【Spark调优】Shuffle原理理解与参数调优
【生产实践经验】
生产实践中的切身体会是:影响Spark性能的大BOSS就是shuffle,抓住并解决shuffle这个主要原因,事半功倍。
【Shuffle原理学习笔记】
1.未经优化的HashShuffleManager
注:这是spark1.2版本之前,最早使用的shuffle方法,这种shuffle方法不要使用,只是用来对比改进后的shuffle方法。
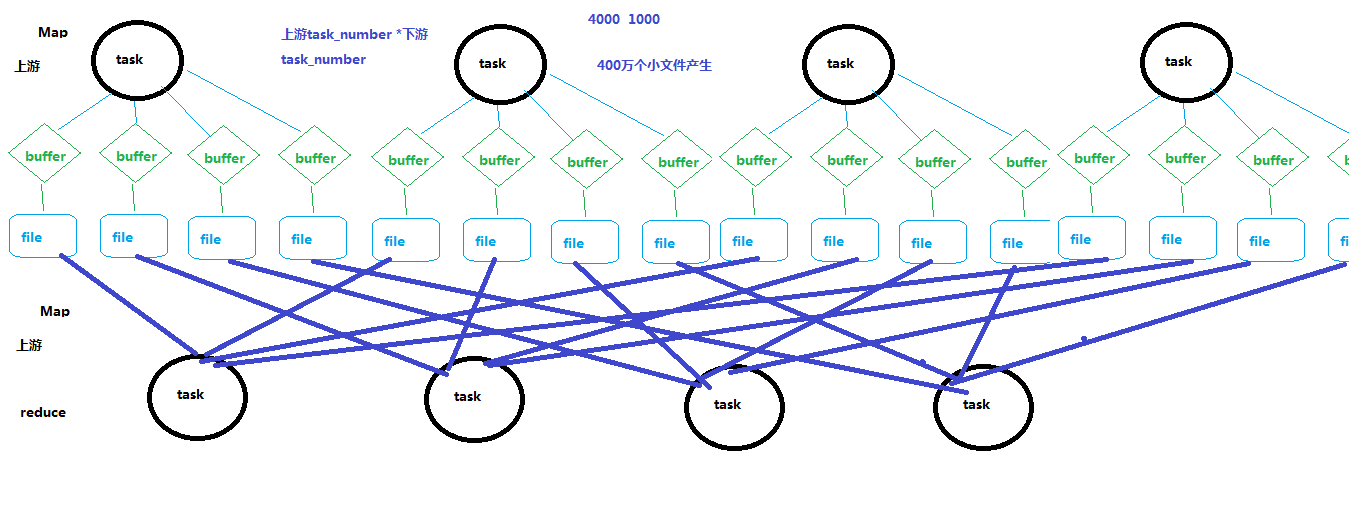
如上图,上游每个task 都输出下游task个数的结果文件,下游每个task去上游task输出的结果文件中获取对应自己的。
问题:
生成文件个数过多,生成和传输 上游task数量 * 下游task数量 个文件。
对应目前spark的参数:
spark.shuffle.manager=hash
spark.shuffle.consolidateFiles=false
2.经过优化以后的HashShufferManager
注:不排序的shuffle推荐使用。
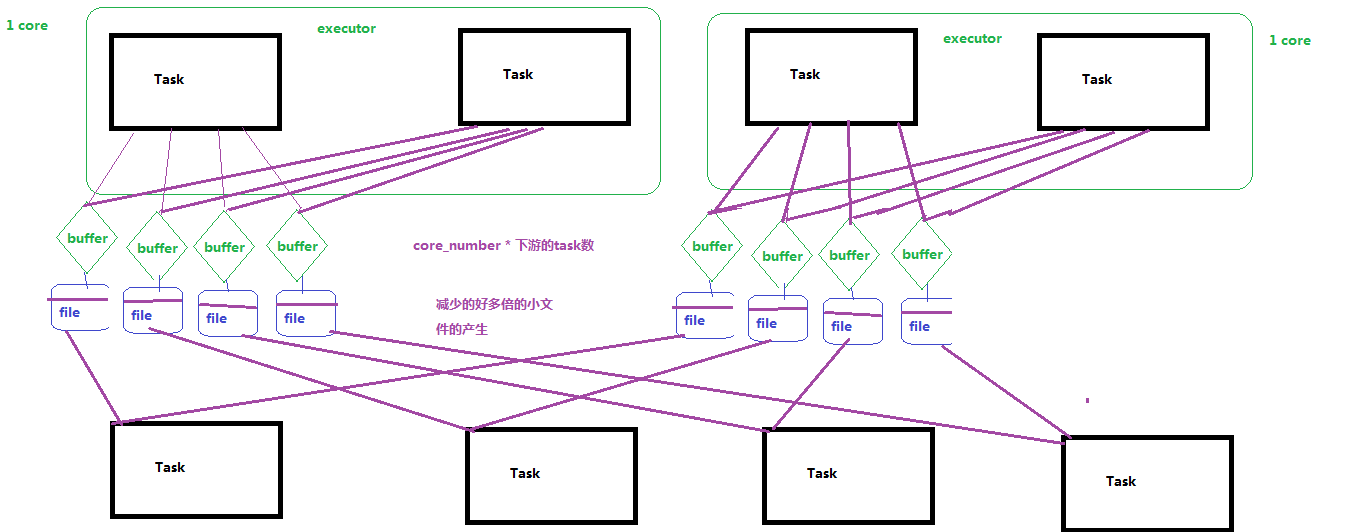
如上图,上游1个Executor所有task顺序输出下游task个数的结果文件,下游每个task去上游task输出的结果文件中获取对应自己的。
减少了中间文件输出,生成和传输 上游executor_num * 下游task数量 个文件。
对应目前spark的参数:
spark.shuffle.manager=hash
spark.shuffle.consolidateFiles=true
3.1 shuffle且有排序需要的SortShuffleManager---普通运行机制
注:排序的shuffle推荐使用。
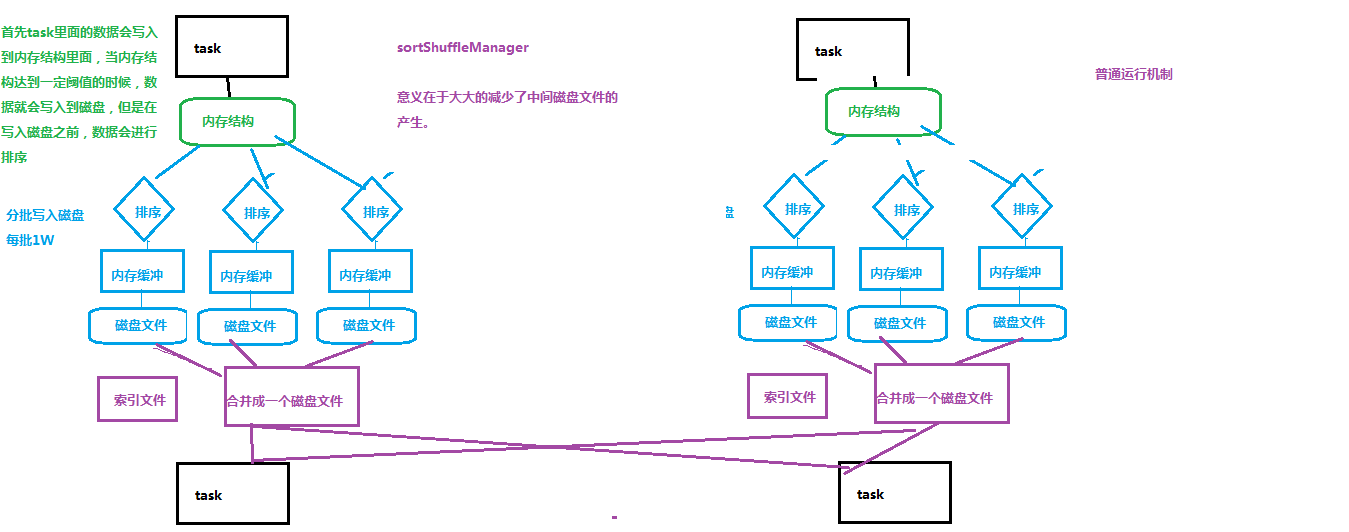
如上图,内存结构达到一定阈值时落盘,落盘前在内存中先排序,分批落盘,每批1万个,最后合并汇总生成成 1个文件+索引文件。
减少了中间文件输出,生成和传输 上游task个数 个文件。
对应目前spark的参数:
spark.shuffle.manager=sort
spark.shuffle.sort.bypassMergeThreshold,默认值200。如果该值配置较小,<= Shuffle read task数量,spark使用该模式
