LTMU论文解析
LTMU
第零部分:前景提要
一般来说,单目标跟踪任务可以从以下三个角度解读:
- A matching/correspondence problem.把其视为前后两帧物体匹配的任务(而不考虑在跟踪过程中物体外观的改变,也就是不会因为物体外观更改而更改模型)。
- An appearance learning problem.外观学习的任务(需要在测试时fine-tune网络)。例如MDNet
- A prediction problem.一个目标检测的任务,例如:ROLO = CNN + LSTM。就是使用LSTM来模拟物体在整个视频中的运动状态。
LTMU主要关注的是外观学习的任务中模型更新的机制,即第二个任务。
而对于第二个任务,其模型按照定位目标框的方式通常分为两类:稀疏采样和密集采样。
稀疏采样——以MDNet为例:
由于第二个会对模型的外观信息进行实时更新,因此我们不妨优先来看一下MDNet:

训练过程:简单来说,对于K个视频序列,该网络会设置K个fc_6层,对于每次迭代,会输入第k个视频序列,去训练相应的第k个fc_6层。这样,一个epoch,就是每个fc_6层被依次训练一次。训练实际上是一个分类问题,这也就意味着具有位置信息的框是训练前就生成的。对于每一个序列,在训练前会根据GT,抽取该视频中的8帧,每一帧会生成4个正框(IoU>0.7)以及12个负框(IoU<0.5),即一个序列生成32个正例和96个负例。每次迭代根据交叉熵损失更新各层。
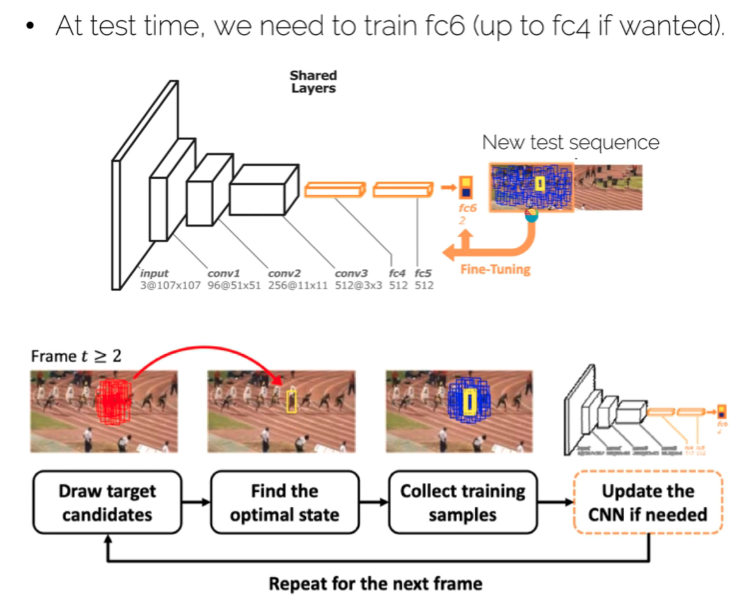
测试过程:在第一帧的框周围生成一系列框,通过上面的分类器得到最优的那个框(得到之后可以通过BBox regression调整一下位置),再用一些正例去更新网络,再次进入下一帧。
而测试过程中,后面框更新是由前一帧框的周边进行随机采样,选取得分最高的那个获得的,也就是稀疏采样。
密集采样——以ATOM为例:
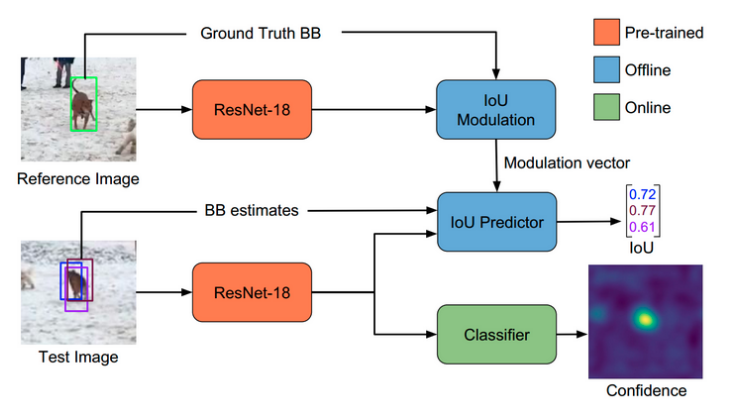
ATOM则是采用“分类即定位”(类似RPN网络),通过前后景分类得到物体可能在的一个置信度分布图得到最高置信度点。之后在这个点周围,按照参考帧(上一帧)的框的大小随机生成一些不同尺度(变化不会特别大)的框,将这些框送入到IoU预测器中,去预测这些框的IoU得分值
IoU预测器:IoUNet的方式是有类别信息的,比如对于狗这个类,该预测期能够得到该框覆盖狗的IoU。而本文的IoU预测器,则是先把模板帧的图和BBox得到IoU Modulation中,获取到相应的向量,最后和当前的框获得相应的IoU。
