使用request爬取拉钩网信息
通过cookies信息爬取
分析header和cookies
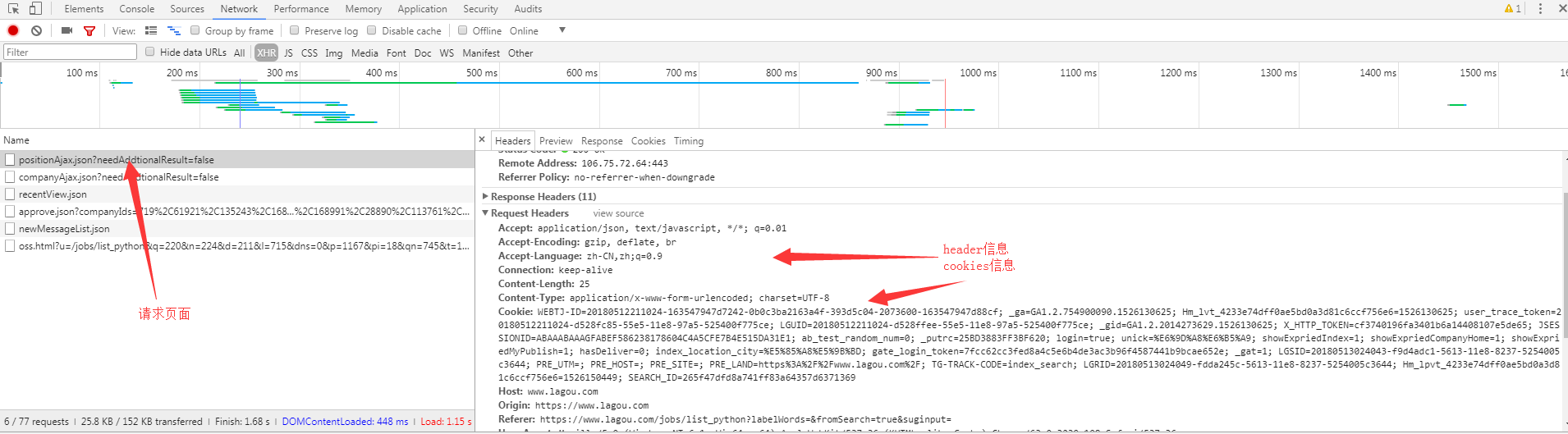
通过subtext粘贴处理header和cookies信息
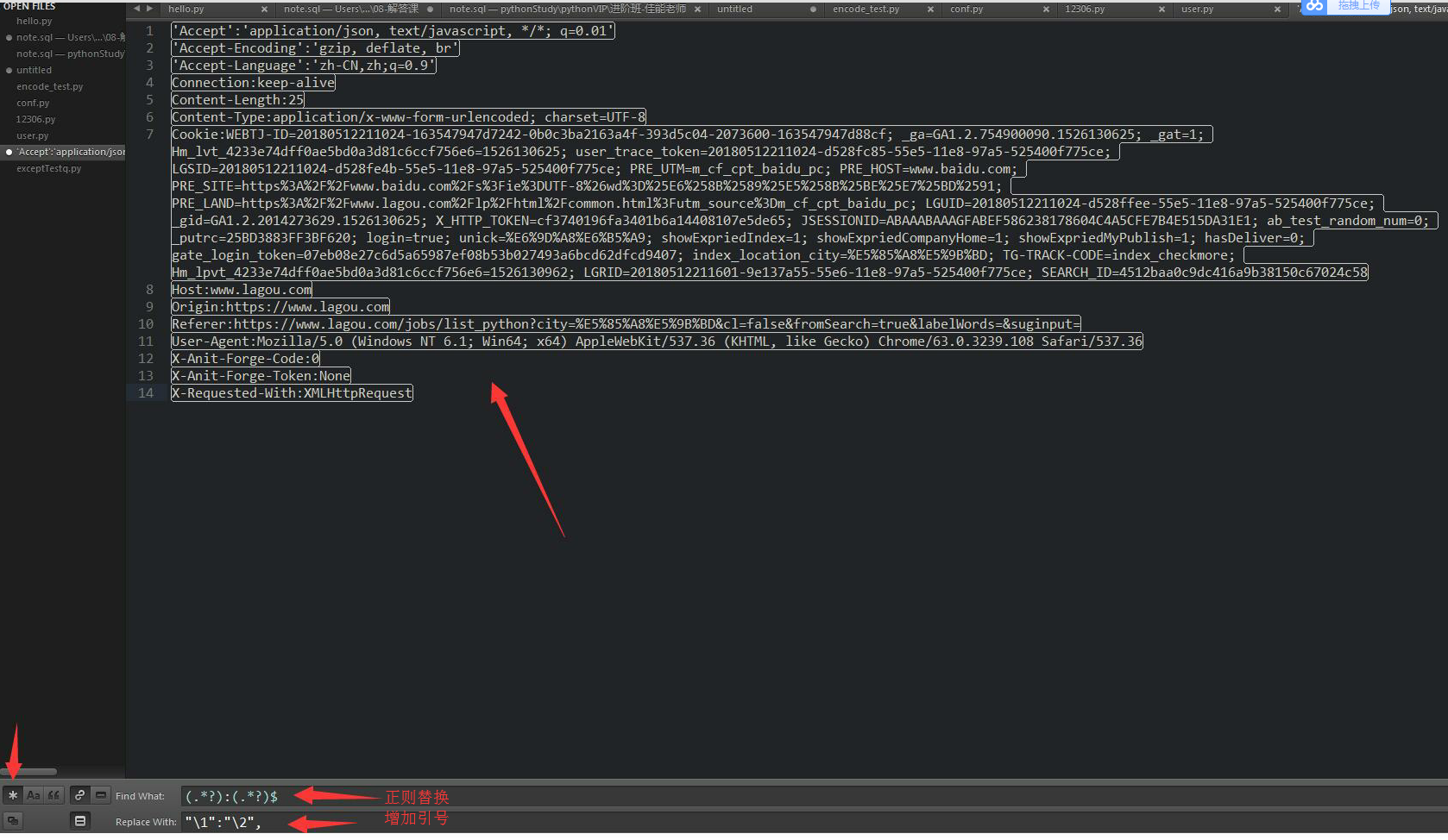
处理后,方便粘贴到代码中

爬取拉钩信息代码
import requests
class LagouSpider(object):
def __init__(self):
self.url ='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
self.headers ={
"Accept":"application/json, text/javascript, */*; q=0.01",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"Connection":"keep-alive",
"Content-Length":"",
"Content-Type":"application/x-www-form-urlencoded; charset=UTF-8",
"Cookie":"", #根据每个人登录信息填写
"Host":"www.lagou.com",
"Origin":"https://www.lagou.com",
"Referer":"https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36",
"X-Anit-Forge-Code":"",
"X-Anit-Forge-Token":"None",
"X-Requested-With":"XMLHttpRequest"
}
self.offset = 0
self.data = {
"first":'true',
"pn":0, # 页数请求
"kd":'python' # 查询关键字
}
self.pos_li = []
self.total = 0
self.pageNo = 0
self.resultSize = 0
def start_request_total(self):
"""
得到拉钩网页数信息
:return:
"""
response = requests.post(url=self.url, headers=self.headers, data=self.data)
