NodeJS简单爬虫
NodeJS简单爬虫
- 最近一直在追火星的一本书,然后每次都要去网站看,感觉很麻烦,于是,想起用爬虫爬取章节,务实派,说干就干!
爬取思路
- 1、该网站的页面呈现出一定的规律
- 2、使用NodeJS的request模块发起请求
- 3、对获取到的数据进行处理
- 4、使用NodeJS的fs模块将数据写入文件
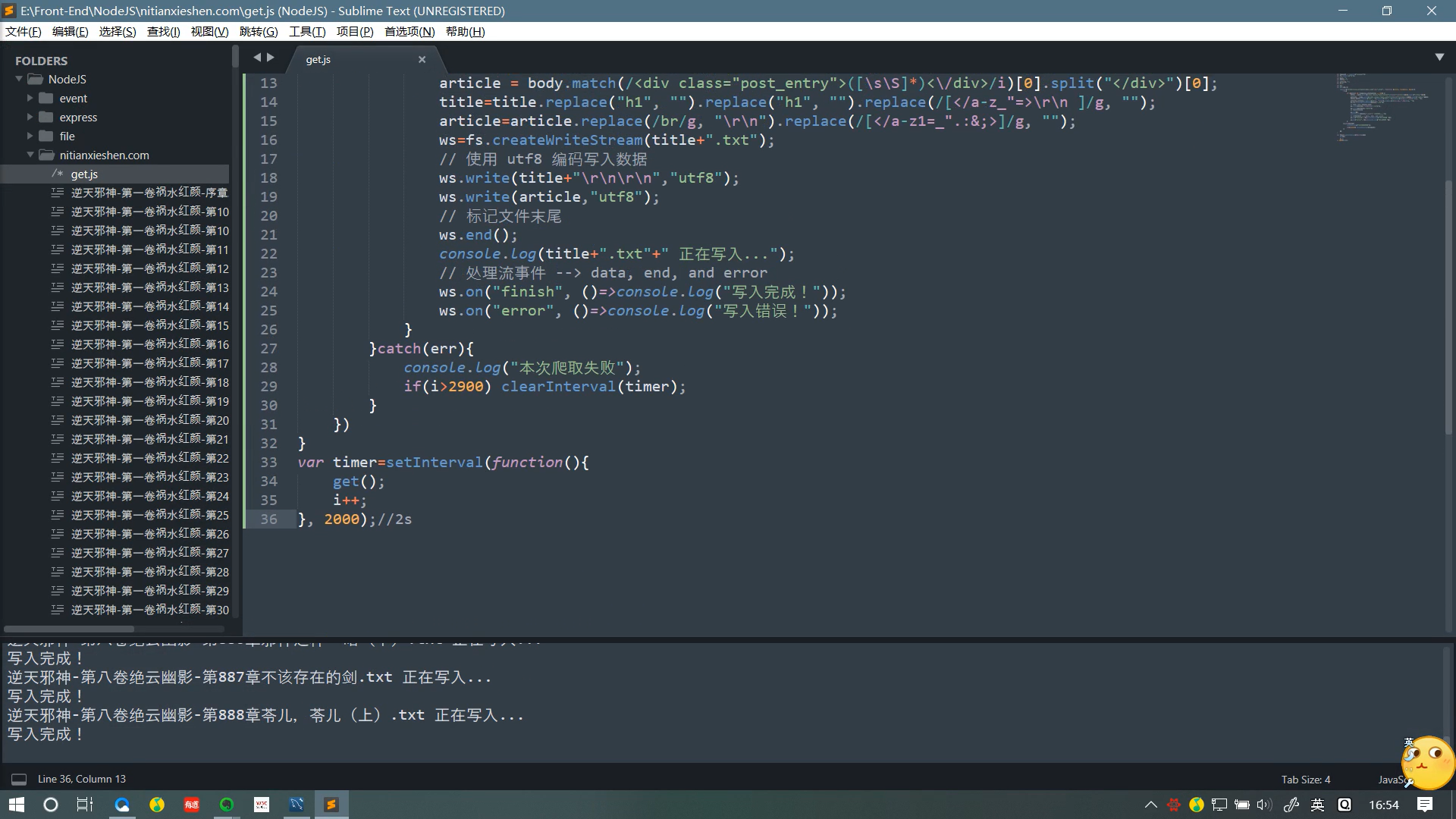
源码说明
//声明需要的模块
var request = require('request');
var fs=require("fs");
//小说章节的标题
var title="";
//小说章节的内容
var article="";
//对应的网页序号
var i=1;
//写入流
var ws;
var get=()=>{
//发起请求
request('http://www.nitianxieshen.com/'+i+'.html', function (error, response, body) {
try{
if (!error && response.statusCode == 200) {
//截取标题与段落
title = body.match(/<div class="post_title">([\s\S]*)<\/h1>/i)[0].split("</div>")[0];
article = body.match(/<div class="post_entry">([\s\S]*)<\/div>/i)[0].split("</div>")[0];
//去除多余的符号
title=title.replace("h1", "").replace("h1", "").replace(/[</a-z_"=>\r\n ]/g, "");
