selenium模拟淘宝登陆,过所有验证
淘宝模拟登陆实现
由于淘宝使用了滑动验证码,需要进行模糊手动滑动,因此考虑使用selenium+chromedriver进行模拟登陆。
淘宝的登陆网址:https://login.taobao.com/member/login.jhtml
项目运行准备:
安装python3开发环境,官网自行下载,博主版本为3.7
安装chrome游览器,下载地址:https://www.google.cn/chrome/
安装selenium模块,在终端中输入pip3 install selenium
安装chromedriver驱动,下载地址:http://npm.taobao.org/mirrors/chromedriver/
注意:
- 在下载chromedriver驱动的时候,需要与chrome游览器的版本尽量保持一致,查看chrome游览器版本方法,在谷歌游览器访问:chrome://settings/help这个网址
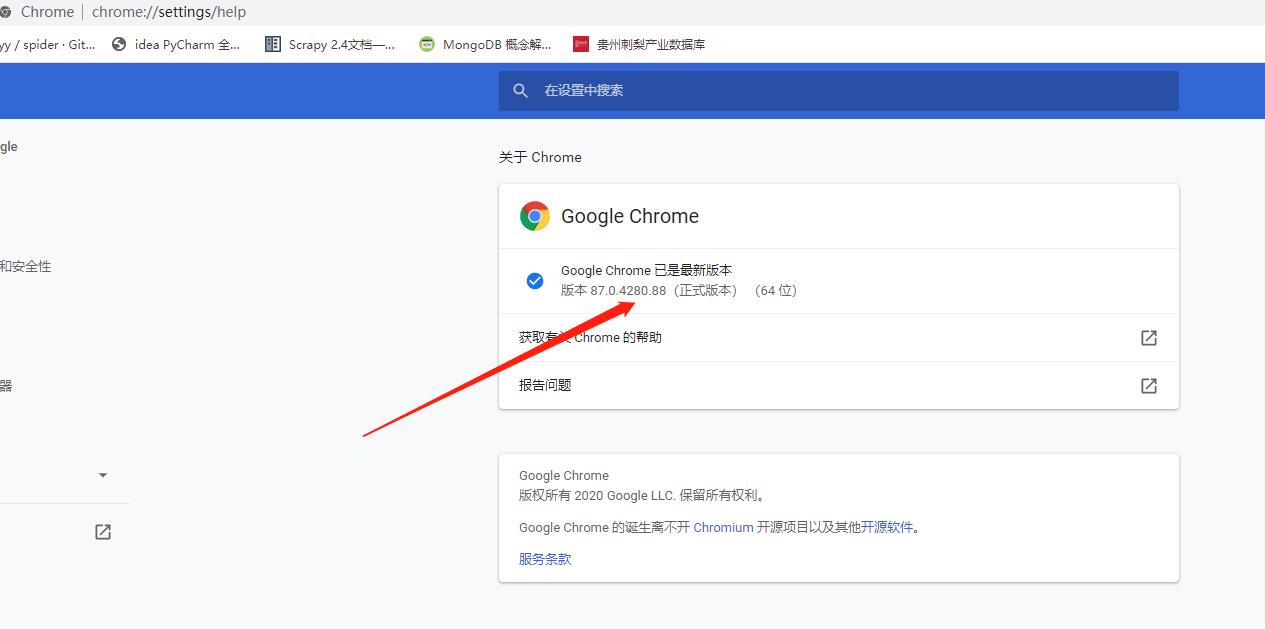
项目需要使用的所有模块
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
初始化selenium并加载chromedriver驱动
class TB(object):
def __init__(self, *args, **kwargs):
"""
初始化游览器版本
"""
option = webdriver.ChromeOptions()
self.webdriver_obj = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=option)
# 跳过阿里滑动验证码对selenium的校验
self.webdriver_obj.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": '''
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
'''
})