html = response.json()
# 得到拉钩工作信息总数
print(html['content']['positionResult'])
self.total = html['content']['positionResult']['totalCount']
# 得到拉钩工作信息每页展示数
self.resultSize = html['content']['positionResult']['resultSize']
# 从0开始
self.pageNo = int(self.total / self.resultSize) if self.total % self.resultSize > 0 else int(self.total / self.resultSize)-1
print(self.pageNo)
print(len(html['content']['positionResult']['result']))
def start_request(self):
"""
得到拉钩每页工作信息
:return:
"""
response = requests.post(url=self.url, headers=self.headers, data=self.data)
html = response.json()
# 得到拉钩工作信息
print(html['content']['positionResult']['result'])
self.pos_li.append(html['content']['positionResult']['result'])
def main(self):
self.start_request_total()
for i in range(self.pageNo):
self.start_request()
print(len(self.pos_li)) # 得到页数
if __name__ == '__main__':
la = LagouSpider()
la.main()
展示结果

使用request爬取拉钩网信息的更多相关文章
- Python3 Scrapy + Selenium + 阿布云爬取拉钩网学习笔记
1 需求分析 想要一个能爬取拉钩网职位详情页的爬虫,来获取详情页内的公司名称.职位名称.薪资待遇.学历要求.岗位需求等信息.该爬虫能够通过配置搜索职位关键字和搜索城市来爬取不同城市的不同职位详情信息, ...
