NodeJS简单爬虫
NodeJS简单爬虫
- 最近一直在追火星的一本书,然后每次都要去网站看,感觉很麻烦,于是,想起用爬虫爬取章节,务实派,说干就干!
爬取思路
- 1、该网站的页面呈现出一定的规律
- 2、使用NodeJS的request模块发起请求
- 3、对获取到的数据进行处理
- 4、使用NodeJS的fs模块将数据写入文件
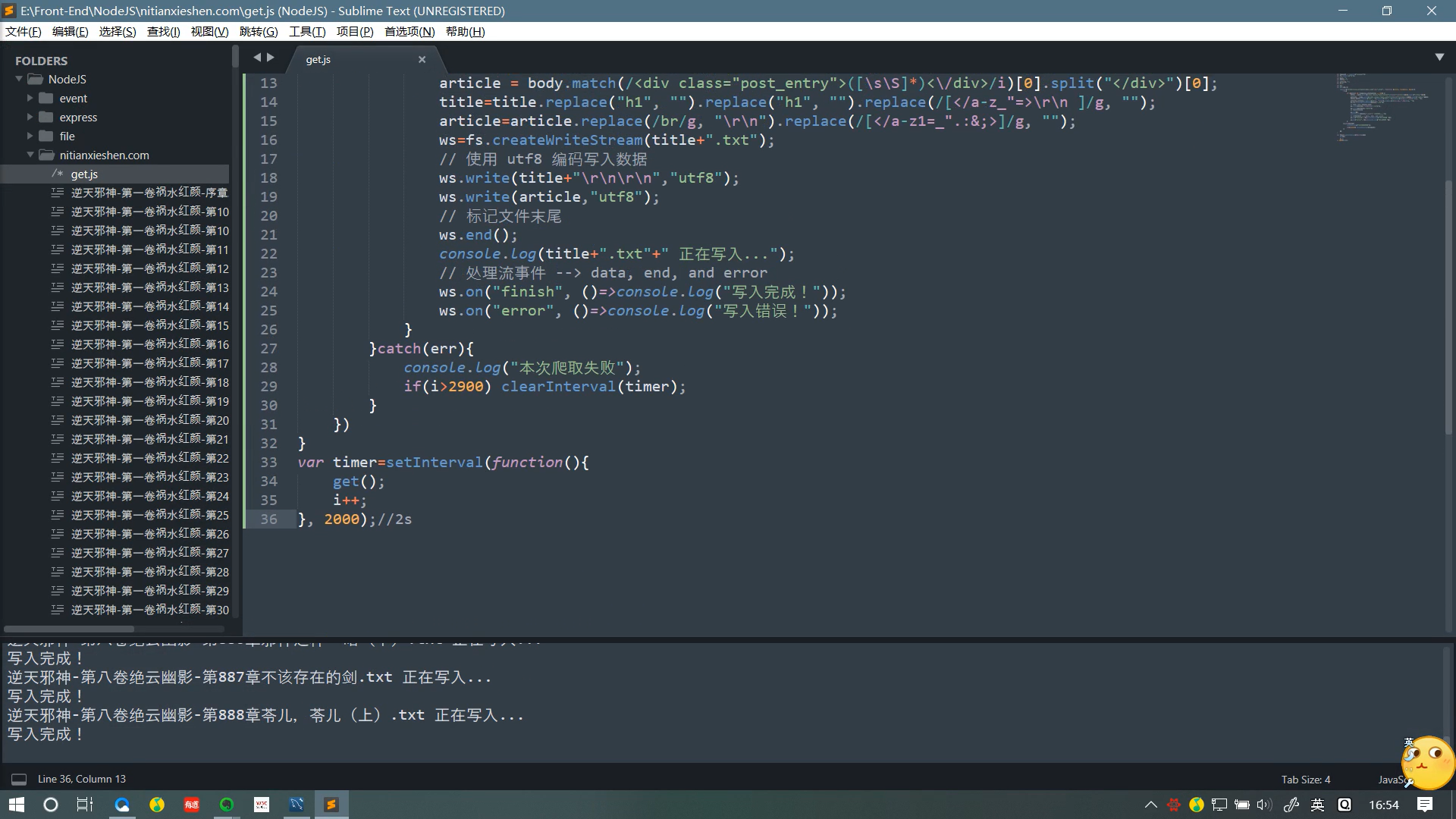
源码说明
//声明需要的模块
var request = require('request');
var fs=require("fs");
//小说章节的标题
var title="";
//小说章节的内容
var article="";
//对应的网页序号
var i=1;
//写入流
var ws;
var get=()=>{
//发起请求
request('http://www.nitianxieshen.com/'+i+'.html', function (error, response, body) {
try{
if (!error && response.statusCode == 200) {
//截取标题与段落
title = body.match(/<div class="post_title">([\s\S]*)<\/h1>/i)[0].split("</div>")[0];
article = body.match(/<div class="post_entry">([\s\S]*)<\/div>/i)[0].split("</div>")[0];
//去除多余的符号
title=title.replace("h1", "").replace("h1", "").replace(/[</a-z_"=>\r\n ]/g, "");