3.2 shuffle但没有排序需要的SortShuffleManager---byPass机制
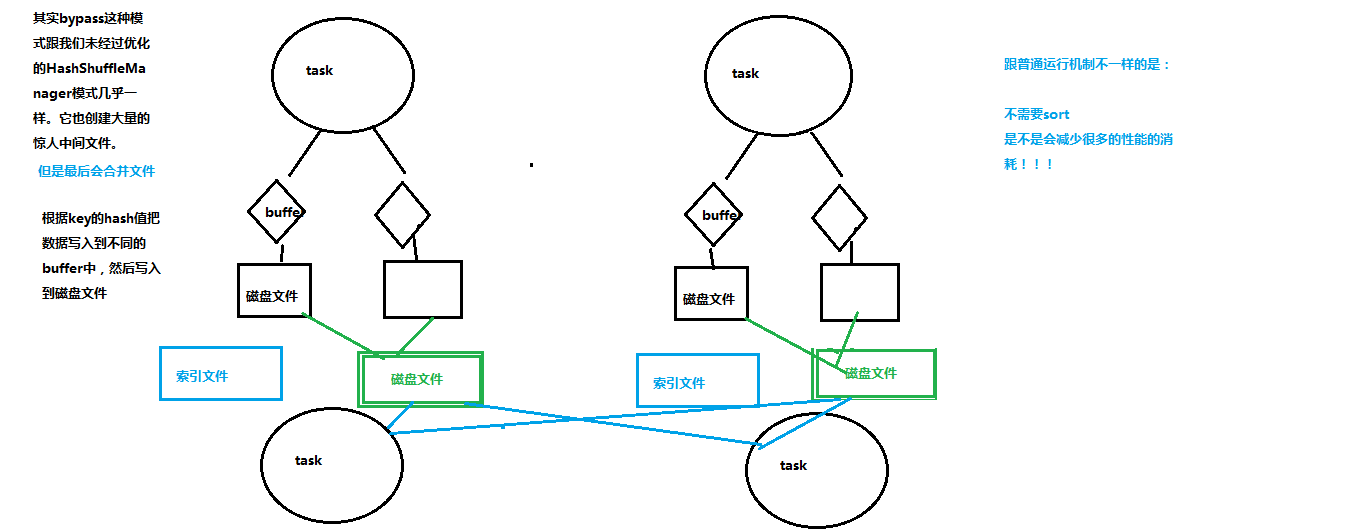
如上图,内存结构达到一定阈值时分批落盘,每批1万个,最后合并汇总生成成 1个文件+索引文件。
减少了中间文件输出,只生成 上游task个数 个文件。
ByPass机制与普通运行模式对比,差别是不排序了,减少了性能损耗。
对应目前spark的参数:
spark.shuffle.manager=sort
spark.shuffle.sort.bypassMergeThreshold,默认值200。如果该值配置较大,> Shuffle read task数量,spark使用该模式
【shuffle相关参数调优】
spark.shuffle.file.buffer
· 默认值:32KB
· 参数说明:该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。
· 调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(例如64KB),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.reducer.maxSizeInFlight
· 默认值:48MB
· 参数说明:该参数用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了下游task每次能够从上游task生成的结果文件拉取多少数据。
· 调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96MB),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.shuffle.io.maxRetries
· 默认值:3
· 参数说明:shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败。
· 调优建议:对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如50次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的shuffle过程,调节该参数可以大幅度提升稳定性。