封装隐式等待进行xpath定位
由于selenium隐式等待进行xpath定位找不到会报错,项目中多次使用这一段代码,因此对这一部分代码进行封装,封装之后的代码如下:
def xpath(self, xpath_bas):
try:
element = WebDriverWait(self.webdriver_obj, 10).until(
EC.presence_of_element_located((By.XPATH, xpath_bas))
)
except:
element = []
finally:
return element
进行登录标签的定位,输入账号,密码操作
def login(self,username='', password=''):
url = 'https://login.taobao.com/member/login.jhtml'
self.webdriver_obj.get(url)
self.xpath('//*[@id="fm-login-id"]').send_keys(username) # 定位账号输入框,并输入账号
self.xpath('//*[@id="fm-login-password"]').send_keys(password) # 定位密码输入框,并输入密码
self.xpath('//*[@id="login-form"]/div[4]/button').click() # 第一次点击登录按钮
time.sleep(5)
check_yzm_span = self.xpath('//*[@id="nc_1_n1z"]') # 延时定位滑动验证码标签,避免点击登录按钮之后,出现滑动验证码,不需要验证的情况
if bool(check_yzm_span):
print('登录发现滑动验证码')
self.check_yzm(check_yzm_span) # 处理滑动验证码
else:
print('登录未发现滑动验证码')
try:
frame = self.xpath('//*[@id="content"]/div/div[1]/iframe') # 定位iframe标签,由于iframe没有id,name这种唯一的属性,因此只能通过先定位,在切换实现