- selelinum+PhantomJS 爬取拉钩网职位
使用selenium+PhantomJS爬取拉钩网职位信息,保存在csv文件至本地磁盘 拉钩网的职位页面,点击下一页,职位信息加载,但是浏览器的url的不变,说明数据不是发送get请求得到的. 我们不 ...
- 爬取拉钩网上所有的python职位
# 2.爬取拉钩网上的所有python职位. from urllib import request,parse import json,random def user_agent(page): #浏览 ...
- python爬虫(三) 用request爬取拉勾网职位信息
request.Request类 如果想要在请求的时候添加一个请求头(增加请求头的原因是,如果不加请求头,那么在我们爬取得时候,可能会被限制),那么就必须使用request.Request类来实现,比 ...
- Python 爬取拉钩网工作岗位
如果拉钩网html页面做了调整,需要重新调整代码 代码如下 #/usr/bin/env python3 #coding:utf-8 import sys import json import requ ...
- ruby 爬虫爬取拉钩网职位信息,产生词云报告
思路:1.获取拉勾网搜索到职位的页数 2.调用接口获取职位id 3.根据职位id访问页面,匹配出关键字 url访问采用unirest,由于拉钩反爬虫,短时间内频繁访问会被限制访问,所以没有采用多线程, ...
- 【实战】用request爬取拉勾网职位信息
from urllib import request import urllib import ssl import json url = 'https://www.lagou.com/jobs/po ...
- 使用nodejs爬取拉勾苏州和上海的.NET职位信息
最近开始找工作,本人苏州,面了几家都没有结果很是伤心.在拉勾上按照城市苏州关键字.NET来搜索一共才80来个职位,再用薪水一过滤,基本上没几个能投了.再加上最近苏州的房价蹭蹭的长,房贷压力也是非常大, ...
- 爬虫基本库request使用—爬取猫眼电影信息
使用request库和正则表达式爬取猫眼电影信息. 1.爬取目标 猫眼电影TOP100的电影名称,时间,评分,等信息,将结果以文件存储. 2.准备工作 安装request库. 3.代码实现 impor ...
随机推荐
- 十八、Memento 备忘录设计模式
原理: 代码清单: Memento public class Memento { int mondey; ArrayList fruits; Memento(int mondey){ this.mon ...
- Mysql 关键字
ADD ALL ALTER ANALYZE AND AS ASC ASENSITIVE BEFORE BETWEEN BIGINT BINARY BLOB BOTH BY CALL CASCADE C ...
- mysql学习笔记--列属性
一.是否为空----null || not null 二.默认值----default 三.自动增长----auto_increment 四.主键----primary key 1. 主键:唯一标识表 ...
- Pandas.Series.dt.dayofweek相关命令
- Python学习笔记-常用内置函数
输出:print() 功能:输出打印 语法:print(*objects, sep=' ', end='\n', file=sys.stdout) 参数:objects----复数,表示可以一次输出多 ...
- 49-2015年第6届蓝桥杯Java B组
1.三角形面积 如图1所示.图中的所有小方格面积都是1. 那么,图中的三角形面积应该是多少呢? 请填写三角形的面积.不要填写任何多余内容或说明性文字. image.png 计算方法: 8 * ...
- RNA-seq数据综合分析教程 AKAP95
https://blog.csdn.net/l_yivs?t=1 RNA-seq数据综合分析教程 2 4,055 A+ 所属分类:Transcriptomics 收 藏 2 RNA-se ...
- linux命令大全(1)
当用户使用linux系统时,其实在和Shell在打交道,当用户发出指令,其实先将这些指令发送给Shell, 然后由Shell将用户的指令翻译后传送给内核,再由内核来控制硬件的工作. 然后内核将硬件的工 ...
- 《C#从现象到本质》读书笔记(九)第11章C#的数据结构
<C#从现象到本质>读书笔记(九)第11章C#的数据结构 C#中的数据结构可以分为两类:非泛型数据结构和泛型数据结构. 通常迭代器接口需要实现的方法有:1)hasNext,是否还有下一个元 ...
- I/O dempo
标准读取写入 package io_stream; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; i ...