spark.shuffle.io.retryWait
· 默认值:5秒
· 参数说明:具体解释同上,该参数代表了每次重试拉取数据的等待间隔,默认是5s。
· 调优建议:建议加大间隔时长(比如60秒),以增加shuffle操作的稳定性。
spark.memory.useLegacyMode=true(使用spark1.6版本之前配置模式) 、spark.shuffle.memoryFraction
推荐及默认使用spark.memory.useLegacyMode=false(使用spark1.6及之后版本配置模式) 、spark.memory.fraction + spark.memory.storageFraction
·· 参数说明:该参数代表了Executor内存中,分配给shuffle read task进行聚合操作的内存比例,默认是20%。
· 调优建议:如果内存充足,而且很少使用持久化操作,建议调高这个比例,给shuffle read的聚合操作更多内存,以避免由于内存不足导致聚合过程中频繁读写磁盘。在实践中发现,合理调节该参数可以将性能提升10%左右。
上述这个内存参数配置,详见我的另外一篇博文 【Spark调优】内存模型与参数调优 。
如下几个配置参数,上面已说明过。
spark.shuffle.manager
· 默认值:sort
· 参数说明:该参数用于设置ShuffleManager的类型。Spark 1.5以后,有三个可选项:hash、sort和tungsten-sort。HashShuffleManager是Spark 1.2以前的默认选项,但是Spark 1.2以及之后的版本默认都是SortShuffleManager了。tungsten-sort与sort类似,但是使用了tungsten计划中的堆外内存管理机制,内存使用效率更高。
· 调优建议:由于SortShuffleManager默认会对数据进行排序,因此如果业务逻辑中需要该排序机制的话,则使用默认的SortShuffleManager就可以;而如果业务逻辑不需要对数据进行排序,那么建议参考后面的几个参数调优,通过bypass机制或优化的HashShuffleManager来避免排序操作,同时提供较好的磁盘读写性能。tungsten-sort可能有坑,未使用过。
