大白话详解大数据hive知识点,老刘真的很用心(2)

前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的内容详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解!
1. hive知识点(2)
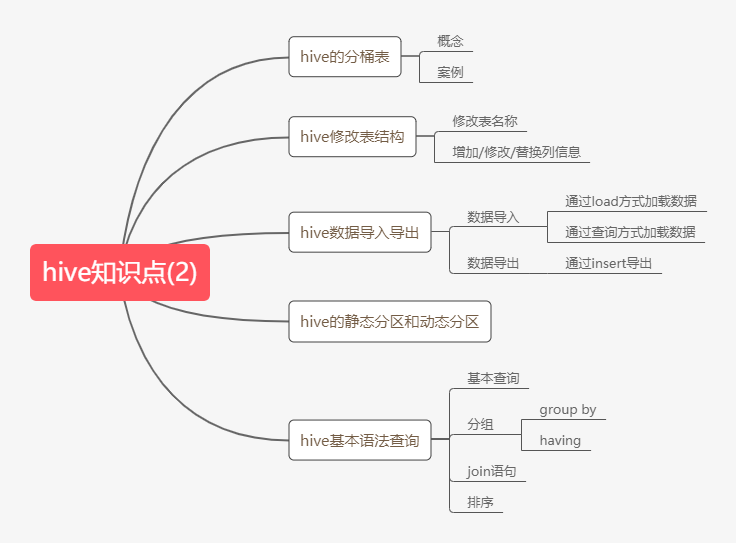
第12点:hive分桶表
hive知识点主要偏实践,很多人会认为基本命令不用记,但是万丈高楼平地起,基本命令无论多基础,都要好好练习,多实践。
在hive中,分桶是相对分区进行更加细粒的划分。其中分区针对的是数据的存储路径,而分桶针对的是数据文件,老刘用两张相关的图对比一下,就能明白刚刚说的区别了。
第一张是表进行分区后变化:
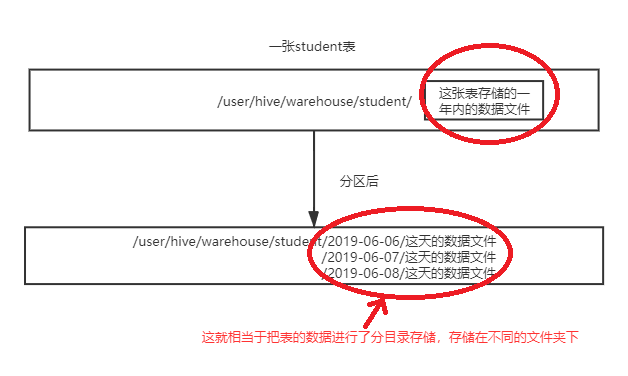 第二张是表进行分桶后的变化:
第二张是表进行分桶后的变化:

根据这两张图,大致可以理解分区和分桶的区别。
那既然看了这两张图,分桶到底是什么,也应该大致清楚了!
什么是分桶?
分桶就是将整个数据内容按照某列属性值取hash值进行区分,具有相同hash值的数据进入到同一个文件中。
举例说明一下:比如按照name属性分为3个桶,就是对name属性值的hash值对3取模,按照取模结果对数据进行分桶。
取模结果为0的数据记录存放到一个文件;
取模结果为1的数据记录存放到一个文件;
取模结果为2的数据记录存放到一个文件;取模结果为3的数据记录存放到一个文件;
至于分桶表的案例太多了,大家自己可搜一个练练手。
第13点:hive修改表结构
这一点,其实没有什么好说的,资料上提到了,老刘也说一说,记住几个命令就行。
修改表的名称
alter table stu3 rename to stu4; 表的结构信息
desc formatted stu4;
第14点:hive数据导入
这部分挺重要的,因为创建表后,要做的事就是把数据导入表中,如果连数据导入的基本命令都不会的话,那绝对是不合格的,这是非常重要的基础!