self.webdriver_obj.switch_to.frame(frame) # 由于手机验证页面出现了页面的嵌套,因此需要进行页面跳转到iframe下
check_phone_button = self.xpath('//*[@id="J_GetCode"]')
print('登录发现手机验证码')
self.check_phone_yzm(check_phone_button) # 处理手机登录验证码
except:
print('登录未发现手机验证码')
finally:
print('登陆成功')
处理滑动验证码
定位到滑块的标签
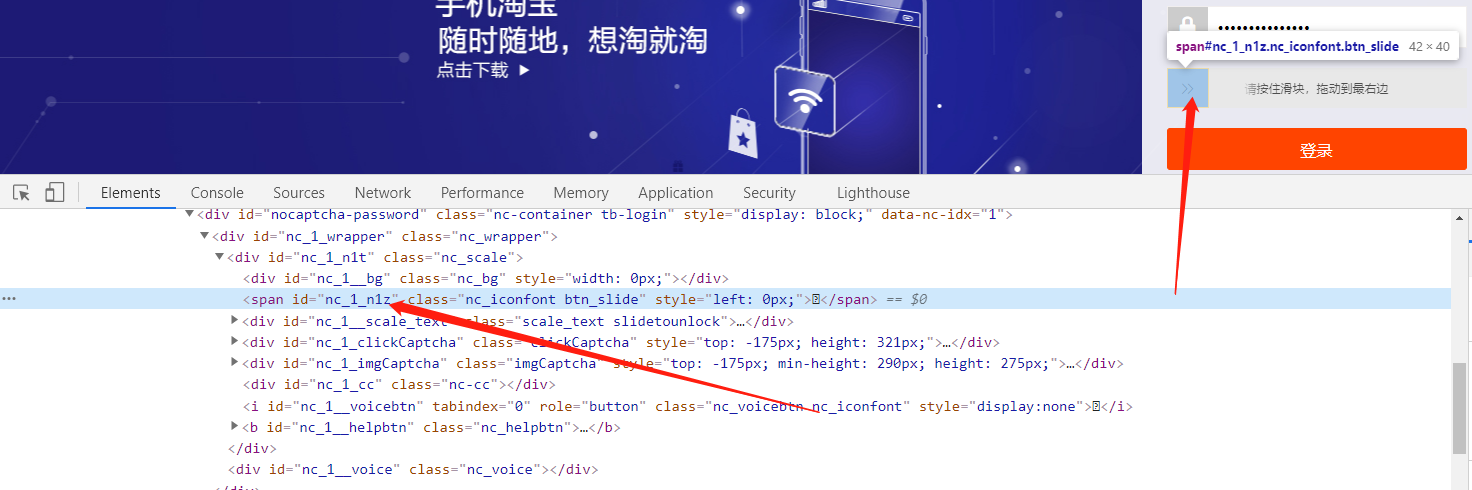
定位滑动槽的标签
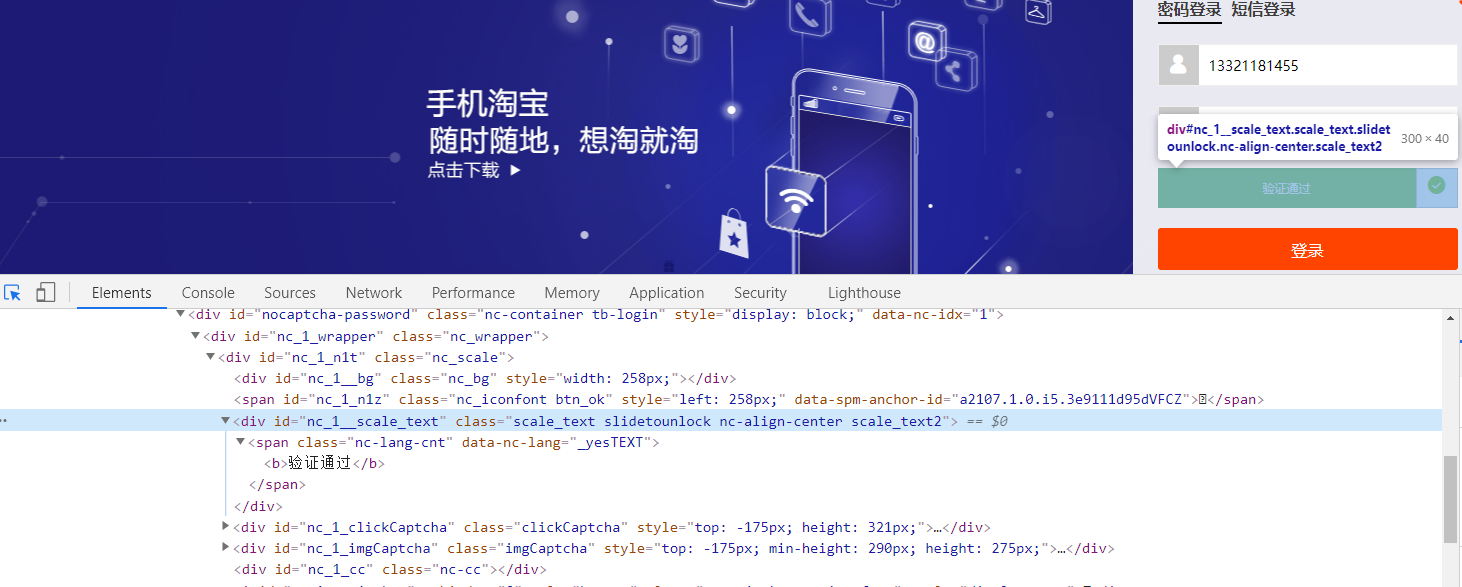
通过定位发现滑动槽的长度是300,滑块的长度是40,因此需要滑动的距离大约是260.
因此可以通过ActionChains动作链实现对滑动的拖动操作,具体代码如下:
def check_yzm(self, check_yzm_span):
"""
处理滑动验证码,没有测试
:param check_yzm_span:
:return:
"""
# 实例化一个动作链关联游览器
action = ActionChains(self.webdriver_obj)
# 使用鼠标动作链进行点击并悬浮
action.click_and_hold(check_yzm_span)
# 滑动验证码
action.move_by_offset(xoffset=258, yoffset=0).perform()
time.sleep(1)
# 再次点击登录按钮
self.xpath('//*[@id="login-form"]/div[4]/button').click()
处理手机验证码
在点击登录之后,淘宝会进行身份验证,就是让你输入手机验证码,然后对验证码进行输入后,才能让你登录成功。
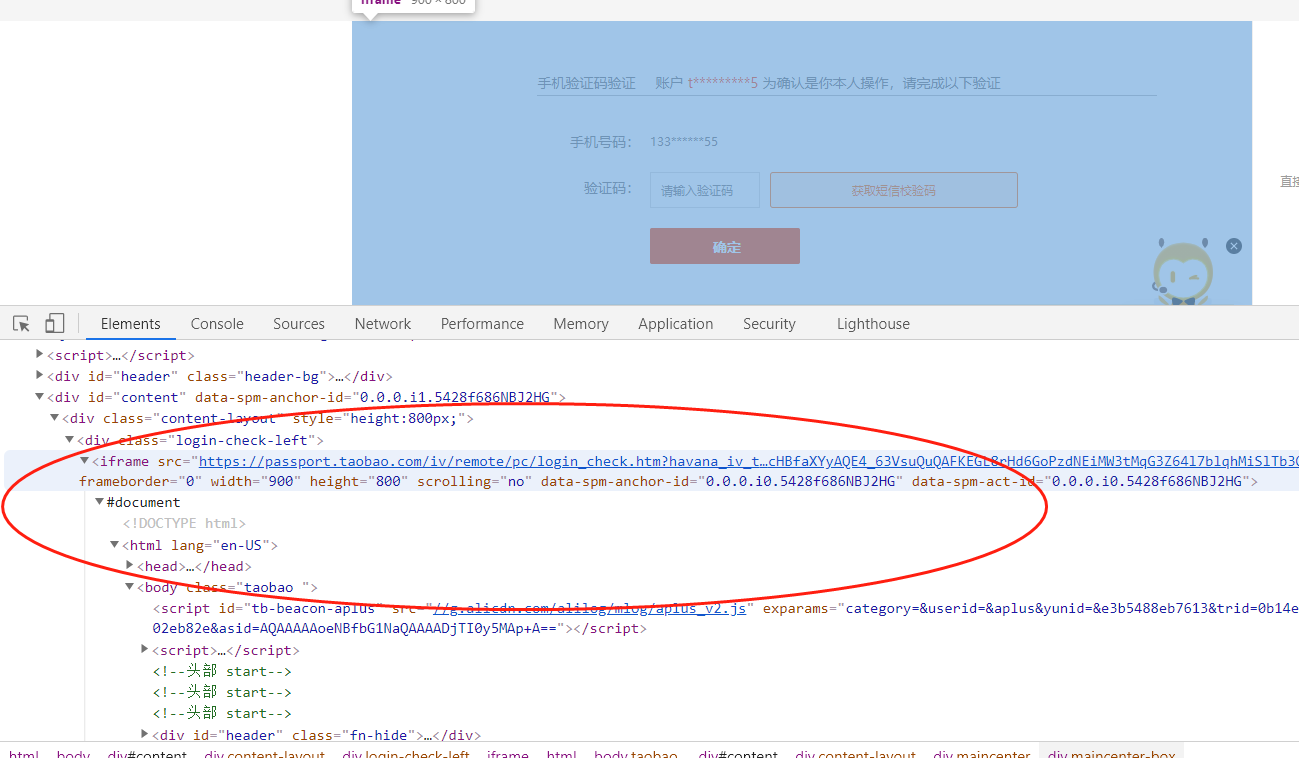