而LTMU则是针对密集采样的Online部分模型更新的策略进行改进的一个机制,以使得模型能够处理long-term tracking的任务。
下面进入论文解析阶段:
第一部分:引入
对于long-term跟踪器,一般需要满足以下要求:
long-term跟踪器要求具备处理目标频繁消失和出现的能力,即需要有较强的再检测能力。因此,需要能够选择何时进行在线部分的更新,何时不需要。
- 为了表示跟踪错误或者当前帧没有目标存在而拒绝更新这一机制,作者提出了一个指标TNR,即所有跟踪错误的帧不进行更新的比例。像上面ATOM有一定的拒绝更新的能力,ATOM能够根据分类得到置信图来判断是否需要更新。
跟踪器由于存在长时间更新的要求,可能会有目标跟的位置、尺度上的偏差,背景的变化从而可能累计误差,被噪声样本污染模型。因此需要有对抗污染的机制。
本文做的工作:
- 提出一种元更新器指导如何更新在线部分的模型。
- 提出一套long-term tracking的框架。
第二部分:元更新器MU

如上图,定义了一些记号。
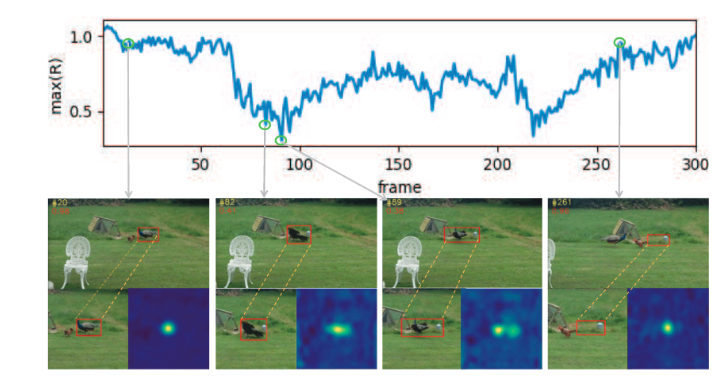
如上图所示,第二个小图中,从人类角度看来,跟的是比较准的,但是其在置信图中,其峰值比较低。同样,在第三张图中出现了双峰值,但其实也是能跟着目标点,而其最大相应值则处于更低的状态(以至于完全可以视为更丢了)。而最后一张图已经更丢了,却有一个较高的相应值。
即有两种问题:
- 目标对但是置信值低
- 目标错但是置信值高
为了解决这两个问题,作者考虑到希望能够设计一个网络,去学习到是否要更新,即所谓的元更新器。为此作者考虑了以下的信息:
几何信息:
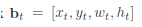
判别信息:
得分(峰值):
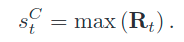
得分图:![image-20201103224503978]
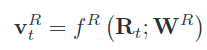
一般会通过一个CNN层提取到整个图的特征,为了应对目标对但置信值低。
外观信息
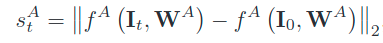
即当前图和第一张图之间的外观差距(度量距离),用来处理目标错但是置信值高的现象。时序信息:利用三级级联的LSTM,将上面三者得到的vector(同时concat前面一段帧数的特征)作为输入,输出是否要进行更新的值。
总体如此图:
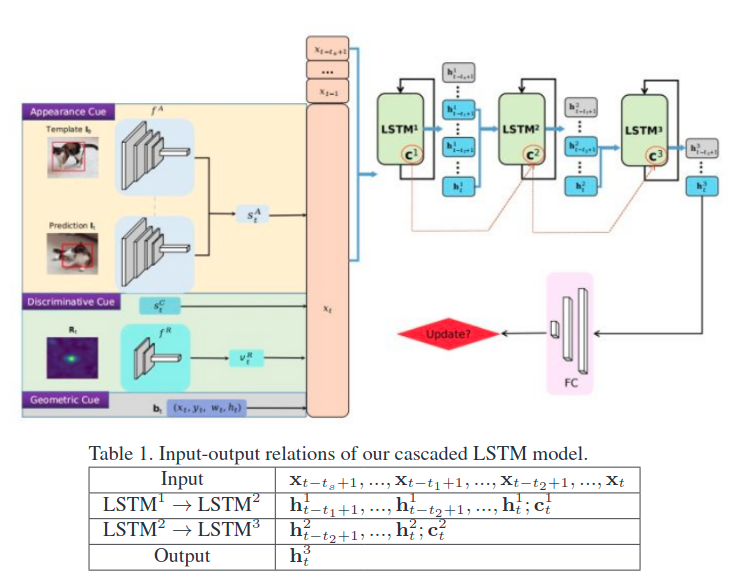
而其中的一些网络,都是与预训练好的。然后对于LSTM级联则是下面这种训练方式:
- 如何训练?