1、通过load方式加载数据(必须记下来)
通过load方式加载数据
load data local inpath '/kkb/install/hivedatas/score.csv' overwrite into table score3 partition(month='201806');
2、通过查询方式加载数据(必须记下来)
通过查询方式加载数据
create table score5 like score;
insert overwrite table score5 partition(month = '201806') select s_id,c_id,s_score from score;
第15点:hive数据导出
1、insert导出
将查询的结果导出到本地
insert overwrite local directory '/kkb/install/hivedatas/stu' select * from stu; 将查询的结果格式化导出到本地
insert overwrite local directory '/kkb/install/hivedatas/stu2' row format delimited fields terminated by ',' select * from stu; 将查询的结果导出到HDFS上(没有local)
insert overwrite directory '/kkb/hivedatas/stu' row format delimited fields terminated by ',' select * from stu;
第16点:静态分区和动态分区
Hive有两种分区,一种是静态分区,也就是普通的分区。另一种是动态分区。
静态分区:在加载分区表的时候,往某个分区表通过查询的方式加载数据,必须要指定分区字段值。
这里举一个小例子,演示下两者的区别。
1、创建分区表
use myhive;
create table order_partition(
order_number string,
order_price double,
order_time string
)
partitioned BY(month string)
row format delimited fields terminated by '\t'; 2、准备数据
cd /kkb/install/hivedatas
vim order.txt
10001 100 2019-03-02
10002 200 2019-03-02
10003 300 2019-03-02
10004 400 2019-03-03
10005 500 2019-03-03
10006 600 2019-03-03
10007 700 2019-03-04
10008 800 2019-03-04
10009 900 2019-03-04 3、加载数据到分区表
load data local inpath '/kkb/install/hivedatas/order.txt' overwrite into table order_partition partition(month='2019-03'); 4、查询结果数据
select * from order_partition where month='2019-03';
结果为:
10001 100.0 2019-03-02 2019-03
10002 200.0 2019-03-02 2019-03
10003 300.0 2019-03-02 2019-03
10004 400.0 2019-03-03 2019-03
10005 500.0 2019-03-03 2019-03
10006 600.0 2019-03-03 2019-03
10007 700.0 2019-03-04 2019-03
10008 800.0 2019-03-04 2019-03
10009 900.0 2019-03-04 2019-03
动态分区:按照需求实现把数据自动导入到表的不同分区中,不需要手动指定。
如果需要一次性插入多个分区的数据,可以使用动态分区,不用指定分区字段,系统自动查询。
动态分区的个数是有限制的,它一定要从已经存在的表里面来创建。
首先必须说的是,动态分区表一定是在已经创建的表里来创建
1、创建普通标
create table t_order(
order_number string,
order_price double,
order_time string
)row format delimited fields terminated by '\t'; 2、创建目标分区表
create table order_dynamic_partition(
order_number string,
order_price double
)partitioned BY(order_time string)
row format delimited fields terminated by '\t'; 3、准备数据
cd /kkb/install/hivedatas
vim order_partition.txt
10001 100 2019-03-02
10002 200 2019-03-02
10003 300 2019-03-02
10004 400 2019-03-03
10005 500 2019-03-03
10006 600 2019-03-03
10007 700 2019-03-04
10008 800 2019-03-04
10009 900 2019-03-04 4、动态加载数据到分区表中
要想进行动态分区,需要设置参数
开启动态分区功能
set hive.exec.dynamic.partition=true;
设置hive为非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table order_dynamic_partition partition(order_time) select order_number,order_price,order_time from t_order; 5、查看分区
show partitions order_dynamic_partition;
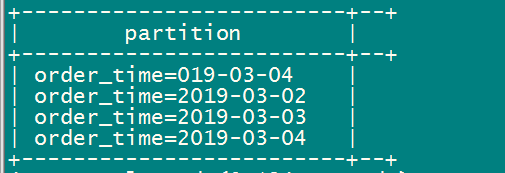
静态分区和动态分区的例子讲述的差不多了,大家好好体会下。
第17点:hive的基本查询语法
老刘之前就说过,hive的基本查询语法是非常重要的,很多人认为压根不用记,需要的时候看看笔记就行,但是在老刘看来,这是非常错误的想法。
有句话说基础不牢,地动山摇,我们最起码要掌握常用的查询语法。
1、基本语法查询:
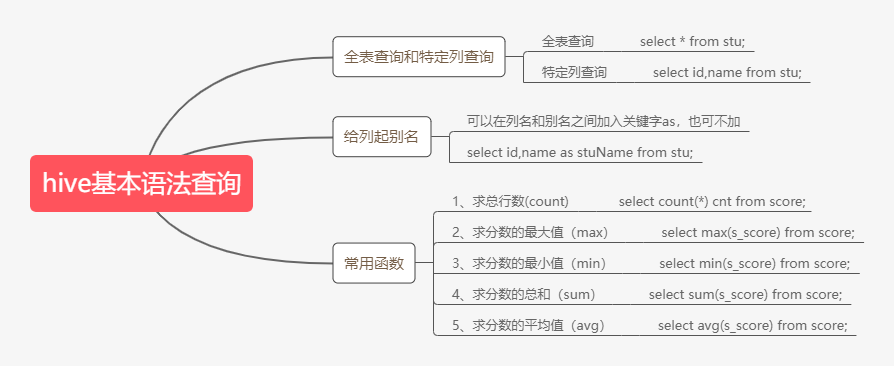
因为limit语句和where语句用的特别多,单独拿出来,大家好好记记!