发现,淘宝这个页面出现了页面的嵌套,并且iframe没有id,name这样唯一的属性值,因此只能通过先对iframe标签进行定位,然后通过switch_to进行页面的切换。
切换页面之后,剩下的思路就是点击获取验证码按钮,输入验证码,点击确认按钮。具体实现代码如下:
def check_phone_yzm(self, check_phone_button):
check_phone_button.click()
yzm = input('请输入手机验证码:')
self.xpath('//*[@id="J_Phone_Checkcode"]').send_keys(yzm)
self.xpath('//*[@id="submitBtn"]').click()
最后登陆成功之后的截图如下:
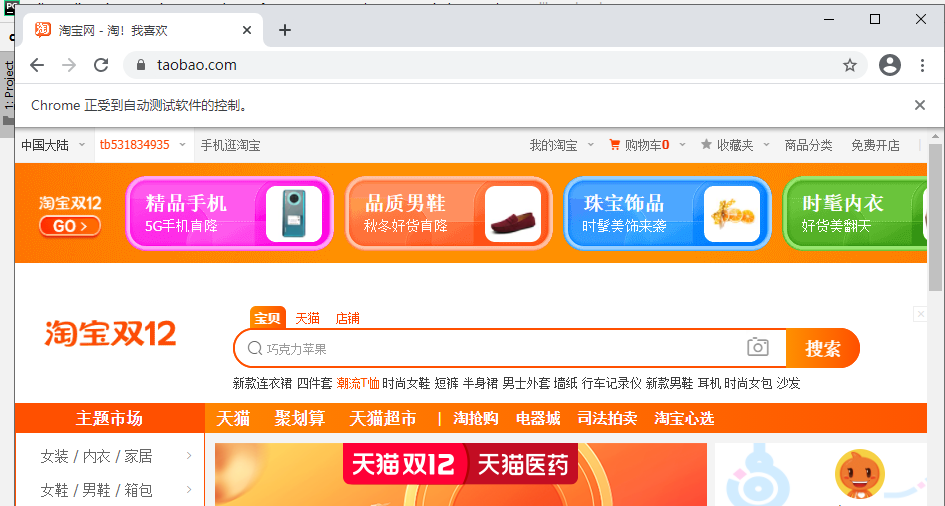
selenium模拟淘宝登陆,过所有验证的更多相关文章
- 【Python】selenium模拟淘宝登录
# -*- coding: utf-8 -*- from selenium import webdriver from selenium.webdriver.common.by import By f ...
- 使用selenium实现模拟淘宝登陆
from selenium import webdriverfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.w ...
- php单点登录之模拟淘宝天猫同步登录
说到单点登录大家都很了解,一个站点登录其他域会自动登录. 单点登录SSO(Single Sign On)的方法有很多,比如:p3p.共享session.共享cookice.第三方OAuth认证. 这里 ...
- selenium实现淘宝的商品爬取
一.问题 本次利用selenium自动化测试,完成对淘宝的爬取,这样可以避免一些反爬的措施,也是一种爬虫常用的手段.本次实战的难点: 1.如何利用selenium绕过淘宝的登录界面 2.获取淘宝的页面 ...