article=article.replace(/br/g, "\r\n").replace(/[</a-z1=_".:&;>]/g, "");
ws=fs.createWriteStream(title+".txt");
ws.write(title+"\r\n\r\n","utf8");
ws.write(article,"utf8");
ws.end();
console.log(title+".txt"+" 正在写入...");
ws.on("finish", ()=>console.log("写入完成!"));
ws.on("error", ()=>console.log("写入错误!"));
}
}catch(err){
//部分章节的序号不连续,不要停止,等待自动爬取完就好,打印出该log后自动无视掉
//好吧,其实后面有一段挺长的不连续的...有兴趣的可以再加个判断条件
console.log("本次爬取失败");
//目前更新的最新章节序号未到2900,确保能爬取完
if(i>2900) clearInterval(timer);
}
})
}
var timer=setInterval(function(){
get();
i++;
}, 2000);//爬取的间隔时间不建议太短,1~2秒比较保险
效果
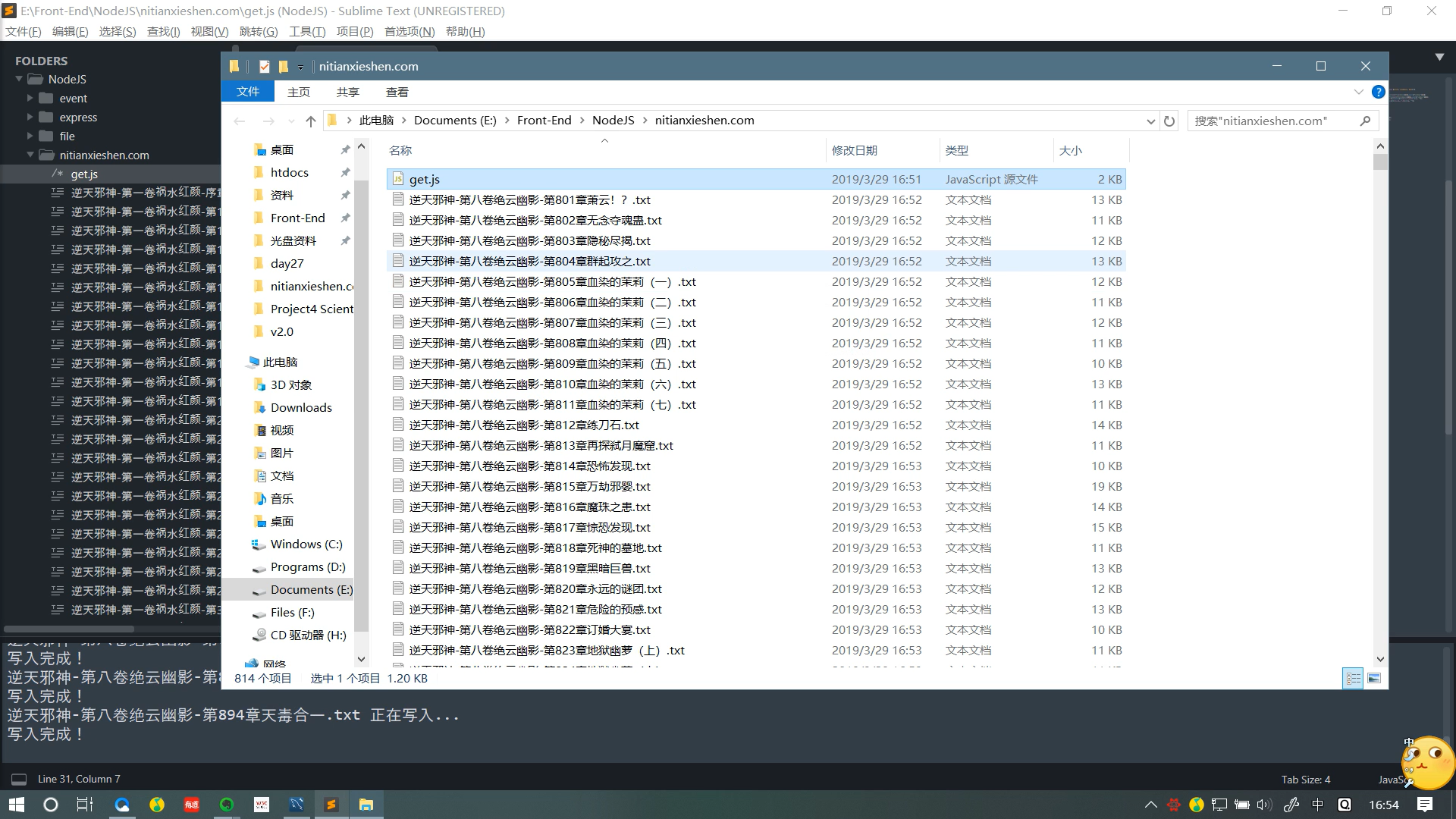
声明
- 本文章仅供学习,爬取的资源请在爬取后的24小时内删除,勿将爬取到的东西商用,喜欢火星的可以支持火星哈。
NodeJS简单爬虫的更多相关文章
- nodejs的简单爬虫
闲聊 好久没写博客了,前几天小颖在朋友的博客里看到了用nodejs的简单爬虫.所以小颖就自己试着做了个爬博客园数据的demo.嘻嘻...... 小颖最近养了条泰日天,自从养了我家 ...