- 先用一般的跟踪器跑一下送入的视频序列,这样能够得到第一遍的每个样本BBOX。前面已经讲了,每次送入到MU中的是[t-ts+1,t]这ts帧的特征。而该二分类网络的GT则是按照

也就是在第一遍的时候,我们获得了训练这个网络的所需内容。于是可以进行第一轮的训练。 - 之后跑的时候,由于存在了MU可以告知是否应该用该BBOX对跟踪器进行训练,因此跟踪器会得到fine-tune,此时再次进行第一步中的方式:跑一遍视频序列,得到可能与上次不尽同的label,再次训练MU。
于是MU就训练完毕。
由上面的MU就可以得到一个长期更新框架。
第三部分:长期跟踪框架
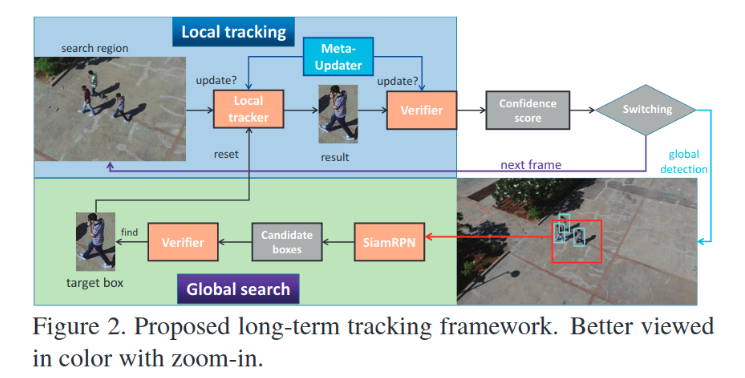
现在,我们拥有了一个一个MU用来控制模型的更新,等于解决了要不要更新问题,而对于啥时候跟丢我们直接采用使用另外一个不同的跟踪器进行确认,因此我们就知道了什么时候应该重新找目标和什么时候应该fine-tune我们的tracker。
对于什么时候应该fine-tune我们的tracker:即上图Local tracking部分,其中local tracker和verifier都是tracker(一般会使用不同的跟踪器)。视频序列输入时,由local tracker控制跟踪,由verifier验证跟的位置对不对,由MU控制更新(对两个跟踪器都要)。然后就能够得到置信度。根据置信度去选择继续fine-tune还是全局搜索,重新寻找目标。
