IO阻塞模型 非阻塞模型
IO阻塞模型(blocking IO)
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
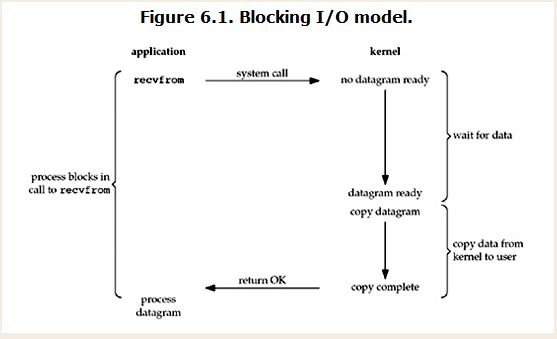
所以,blocking IO的特点就是在IO执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了。

from socket import * server = socket(AF_INET,SOCK_STREAM)
server.bind(('127.0.0.1',8080))
server.listen(5) while True:
conn,addr = server.accept()
print(addr)
while True:
try:
data = conn.recv(1024)
if not data:break
conn.send(data.upper())
except ConnectionResetError:
break
conn.close()
from socket import * client = socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8080))
while True:
msg = input('>>:').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
data = client.recv(1024)
print(data.decode('utf-8'))
client.close()
非阻塞IO模型
Linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
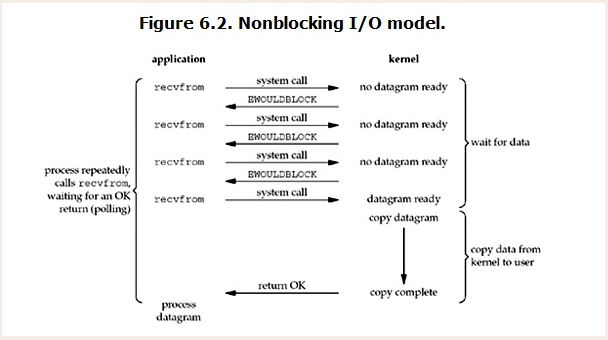
所以,在非阻塞式IO中,用户进程其实是需要不断的主动询问kernel数据准备好了没有。
# 1.对cpu的占用率过多,但是是无用的占用
# 2.在链接数过多的情况下不能及时响应客户端的消息 from socket import * server = socket(AF_INET,SOCK_STREAM)
server.bind(('127.0.0.1',8080))
server.listen(5)
server.setblocking(False) # 非阻塞型,默认为阻塞型True conn_l = []
while True:
try:
conn,addr = server.accept()
conn_l.append(conn)
print(addr)
except BlockingIOError:
# print('干其它活去了')
# time.sleep(2)
del_l = []
for conn in conn_l:
try:
data = conn.recv(1024)
if not data: # 针对linux系统
conn.close()
del_l.append(conn)
continue
conn.send(data.upper())
except BlockingIOError:
pass
except ConnectionResetError:
conn.close()
del_l.append(conn)
for conn in del_l:
conn_l.remove(conn)
from socket import * client = socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8081))
while True:
msg = input('>>:').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
data = client.recv(1024)
print(data.decode('utf-8'))
client.close()
IO多路复用
IO multiplexing这个词可能有点陌生,但是如果我说select/epoll,大概就都能明白了。有些地方也称这种IO方式为事件驱动IO(event driven IO)。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
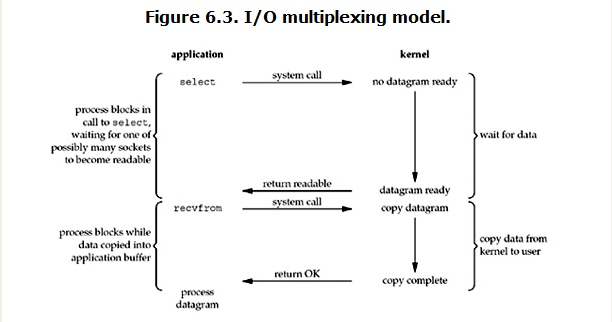
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上还更差一些。因为这里需要使用两个系统调用(select和recvfrom),而blocking IO只调用了一个系统调用(recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
强调:
1. 如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
2. 在多路复用模型中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
结论: select的优势在于可以处理多个连接,不适用于单个连接
from socket import *
import select server = socket(AF_INET,SOCK_STREAM)
server.bind(('127.0.0.1',8080))
server.listen(5)
server.setblocking(False) # 非阻塞型,默认为阻塞型True read_l = [server,]
print('strating....')