article=article.replace(/br/g, "\r\n").replace(/[</a-z1=_".:&;>]/g, "");
ws=fs.createWriteStream(title+".txt");
ws.write(title+"\r\n\r\n","utf8");
ws.write(article,"utf8");
ws.end();
console.log(title+".txt"+" 正在写入...");
ws.on("finish", ()=>console.log("写入完成!"));
ws.on("error", ()=>console.log("写入错误!"));
}
}catch(err){
//部分章节的序号不连续,不要停止,等待自动爬取完就好,打印出该log后自动无视掉
//好吧,其实后面有一段挺长的不连续的...有兴趣的可以再加个判断条件
console.log("本次爬取失败");
//目前更新的最新章节序号未到2900,确保能爬取完
if(i>2900) clearInterval(timer);
}
})
}
var timer=setInterval(function(){
get();
i++;
}, 2000);//爬取的间隔时间不建议太短,1~2秒比较保险
效果
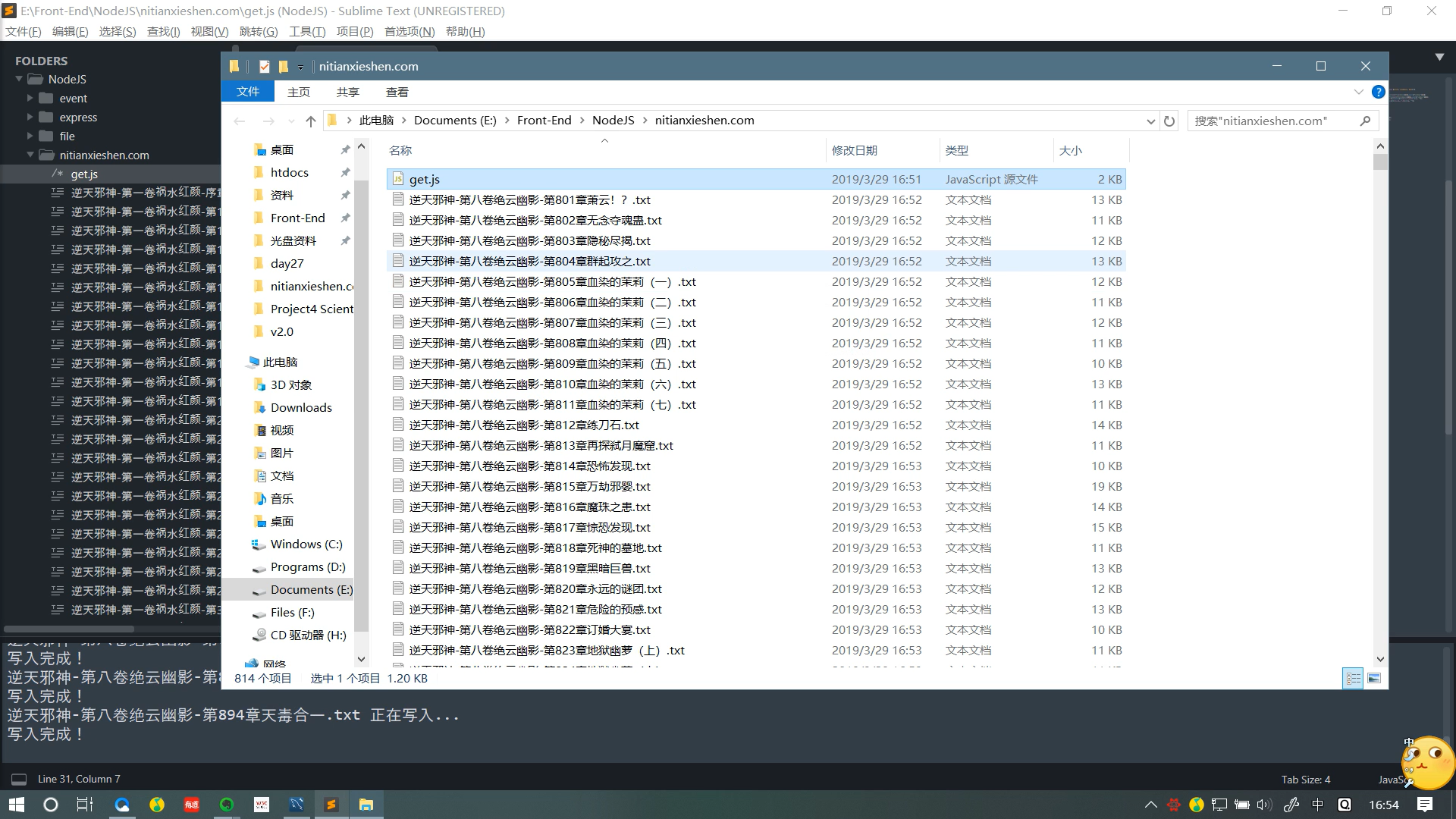
声明
- 本文章仅供学习,爬取的资源请在爬取后的24小时内删除,勿将爬取到的东西商用,喜欢火星的可以支持火星哈。
NodeJS简单爬虫的更多相关文章
- nodejs的简单爬虫
闲聊 好久没写博客了,前几天小颖在朋友的博客里看到了用nodejs的简单爬虫.所以小颖就自己试着做了个爬博客园数据的demo.嘻嘻...... 小颖最近养了条泰日天,自从养了我家 ...