对于什么时候应该重新找目标:即上图Global search部分。当需要重新寻找目标时,会使用一个检测器(如faster-rcnn)得到一些候选框,选取每个候选框的周边区域,然后用SiamRPN利用模板帧和该区域进行搜索,看看是不是能找得到目标,找不到,就直接跳到下一帧,重复该过程。找到了,就进入Local tracking部分。
个人认为该框架有冗余,其实存在优化的地方。
第四部分:结果
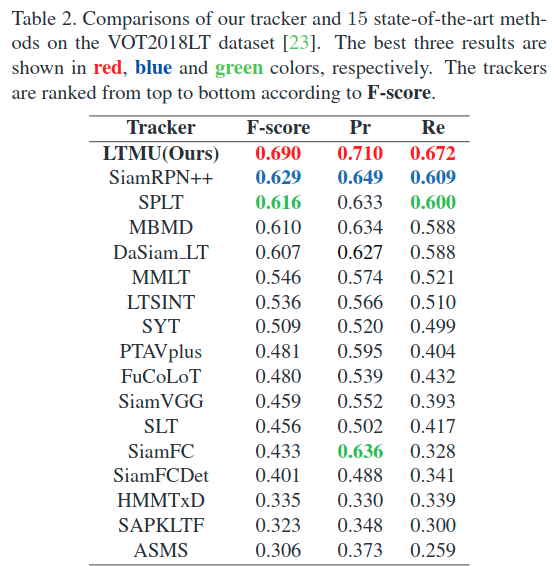
注:作者使用的是自己魔改过的RTMDNet(即表中的MBMD)作为local tracking。
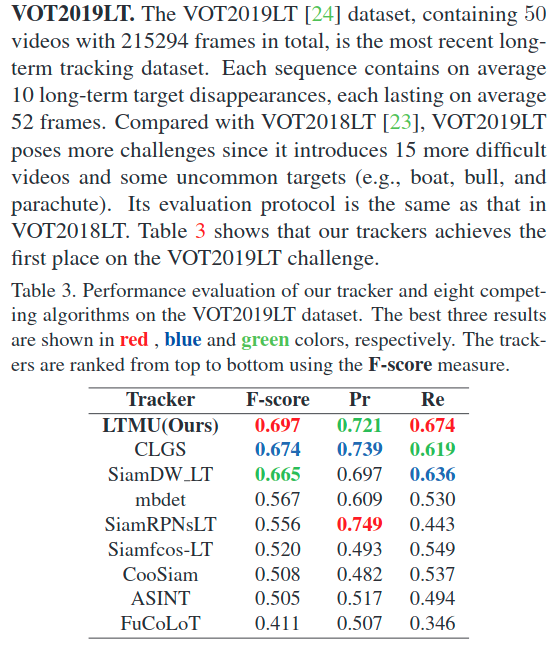
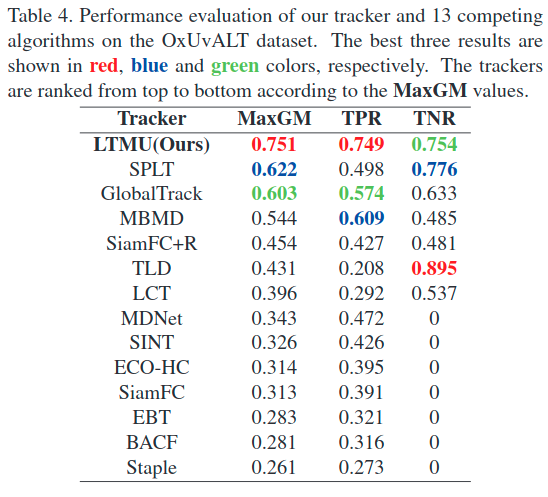
注:TNR是错误帧中不更新的比例,TPR是正确帧更新的比例,MaxGM是前两者权衡
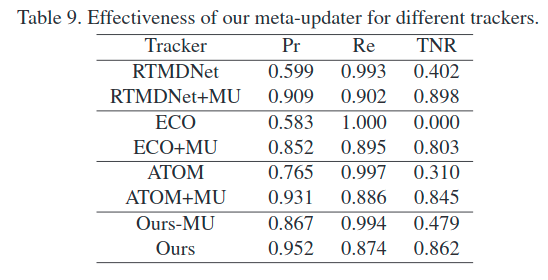
而对于一般的跟踪器,在long-term任务上,MU也能够做到一个比较大的提升:
LTMU论文解析的更多相关文章
- [Network Architecture]Mask R-CNN论文解析(转)
前言 最近有一个idea需要去验证,比较忙,看完Mask R-CNN论文了,最近会去研究Mask R-CNN的代码,论文解析转载网上的两篇博客 技术挖掘者 remanented 文章1 论文题目:Ma ...
- CVPR2020论文解析:实例分割算法
CVPR2020论文解析:实例分割算法 BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation 论文链接:https://arxiv ...