while True:
rl,wl,xl = select.select(read_l,[],[]) # 整体的返回值是一个元组,rl为元组里的一个列表
# print('===>',rl) # rl里的值就是server对象或conn对象
for r in rl:
if r is server:
conn,addr = r.accept()
read_l.append(conn)
else:
try:
data = r.recv(1024)
if not data:
r.close()
read_l.remove(r)
r.send(data.upper())
except ConnectionResetError:
r.close()
read_l.remove(r)
from socket import * client = socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8081))
while True:
msg = input('>>:').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
data = client.recv(1024)
print(data.decode('utf-8'))
client.close()
socketserver模块
TCP
import socketserver class MyTCPHandler(socketserver.BaseRequestHandler):
def handle(self):
print('========?>',self.request) # self.request is conn
while True:
data = self.request.recv(1024)
self.request.send(data.upper()) if __name__ == '__main__':
# socketserver.ForkingTCPServer 这个模块的多进程只能在linux上用
server = socketserver.ThreadingTCPServer(('127.0.0.1',8080),MyTCPHandler)
server.serve_forever()
from socket import * client = socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8081))
while True:
msg = input('>>:').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
data = client.recv(1024)
print(data.decode('utf-8'))
client.close()
UDP
import socketserver class MyTCPHandler(socketserver.BaseRequestHandler):
def handle(self):
print('========?>',self.request) # self.request 是一个元组,第一个值是客户端发来的消息,第二个值是一个套接字对象
client_data=self.request[0]
self.request[1].sendto(client_data.upper(),self.client_address) if __name__ == '__main__':
# socketserver.ForkingTCPServer 这个模块的多进程只能在linux上用
server = socketserver.ThreadingUDPServer(('127.0.0.1',8080),MyTCPHandler)
server.serve_forever()
from socket import * client = socket(AF_INET,SOCK_DGRAM)
while True:
msg = input('>>:').strip()
if not msg:continue
client.sendto(msg.encode('utf-8'),('127.0.0.1',8080))
data,server_addr = client.recvfrom(1024)
print(data.decode('utf-8'))
client.close()
paramiko模块
paramiko是一个用于做远程控制的模块,使用该模块可以对远程服务器进行命令或文件操作,值得一说的是,fabric和ansible内部的远程管理就是使用的paramiko来现实
下载安装
pip3 install paramiko #在python3中
SSHClient
用于连接远程服务器并执行基本命令
基于用户名密码连接:
import paramiko # 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='120.92.84.249', port=22, username='root', password='xxx') # 执行命令
stdin, stdout, stderr = ssh.exec_command('df')
# 获取命令结果
result = stdout.read()
print(result.decode('utf-8'))
# 关闭连接
ssh.close()
基于公钥密钥连接:
客户端文件名:id_rsa
服务端必须有文件名:authorized_keys(在用ssh-keygen时,必须制作一个authorized_keys,可以用ssh-copy-id来制作)
import paramiko
private_key = paramiko.RSAKey.from_private_key_file('/tmp/id_rsa')
# 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='120.92.84.249', port=22, username='root', pkey=private_key)
# 执行命令
stdin, stdout, stderr = ssh.exec_command('df')
# 获取命令结果
result = stdout.read()
print(result.decode('utf-8'))
# 关闭连接
ssh.close()
SFTPClient
用于连接远程服务器并执行上传下载
基于用户名密码上传下载
import paramiko
transport = paramiko.Transport(('120.92.84.249',22))
transport.connect(username='root',password='xxx')
sftp = paramiko.SFTPClient.from_transport(transport)
# 将location.py 上传至服务器 /tmp/test.py
sftp.put('/tmp/id_rsa', '/etc/test.rsa')
# 将remove_path 下载到本地 local_path
sftp.get('remove_path', 'local_path')
transport.close()
IO阻塞模型 非阻塞模型的更多相关文章
- 简述linux同步与异步、阻塞与非阻塞概念以及五种IO模型
1.概念剖析 相信很多从事linux后台开发工作的都接触过同步&异步.阻塞&非阻塞这样的概念,也相信都曾经产生过误解,比如认为同步就是阻塞.异步就是非阻塞,下面我们先剖析下这几个概念分 ...
- 磁盘IO的性能指标 阻塞与非阻塞、同步与异步 I/O模型
磁盘IO的性能指标 - 蝈蝈俊 - 博客园https://www.cnblogs.com/ghj1976/p/5611648.html 阻塞与非阻塞.同步与异步 I/O模型 - 蝈蝈俊.net - C ...
- Linux设备驱动中的IO模型---阻塞和非阻塞IO【转】
在前面学习网络编程时,曾经学过I/O模型 Linux 系统应用编程——网络编程(I/O模型),下面学习一下I/O模型在设备驱动中的应用. 回顾一下在Unix/Linux下共有五种I/O模型,分别是: ...
- IO模型浅析-阻塞、非阻塞、IO复用、信号驱动、异步IO、同步IO
最近看到OVS用户态的代码,在接收内核态信息的时候,使用了Epoll多路复用机制,对其十分不解,于是从网上找了一些资料,学习了一下<UNIX网络变成卷1:套接字联网API>这本书对应的章节 ...