- nodejs实现简单爬虫
nodejs结合cheerio实现简单爬虫 let cheerio = require("cheerio"), fs = require("fs"), util ...
- NodeJS制作爬虫全过程
这篇文章主要介绍了NodeJS制作爬虫的全过程,包括项目建立,目标网站分析.使用superagent获取源数据.使用cheerio解析.使用eventproxy来并发抓取每个主题的内容等方面,有需要的 ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- [Java]使用HttpClient实现一个简单爬虫,抓取煎蛋妹子图
第一篇文章,就从一个简单爬虫开始吧. 这只虫子的功能很简单,抓取到”煎蛋网xxoo”网页(http://jandan.net/ooxx/page-1537),解析出其中的妹子图,保存至本地. 先放结果 ...
- 简单爬虫,突破IP访问限制和复杂验证码,小总结
简单爬虫,突破复杂验证码和IP访问限制 文章地址:http://www.cnblogs.com/likeli/p/4730709.html 好吧,看题目就知道我是要写一个爬虫,这个爬虫的目标网站有 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- python 简单爬虫diy
简单爬虫直接diy, 复杂的用scrapy import urllib2 import re from bs4 import BeautifulSoap req = urllib2.Request(u ...
随机推荐
- spark streaming之三 rdd,job的动态生成以及动态调度
前面一篇讲到了,DAG静态模板的生成.那么spark streaming会在每一个batch时间一到,就会根据DAG所形成的逻辑以及物理依赖链(dependencies)动态生成RDD以及由这些RDD ...
- Apache无法正常启动(配置多个监听端口)
Apache监测多个端口配置: 1.conf->extra->httpd-vhosts.conf 检查配置项是否写错 2.http.conf listen端口是否监听正确 3.环境变量中 ...
- [Java学习]多线程
关于多进程与多线程 使用多进程的目的:提高CPU利用率. 使用多线程的目的:提高应用程序?利用率. 多线程与多进程区别:进程间内存独立:同一个进程的线程间共享"堆内存和方法区内存" ...
- Mobile Computing: the Next Decade论文 cloudlet薄云
1 Introduction “Information at your fingertips anywhere, anytime” has been the driving vision of mob ...
- jenkins源码管理git分支参数化
多个分支来回切换构建时,每次都需要去很多个job里面改分支名称,比较费时,分支参数化后可以只改一处就ok啦 步骤: 1.进入系统管理--系统设置 2.勾选全局变量,然后输入分支变量名和对应的分支名称 ...
- GUI设计和UI设计有什么区别?
首先从技术的角度分析两者处于包含与被包含的关系. GUI=Graphical User Interface,是指在计算机出现后,在屏幕上使用图形界面来帮助(User)与机器打交道用的界面接口,泛指在计 ...
- redis 一些操作命令
# 删除laravel keyredis-cli -h 10.9.103.15 -a password keys "laravel*" | xargs redis-cli -h 1 ...
- 第七次spring会议
昨天我对加密文件进行了解密. 我今天对已完成的代码进行了总体运行,检查运行中出现的bug,在显示便签中出现了过长就无法一次显示完全的情况,没有办法
- python datetime模块用法
1. 创建naive(无时区信息)的datetime对象 import datetime dt_utc = datetime.datetime.utcnow() dt_utc # datetime.d ...
- Knockout.js快速学习笔记
原创纯手写快速学习笔记(对官方文档的二手理解),更推荐有时间的话读官方文档 框架简介(Knockout版本:3.4.1 ) Knockout(以下简称KO)是一个MVVM(Model-View-Vie ...