limit 语句
select * from score limit 5;
接下来是where语句,单独拿出来,是想表达出where语句很重要。我们使用where语句,将不满足条件的行过滤掉。
select * from score where s_score > 60;
2、分组语句
group by语句
group by语句通常和聚合函数一起使用,按照一个或者多个列结果进行分组,然后对每个组执行聚合操作。有个重点必须注意,select的字段,必须在group by字段后面挑选,除了聚合函数max,min,avg。
举两个小例子:
(1)计算每个学生的平均分数
select s_id,avg(s_score) from score group by s_id; (2)计算每个学生最高的分数
select s_id,max(s_score) from score group by s_id;
having语句
先说说having语句和where不同点
① where是针对于表中的列,查询数据;having针对于查询结果中的列,刷选数据。
② where后面不能写分组函数,而having后面可以使用分组函数。
③ having只用于group by分组统计语句。
举两个小例子:
求每个学生的平均分数
select s_id,avg(s_score) from score group by s_id; 求每个学生平均分数大于60的人
select s_id,avg(s_score) as avgScore from score group by s_id having avgScore > 60;
3、join语句

等值join
hive中支持通常的SQL JOIN语句,但是只支持等值连接,不支持非等值连接。
使用join的时候,可以给表起别名,也可以不用起。起别名的好处就是可以简化查询,方便。
根据学生和成绩表,查询学生姓名对应的成绩
select * from stu left join score on stu.id = score.s_id; 合并老师与课程表
select * from teacher t join course c on t.t_id = c.t_id;
内连接inner join
当两个表进行内连接的时候,只有两个表中都存在与连接条件相匹配的数据的时候,数据才会保留下来,并且join默认就是inner join。
select * from teacher t inner join course c on t.t_id = c.t_id;
左外连接left outer join
进行左外连接的时候,join左边表中符合where子句的所有记录将会返回。
查询老师对应的课程
select * from teacher t left outer join course c on t.t_id = c.t_id;
右外连接right outer join
进行右外连接的时候,join右边表中符合where子句的所有记录将会返回。
查询老师对应的课程
select * from teacher t right outer join course c on t.t_id = c.t_id;
4、排序
order by全局排序
使用order by进行排序时候,asc表示升序,这是默认的;desc表示降序。
查询学生的成绩,并按照分数降序排列
select * from score s order by s_score desc ;
2. hive总结
hive知识点(2)就分享的差不多了,这部分偏于实践,需要好好练习。在老刘看来分桶表以及静态分区和动态分区的概念需要好好记住,剩下的就是hive的基本查询操作,由于命令实在太多了,老刘只分享出了一些常用的命令,limit语句,where语句,分组语句,join语句等要熟记于心。
最后,如果觉得有哪里写的不好或者有错误的地方,可以联系公众号:努力的老刘,进行交流。希望能够对大数据开发感兴趣的同学有帮助,希望能够得到同学们的指导。
如果觉得写的不错,给老刘点个赞!
大白话详解大数据hive知识点,老刘真的很用心(2)的更多相关文章
- 大白话详解大数据hive知识点,老刘真的很用心(3)
前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的内容详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解! 1. hive知识点(3) 从这篇文章开始决定进行一些改变,老刘在博客上主要分享 ...
- 大白话详解大数据hive知识点,老刘真的很用心(1)
前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解! 01 hive知识点(1) 第1点:数据仓库的概念 由于hive它是基于had ...