- Linux中同步与异步、阻塞与非阻塞概念以及五种IO模型
1.概念剖析 相信很多从事linux后台开发工作的都接触过同步&异步.阻塞&非阻塞这样的概念,也相信都曾经产生过误解,比如认为同步就是阻塞.异步就是非阻塞,下面我们先剖析下这几个概念分 ...
- IO模型:同步、异步、阻塞、非阻塞
前言: 在Linux的网络编程中,同步IO(synchronous IO).异步IO(asynchronous IO).阻塞IO(blocking IO).非阻塞IO(non-blocking IO) ...
- 正确理解这四个重要且容易混乱的知识点:异步,同步,阻塞,非阻塞,5种IO模型
本文讨论的背景是Linux环境下的network IO,同步IO和异步IO,阻塞IO和非阻塞IO分别是什么 概念说明 在进行解释之前,首先要说明几个概念: - 用户空间和内核空间 - 进程切换 - 进 ...
- 谈IO中的阻塞和非阻塞,同步和异步及三种IO模型
什么是同步和异步? 烧水,我们都是通过热水壶来烧水的.在很久之前,科技还没有这么发达的时候,如果我们要烧水,需要把水壶放到火炉上,我们通过观察水壶内的水的沸腾程度来判断水有没有烧开.随着科技的发展,现 ...
- 什么是阻塞、非阻塞、同步和异步以及IO模型
首先先看如下几个问题,或者说我们经常会遇到的问题. 阻塞是否等于同步?非阻塞是否等于异步?同步一定是阻塞的么?异步一定是非阻塞的么?要把这四个概念讲明白,先从一顿简餐说起.假设你要做一顿便饭:烧土豆: ...
- 聊聊同步、异步、阻塞、非阻塞以及IO模型
前言 在使用Netty改造手写RPC框架的时候,需要给大家介绍一些相关的知识,这样很多东西大家就可以看明白了,手写RPC是一个支线任务,后续重点仍然是Kubernetes相关内容. 阻塞与非阻塞 同步 ...
随机推荐
- OkHttp+Stetho+Chrome调试android网络部分(原创)
android网络调试一直是一个比较麻烦的部分,因为在不同序列的请求中,返回的数据会有不同的变化,如果能像web开发一样使用调试功能查看页面的访问数据该是多么美好的事情! 很幸运的是,现在Androi ...
- JavaScript中数组常用方法的总结
JavaScript中数组Array常用的方法总结 标签(空格分隔): JavaScript ECMAScript数组给我们提供了许多常用的方法,便于我们对数组进行操作,下面,就来总结一下这些方法. ...
- WCF系列 Restful WCF
由于项目需要,需要完成移动端与服务端以json格式的数据交互,所以研究了Restful WCF相关内容,以实现ios端,android端与浏览器端能够与后台服务交互. 那么首先我们来了解下什么是Res ...
- SVN版本库的备份、还原、移植(初级篇、中级篇和高级篇)
版本库数据的移植:svnadmin dump.svnadmin load 导出: $svnlook youngest myrepos //查看到目前为止最新的版本号 $svnadmin dump my ...
- Vector类与Enumeration接口
Vector类用于保存一组对象,由于java不支持动态数组,Vector可以用于实现跟动态数组差不多的功能.如果要将一组对象存放在某种数据结构中,但是不能确定对象的个数时,Vector是一个不错的选择 ...
- 进程间通信之WM_COPYDATA方式反思,回顾和总结
许多Windows程序开发者喜欢使用WM_COPYDATA来实现一些进程间的简单通信(笔者也正在学习共享内存的一些知识来实现一些更高级的通信),这篇文章描述了笔者在使用这项技术时候的一些总结以及所遇到 ...
- 【vijos】1764 Dual Matrices(dp)
https://vijos.org/p/1764 自从心态好了很多后,做题的确很轻松. 这种题直接考虑我当前拿了一个,剩余空间最大能拿多少即可. 显然我们枚举每一个点拿出一个矩形(这个点作为右下角), ...
- Json.net操作json
string str="{\"size\":15,\"query\":{\"match\":{\"data.query. ...
- 【ARDUINO】HC-05蓝牙不配对问题
除了刷主从之外,不配对的原因有1:已经配对其他设备,需用AT+RMAAD来移除.2.默认为蓝牙由绑定指令设置,需改为任意地址连接模式AT+CMODE=1 //#define AT 2 #define ...
- poj 3281(网络流+拆点)
题目链接:http://poj.org/problem?id=3281 思路:设一个超级源点和一个超级汇点,源点与食物相连,饮料与汇点相连,然后就是对牛进行拆点,一边喜欢的食物相连,一边与喜欢的饮料相 ...