- 人脸真伪验证与识别:ICCV2019论文解析
人脸真伪验证与识别:ICCV2019论文解析 Face Forensics++: Learning to Detect Manipulated Facial Images 论文链接: http://o ...
- 人体姿态和形状估计的视频推理:CVPR2020论文解析
人体姿态和形状估计的视频推理:CVPR2020论文解析 VIBE: Video Inference for Human Body Pose and Shape Estimation 论文链接:http ...
- 视频教学动作修饰语:CVPR2020论文解析
视频教学动作修饰语:CVPR2020论文解析 Action Modifiers: Learning from Adverbs in Instructional Videos 论文链接:https://a ...
- 分层条件关系网络在视频问答VideoQA中的应用:CVPR2020论文解析
分层条件关系网络在视频问答VideoQA中的应用:CVPR2020论文解析 Hierarchical Conditional Relation Networks for Video Question ...
- 慢镜头变焦:视频超分辨率:CVPR2020论文解析
慢镜头变焦:视频超分辨率:CVPR2020论文解析 Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video Super-Resol ...
- CVPR2020论文解析:视觉算法加速
CVPR2020论文解析:视觉算法加速 GPU-Accelerated Mobile Multi-view Style Transfer 论文链接:https://arxiv.org/pdf/2003 ...
- CVPR2020论文解析:视频语义检索
CVPR2020论文解析:视频语义检索 Fine-grained Video-Text Retrieval with Hierarchical Graph Reasoning 论文链接:https:/ ...
随机推荐
- 生成流水号(20060210-0001)的SQL函数
create table t_sql(id int identity(1,1),code char(13),[name] nvarchar(10)) go create function f_crea ...
- 【Azure Redis 缓存 Azure Cache For Redis】Redis出现 java.net.SocketTimeoutException: Read timed out 异常
问题描述 在使用Azure Redis时,遇见Read Timed out异常, Redis的客户端使用的时jedis.问题发生时,执行redis部分指令出错,大部分get指令,set指令能正常执行. ...
- 使用websocket连接(对接)asp.net core signalr
使用通用websocket连接asp.net core signalr 一.背景介绍 signalr的功能很强大,可以为我们实现websocket服务端节省不少的时间.但是可能由于不同的环境,我们在对 ...
- C#一行代码实现(06)跨线程获取控件值,结合BeginInvoke和EndInvoke使用,以DataGridView为例
主要功能 跨线程获取控件值,以DataGridView为例,结合BeginInvoke和EndInvoke使用 一行代码 object cellValue = dataGridView.ExInvok ...
- OpenCV计算机视觉学习(8)——图像轮廓处理(轮廓绘制,轮廓检索,轮廓填充,轮廓近似)
如果需要处理的原图及代码,请移步小编的GitHub地址 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/ComputerVisionPractice 1, ...
- 将字符串反转的 Java 方法
Java中经常会用到将字符串进行反转的时候,程序员孔乙己总结了7种反转方法,如下: //方法1 递归方法 public static String reverse1(String s) { int l ...
- 云计算管理平台之OpenStack Web管理工具dashboard
在上一篇博客中,我们成功的基于两种网络启动虚拟机:这意味着openstack的核心服务都搭建完成,并正常运行着:有关启动虚拟机实例请参考上一篇博客:今天我们来了解下,基于一个web界面图形工具来管理o ...
- python机器学习的开发流程
标准机器学习的开发编程流程 关注公众号"轻松学编程"了解更多. 一.流程 标准机器学习的开发编程流程: 1.获取数据(爬虫.数据加载.业务部门获取) 2.数据建模(摘选样本数据(特 ...
- 我的 Redis 被入侵了
好吧,我也做了回标题党,像我这么细心的同学,怎么可能让服务器被入侵呢? 其实是这样的,昨天我和一个朋友聊天,他说他自己有一台云服务器运行了 Redis 数据库,有一天突然发现数据库里的数据全没了,只剩 ...
- active cab inf文件编写
最近做了一个网页下载控件.主要就是实现ActiveX控件功能. 由于自己是第一次做,不熟悉其过程.中间走了很多弯路.现在把走过得路程记录部分,希望对其他人可以有点用. 首先制作一个你自己的DLL文件. ...