- 用大白话讲大数据HBase,老刘真的很用心(1)
老刘今天复习HBase知识发现很多资料都没有把概念说清楚,有很多专业名词一笔带过没有解释.比如这个框架高性能.高可用,那什么是高性能高可用?怎么实现的高性能高可用?没说! 如果面试官听了你说的,会有什 ...
- 大白话详解大数据HBase核心知识点,老刘真的很用心(2)
前言:老刘目前为明年校招而努力,写文章主要是想用大白话把自己复习的大数据知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的理解! 01 HBase知识点 第6点:HRegionServer架构 为 ...
- 大白话详解大数据HBase核心知识点,老刘真的很用心(3)
老刘目前为明年校招而努力,写文章主要是想用大白话把自己复习的大数据知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的理解! 01 HBase知识点(3) 第13点:HBase表的热点问题 什么是热 ...
- AI时代,还不了解大数据?
如果要问最近几年,IT行业哪个技术方向最火?一定属于ABC,即AI + Big Data + Cloud,也就是人工智能.大数据和云计算. 这几年,随着互联网大潮走向低谷,同时传统企业纷纷进行数字化转 ...
- 我要进大厂之大数据ZooKeeper知识点(2)
01 我们一起学大数据 接下来是大数据ZooKeeper的比较偏架构的部分,会有一点难度,老刘也花了好长时间理解和背下来,希望对想学大数据的同学有帮助,也特别希望能够得到大佬的批评和指点. 02 知识 ...
- 我要进大厂之大数据ZooKeeper知识点(1)
01 让我们一起学大数据 老刘又回来啦!在实验室师兄师姐都找完工作之后,在结束各种科研工作之后,老刘现在也要为找工作而努力了,要开始大数据各个知识点的复习总结了.老刘会分享出自己的知识点总结,一是希望 ...
- 十图详解tensorflow数据读取机制(附代码)转知乎
十图详解tensorflow数据读取机制(附代码) - 何之源的文章 - 知乎 https://zhuanlan.zhihu.com/p/27238630
随机推荐
- Python pip下载过慢解决方案
pip是一个python的包安装与管理工具,安装python时候可以选择是否安装,如果安装了pip可以使用命令查看版本 C:\Users\Vincente λ pip -V pip 19.2.3 fr ...
- 使用Feign发送HTTP请求
使用Feign发送HTTP请求 在往常的 HTTP 调用中,一直都是使用的官方提供的 RestTemplate 来进行远程调用,该调用方式将组装代码冗余到正常业务代码中,不够优雅,因此在接触到 Fei ...
- ssh 方面问题总结
ssh 远程执行命令: https://www.cnblogs.com/youngerger/p/9104144.html ssh免密登录: https://blog.csdn.net/jeikerx ...
- 分享用MathType编辑字母与数学公式的技巧
利用几何画板在Word文档中画好几何图形后,接着需要编辑字母与数学公式,这时仅依靠Word自带的公式编辑器,会发现有很多公式不能编辑,所以应该采用专业的公式编辑器MathType,下面就一起来学习用M ...
- css3系列之box-sizing
box-sizing box-sizing: 俗称ie6 的混杂模式的盒子模型. 首先来了解一下 ie6 的混杂模式,和我们常用的 盒子模型有什么不一样 正常模式下: 我们设置的 width 和 ...
- JPA query between的多种方式(mongodb为例)
背景 JPA+MongoDB查询,给定一段时间范围查询分页结果,要求时间范围包含. Page<Log> findByCtimeBetweenOrderByCtime( LocalDateT ...
- MAC端口被占用的解决方法
html { overflow-x: initial !important } :root { --bg-color: #ffffff; --text-color: #333333; --select ...
- Java数据结构(十)—— 树
树 树的概念和常用术语 常用术语 节点 根节点 父节点 子节点 叶子节点:没有子节点的节点 节点的权:节点的值 路径:节点A到节点B的路径 层 子树 树的高度:最大层数 森林:多颗子树构成森林 二叉树 ...
- Java集合【2】--iterator接口详解
目录 一.iterator接口介绍 二.为什么需要iterator接口 三.iterator接口相关接口 3.1 ListIterator 3.2 SpitIterator 3.2.1 SpitIte ...
- jvm参数与生产配置
堆内存分配:JVM初始分配的内存由-Xms指定,默认是物理内存的1/64JVM最大分配的内存由-Xmx指定,默认是物理内存的1/4默认空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制:空 ...