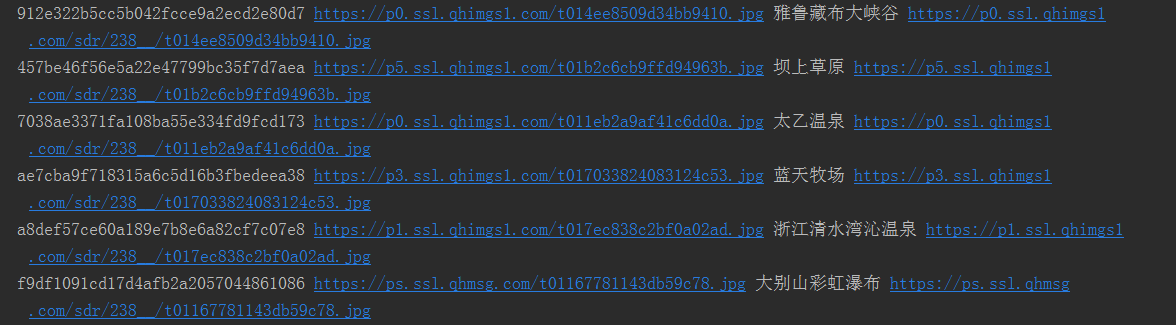
最后,我们已经将360图片的信息已经抓取下来了并打印在的控制台当中。但是我们需要把数据给下载下来,并且进行存储,所以在下一节当中会对item.py文件进行讲解。
第十六节:Scrapy爬虫框架之项目创建spider文件数据爬取的更多相关文章
- 第三百一十六节,Django框架,中间件
第三百一十六节,Django框架,中间件 django 中的中间件(middleware),在django中,中间件其实就是一个类,在请求到来和结束后,django会根据自己的规则在合适的时机执行中间 ...
- scrapy爬虫成长日记之创建工程-抽取数据-保存为json格式的数据
在安装完scrapy以后,相信大家都会跃跃欲试想定制一个自己的爬虫吧?我也不例外,下面详细记录一下定制一个scrapy工程都需要哪些步骤.如果你还没有安装好scrapy,又或者为scrapy的安装感到 ...
- 第二百六十六节,Tornado框架-XSS处理,页码计算,页码显示
Tornado框架-XSS处理,页码计算,页码显示 Tornado框架-XSS攻击过滤 注意:Tornado框架的模板语言,读取数据已经自动处理了XSS攻击,过滤转换了危险字符 如果要使危险字符可以远 ...
- 创建一个scrapy爬虫框架的项目
第一步:打开pycharm,选择"terminal",如图所示: 第二步:在命令中端输入创建scrapy项目的命令:scrapy startproject demo (demo指的 ...
- Scrapy爬虫框架(2)--内置py文件
Scrapy概念图 这里有很多py文件,分别与Scrapy的各个模块对应 superspider是一个爬虫项目 spider1.py则是一个创建好的爬虫文件,爬取资源返回url和数据 items.py ...
- 【php爬虫】百万级别知乎用户数据爬取与分析
代码托管地址:https://github.com/hoohack/zhihuSpider 这次抓取了110万的用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04) ...
- Python爬虫入门教程 3-100 美空网数据爬取
美空网数据----简介 从今天开始,我们尝试用2篇博客的内容量,搞定一个网站叫做"美空网"网址为:http://www.moko.cc/, 这个网站我分析了一下,我们要爬取的图片在 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- 第二百五十六节,Web框架
Web框架 Web框架本质 众所周知,对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端. 举例: #!/usr/bin/env python #c ...
随机推荐
- 执行linux脚本出现问题
1. 权限不够: 使用 chmod +x XXX.sh 提升权限 2. 出现:/bin/bash^M: bad interpreter: No such file or directory 原因:文件 ...
- mariadb+centos7+主从复制
MYSQL(mariadb) MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可.开发这个分支的原因之一是:甲骨文公司收购了MySQL后,有将MySQL闭源的 ...
- [POJ2750]Potted Flower
Description The little cat takes over the management of a new park. There is a large circular statue ...
- 如何用C#动态编译、执行代码[转]
原文链接 在开始之前,先熟悉几个类及部分属性.方法:CSharpCodeProvider.ICodeCompiler.CompilerParameters.CompilerResults.Assemb ...
- 445 Add Two Numbers II 两数相加 II
给定两个非空链表来代表两个非负整数.数字最高位位于链表开始位置.它们的每个节点只存储单个数字.将这两数相加会返回一个新的链表.你可以假设除了数字 0 之外,这两个数字都不会以零开头.进阶:如果输入链表 ...
- 自定义Image HtmlHelper
public static void Image(this HtmlHelper helper, string src, string alt = null, object htmlAttribute ...
- java.lang.String 字符串操作
1.获取文件名 //获取文件名,即就是去掉文件的后缀 /** * mypic.jpg * 获取文件名 * 1. 先找到"."的位置 * 2. 从第一个字符开始截取到".& ...
- 掌握Spark机器学习库-08.2-朴素贝叶斯算法
数据集 iris.data 数据集概览 代码 import org.apache.spark.SparkConf import org.apache.spark.ml.classification.{ ...
- Python学习 Day 3 字符串 编码 list tuple 循环 dict set
字符串和编码 字符 ASCII Unicode UTF-8 A 1000001 00000000 01000001 1000001 中 x 01001110 00101101 11100100 101 ...
- 使用Jenkins进行android项目的自动构建(1)
环境搭建 1. 下载JDK,安装,并将JDK的安装目录加入到环境变量JAVA_HOME,将JDK的bin目录加入到环境变量PATH. 2. 下载Android SDK,解压,并将SDK的安装目录加入到 ...