- 模拟淘宝登录和购物车功能:使用cookie记录登录名,下次登录时能够记得上次的登录名,使用cookie模拟购物车功能,使用session记住登录信息并验证是否登录,防止利用url打开网站,并实现退出登录功能
Login <%@ page language="java" contentType="text/html; charset=UTF-8" pageEnc ...
- 【Python】使用Selenium实现淘宝抢单
最近,小明为了达成小姐姐的愿望,在某宝买到心仪的宝贝,再加上又迷上了python,就通过python轻而易举地实现了(个人声明:对Java来说,这并不是背叛). 需求分析&前期准备 需求其实很 ...
- 九、Python+Selenium模拟用QQ登陆腾讯课堂,并提取报名课程(练习)
研究QQ登录规则的话,得分析大量Javascript的加密解密,比较耗时间.自己也是练习很少,短时间成功不了.所以走了个捷径. Selenium是一个WEB自动化测试工具,它运行时会直接实例化出一个浏 ...
- 爬虫实战【8】Selenium解析淘宝宝贝-获取多个页面
作为全民购物网站的淘宝是在学习爬虫过程中不可避免要打交道的一个网站,而是淘宝上的数据真的很多,只要我们指定关键字,将会出现成千上万条数据. 今天我们来讲一下如何从淘宝上获取某一类宝贝的信息,比如今天我 ...
- 模拟淘宝购物,运用cookie,记录登录账号信息,并且记住购物车内所选的商品
1.登录界面 <%@ page language="java" contentType="text/html; charset=UTF-8" pageEn ...
随机推荐
- nginx&http 第三章 ngx http ngx_http_process_request_headers
HTTP 请求行正确处理完成后,针对 HTTP/1.0 及以上版本紧接着要做的就是请求 HEADER 的处理与解析了 /** * 用于处理http的header数据 * 请求头: * Host: lo ...
- 硬盘LBA 和CHS的关系(转)
磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数 l 磁头(head)数:每个盘片一般有上下两面,分别对应1个磁头,共2个磁头:l 磁道(track)数:磁 ...
- python之 《zip,lambda, map》
1.zip 对于zip我们一般都是用在矩阵上 eg: a = [1,2,3] b = ['a', 'b', 'c'] x = zip(a, b) print(x) print(list(x)) 结果是 ...
- Mysql事物与二阶段提交
1.事务的四种特性(ACID) 事务可以是一个非常简单的SQL构成,也可以是一组复杂的SQL语句构成.事务是访问并且更新数据库中数据的一个单元,在事务中的操作,要么都修改,要么都不做修改,这就是事务 ...
- Java编发编程 - 线程池的认识(二)
核心线程池的内部实现 依然参考 JDK 对线程池的支持,各个接口.相关类之间的关系: (1)对于Executors中几个创建线程池方法底层实现: // 创建固定线程数量的线程池 public sta ...
- Hadoop大数据平台之HBase部署
环境:CentOS 7.4 (1708 DVD) 工具:Xshell+Xftp 1. 使用xftp将hbase上传到/usr/local目录下,将其解压并重命名. 2. 配置conf目录下的hbas ...
- 赶紧收藏!这些Java中的流程控制知识你都不知道,你凭什么涨薪?
Java的流程控制 基础阶段 目录: 用户交互Scanner 顺序结构 选择结构 循环结构 break & continue 练习题 1.Scanner对象 之前我们学的基本语法中并没有实现程 ...
- 不会吧!做了这么久开发还有不会NIO的,看看BAT大佬是怎么用的吧
前言 在将NIO之前,我们必须要了解一下Java的IO部分知识. BIO(Blocking IO) 阻塞IO,在Java中主要就是通过ServerSocket.accept()实现的. NIO(Non ...
- 面试必看!凭借着这份 MySQL 高频面试题,我拿到了京东,字节的offer!
前言 本文主要受众为开发人员,所以不涉及到MySQL的服务部署等操作,且内容较多,大家准备好耐心和瓜子矿泉水. 前一阵系统的学习了一下MySQL,也有一些实际操作经验,偶然看到一篇和MySQL相关的面 ...
- FL Studio采样设置之时间拉伸栏
今天小编将带领大家了解一下FL Studio采样设置页面中的时间拉伸栏知识,该栏目包含了和采样音频的时间拉伸相关的设置.其右边是一个时间伸缩方式下拉列表,里面列出了很多种类的伸缩方式,自动方式是默认的 ...