spark.shuffle.sort.bypassMergeThreshold
· 默认值:200
· 参数说明:当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
· 调优建议:当使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些,大于shuffle read task的数量。那么此时就会自动启用bypass机制,map-side就不会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件,因此shuffle write性能有待提高。
spark.shuffle.consolidateFiles
· 默认值:false
· 参数说明:如果使用HashShuffleManager,该参数有效。如果设置为true,那么就会开启consolidate机制,会大幅度合并shuffle write的输出文件,对于shuffle read task数量特别多的情况下,这种方法可以极大地减少磁盘IO开销,提升性能。
· 调优建议:如果的确不需要SortShuffleManager的排序机制,那么除了使用bypass机制,还可以尝试将spark.shffle.manager参数手动指定为hash,使用HashShuffleManager,同时开启consolidate机制。在实践中尝试过,发现其性能比开启了bypass机制的SortShuffleManager要高出10%~30%。
【Spark调优】Shuffle原理理解与参数调优的更多相关文章
- Spark Shuffle原理、Shuffle操作问题解决和参数调优
摘要: 1 shuffle原理 1.1 mapreduce的shuffle原理 1.1.1 map task端操作 1.1.2 reduce task端操作 1.2 spark现在的SortShuff ...
- 【Spark调优】提交job资源参数调优
[场景] Spark提交作业job的时候要指定该job可以使用的CPU.内存等资源参数,生产环境中,任务资源分配不足会导致该job执行中断.失败等问题,所以对Spark的job资源参数分配调优非常重要 ...