- nodejs实现简单爬虫
nodejs结合cheerio实现简单爬虫 let cheerio = require("cheerio"), fs = require("fs"), util ...
- NodeJS制作爬虫全过程
这篇文章主要介绍了NodeJS制作爬虫的全过程,包括项目建立,目标网站分析.使用superagent获取源数据.使用cheerio解析.使用eventproxy来并发抓取每个主题的内容等方面,有需要的 ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- [Java]使用HttpClient实现一个简单爬虫,抓取煎蛋妹子图
第一篇文章,就从一个简单爬虫开始吧. 这只虫子的功能很简单,抓取到”煎蛋网xxoo”网页(http://jandan.net/ooxx/page-1537),解析出其中的妹子图,保存至本地. 先放结果 ...
- 简单爬虫,突破IP访问限制和复杂验证码,小总结
简单爬虫,突破复杂验证码和IP访问限制 文章地址:http://www.cnblogs.com/likeli/p/4730709.html 好吧,看题目就知道我是要写一个爬虫,这个爬虫的目标网站有 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- python 简单爬虫diy
简单爬虫直接diy, 复杂的用scrapy import urllib2 import re from bs4 import BeautifulSoap req = urllib2.Request(u ...
随机推荐
- 十七、 Observer 观察者设计模式
设计: 代码清单: Observer public interface Observer { void update(NumberGenerator generator); } DigitObserv ...
- hdoj4734(数位dp优化)
题目链接:https://vjudge.net/problem/HDU-4734 题意:定义一个十进制数AnAn-1...A1的value为An*2n-1+...+A1*20,T组样例(<=1e ...
- 信号基础知识--FFT DFT
clc;close all;clear all; f0=10; fs=100; %采样率 t=1/fs:1/fs:2; %共两秒钟,共200个采样点.采样间隔T=1/100 y ...
- 4412 uboot上手
1,了解 print 查看UBOOT软件的环境变量 (变量名=变量) setenv.saveenv setenv abc 100 200 设置 添加一个变量值 修改一个已有的变量 ...
- 通过github安装crawley出现的问题
http://www.cnblogs.com/hbwxcw/p/7086188.html
- 31.Mysql复制
31.Mysql复制复制是指将主数据库的DDL和DML操作通过二进制日志传到从数据库上,然后在从数据库上对重做日志,从而使从库与主库保持同步.Mysql支持一台主库同时向多台从库复制,从库也可以作为其 ...
- Netty学习路线总结
序 之前开过品味性能系列.Mysql学习系列,颇为曲高和寡.都是讲理论,很少有手把手深入浅出的文章.不过确实我就这脾气,文雅点的说法叫做"伪雅",下里巴人叫做"装逼&qu ...
- Java8特性之Lambda、方法引用和Streams
这里涉及三个重要特性: Lambda 方法引用 Streams ① Lambda 最早了解Lambda是在C#中,而从Java8开始,Lambda也成为了新的特性,而这个新的特性的目的,就是为了消除单 ...
- JSP请求重定向与请求转发的区别
请求重定向 客户端行为,response.sendRedirect(),从本质上讲等同于两次请求,前一次请求对象不会保存,地址栏URL会改变: 请求转发 服务器行为,request.getReques ...
- # 2019-2020-3 《Java 程序设计》第四周总结
2019-2020-3 <Java 程序设计>第四周知识总结 第五章:继承 1.定义继承关系的语法结构: [修饰符] class 子类名 extends 父类名 { 类体定义 } 父类中应 ...