- 【Spark调优】内存模型与参数调优
[Spark内存模型] Spark在一个executor中的内存分为3块:storage内存.execution内存.other内存. 1. storage内存:存储broadcast,cache,p ...
- 【Spark调优】数据本地化与参数调优
数据本地化对于Spark Job性能有着巨大的影响,如果数据以及要计算它的代码是在一起的,那么性能当然会非常高.但是,如果数据和计算它的代码是分开的,那么其中之一必须到另外一方的机器上.移动代码到其匹 ...
- 【Spark篇】---Spark中内存管理和Shuffle参数调优
一.前述 Spark内存管理 Spark执行应用程序时,Spark集群会启动Driver和Executor两种JVM进程,Driver负责创建SparkContext上下文,提交任务,task的分发等 ...
- spark submit参数调优
在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置 ...
- spark性能调优(二) 彻底解密spark的Hash Shuffle
装载:http://www.cnblogs.com/jcchoiling/p/6431969.html 引言 Spark HashShuffle 是它以前的版本,现在1.6x 版本默应是 Sort-B ...
- spark 资源参数调优
资源参数调优 了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了.所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使 ...
- 1,Spark参数调优
Spark调优 目录 Spark调优 一.代码规范 1.1 避免创建重复RDD 1.2 尽量复用同一个RDD 1.3 多次使用的RDD要持久化 1.4 使用高性能算子 1.5 好习惯 二.参数调优 资 ...
随机推荐
- Vue.js连接后台数据jsp页面  ̄▽ ̄
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...
- 百度分享不支持Https的解决方案--本地化
站点自从开启 https 之后 ,百度分享就不能用了!但是又寻找不到类似百度分享的替代品.. 怎么办呢?要如何解决 百度分享不支持https的问题呢, 跟着博主动动手,让你百度分享仍然能在https下 ...
- Python代码的人机大战(循环嵌套)
第一次动手写随笔,记录一下今早的1.5小时努力成果 题目是这样的 : 人和机器进行猜拳游戏写成一个类,首先选择角色:1 曹操 2张飞 3 刘备,然后选择的角色进行猜拳:1剪刀 2石头 3布 玩家输入一 ...
- 二十、Flyweight 享元模式
原理: 代码清单: BigChar public class BigChar { //字符名称 private char charname; //大型字符 # . \n 组成 private Stri ...
- [leetcode]2. Add Two Numbers两数相加
You are given two non-empty linked lists representing two non-negative integers. The digits are stor ...
- python积累二:中文乱码解决方法
根据网上提供的解决方法:添加#coding=utf-8或# -*- coding: utf-8 -*- #coding=utf-8 print "还不行?" 执行结果:还是乱码!: ...
- Maven Nexus3 安装,私服搭建
为啥搭建Maven私服? 如果没有私服,我们所需的所有构件都需要通过maven的中央仓库和第三方的Maven仓库下载到本地,而一个团队中的所有人都重复的从maven仓库下载构件无疑加大了仓库的负载和浪 ...
- 最短路径(SP)问题相关算法与模板
相关概念: 有向图.无向图:有向图的边是双行道,无向图的边是单行道.在处理无向图时,可以把一条无向边看做方向相反的两条有向边. 圈 cycle / 回路 circuit:在相同顶点上开始并结束且长度大 ...
- 3T - A1 = ?
有如下方程:A i = (A i-1 + A i+1)/2 - C i (i = 1, 2, 3, .... n). 若给出A 0, A n+1, 和 C 1, C 2, .....C n. 请编程计 ...
- 64位Redhat系统应用(c++代码)搭建-使用informix和g++编译
这篇博客很有必要写下来,记录我在一个比较原生的Linux系统上搭建一套应用所遇到的各种问题和各种坑. 关于这套应用,算是我离职前的一个项目,不完成的话没有办法交差,同时,这个项目也比较紧,合作行一直在 ...