leveldb 学习记录(五)SSTable格式介绍
本节主要记录SSTable的结构 为下一步代码阅读打好基础,考虑到已经有大量优秀博客解析透彻 就不再编写了
这里推荐 https://blog.csdn.net/tankles/article/details/7663905
SSTable是Bigtable中至关重要的一块,对于LevelDB来说也是如此,对LevelDB的SSTable实现细节的了解也有助于了解Bigtable中一些实现细节。
本节内容主要讲述SSTable的静态布局结构,SSTable文件形成了不同Level的层级结构,至于这个层级结构是如何形成的我们放在后面Compaction一节细说。本节主要介绍SSTable某个文件的物理布局和逻辑布局结构,这对了解LevelDB的运行过程很有帮助。
LevelDB不同层级都有一个或多个SSTable文件(以后缀.sst为特征),所有.sst文件内部布局都是一样的。上节介绍Log文件是物理分块的,SSTable也一样会将文件划分为固定大小的物理存储块Block,但是两者逻辑布局大不相同,根本原因是:Log文件中的记录是Key无序的,即先后记录的key大小没有明确大小关系,而.sst文件内部则是根据记录的Key由小到大排列的,从下面介绍的SSTable布局可以体会到Key有序是为何如此设计.sst文件结构的关键。 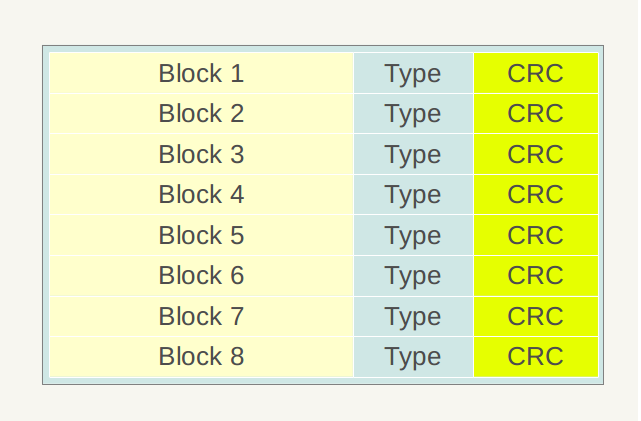
图1 .sst文件的分块结构
图1展示了一个.sst文件的物理划分结构,同Log文件一样,也是划分为固定大小的存储块,每个Block分为三个部分,包括Block、Type和CRC。Block为数据存储区,Type区用于标识Block中数据是否采用了数据压缩算法(Snappy压缩或者无压缩两种),CRC部分则是Block数据校验码,用于判别数据是否在生成和传输中出错。
以上是.sst的物理布局,下面介绍.sst文件的逻辑布局,所谓逻辑布局,就是说尽管大家都是物理块,但是每一块存储什么内容,内部又有什么结构等。图2展示了.sst文件的内部逻辑解释。 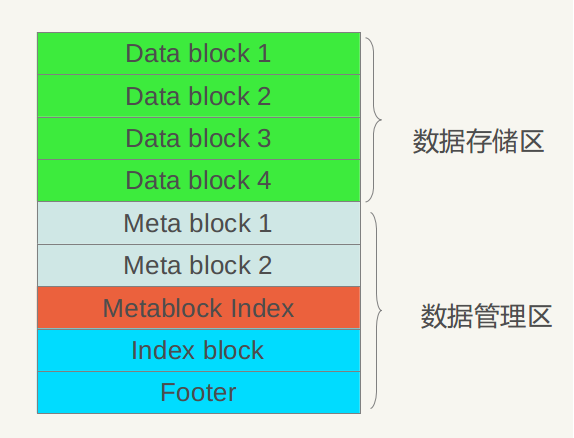
图2 逻辑布局
从图2可以看出,从大的方面,可以将.sst文件划分为数据存储区和数据管理区,数据存储区存放实际的Key:Value数据,数据管理区则提供一些索引指针等管理数据,目的是更快速便捷的查找相应的记录。两个区域都是在上述的分块基础上的,就是说文件的前面若干块实际存储KV数据,后面数据管理区存储管理数据。管理数据又分为四种不同类型:紫色的Meta Block,红色的MetaBlock Index和蓝色的Index block以及一个文件尾部块Footer。
LevelDB 1.2版对于Meta Block尚无实际使用,只是保留了一个接口,估计会在后续版本中加入内容,下面我们看看Index block和文件尾部Footer的内部结构。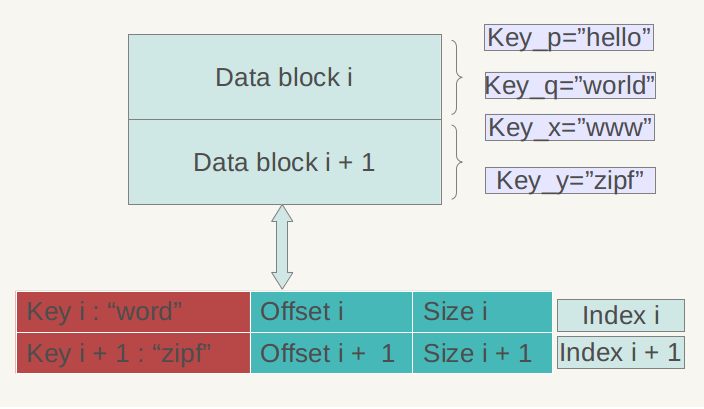
图3 Index block结构
图3是Index block的内部结构示意图。再次强调一下,Data Block内的KV记录是按照Key由小到大排列的,Index block的每条记录是对某个Data Block建立的索引信息,每条索引信息包含三个内容:Data Block中key上限值(不一定是最大key)、Data Block在.sst文件的偏移和大小,以图3所示的数据块i的索引Index i来说:红色部分的第一个字段记载大于等于数据块i中最大的Key值的那个Key,第二个字段指出数据块i在.sst文件中的起始位置,第三个字段指出Data Block i的大小(有时候是有数据压缩的)。后面两个字段好理解,是用于定位数据块在文件中的位置的,第一个字段需要详细解释一下,在索引里保存的这个Key值未必一定是某条记录的Key,以图3的例子来说,假设数据块i 的最小Key=“samecity”,最大Key=“the best”;数据块i+1的最小Key=“the fox”,最大Key=“zoo”,那么对于数据块i的索引Index i来说,其第一个字段记载大于等于数据块i的最大Key(“the best”),同时要小于数据块i+1的最小Key(“the fox”),所以例子中Index i的第一个字段是:“the c”,这个是满足要求的;而Index i+1的第一个字段则是“zoo”,即数据块i+1的最大Key。
文件末尾Footer块的内部结构见图4,metaindex_handle指出了metaindex block的起始位置和大小;inex_handle指出了index Block的起始地址和大小;这两个字段可以理解为索引的索引,是为了正确读出索引值而设立的,后面跟着一个填充区和魔数(0xdb4775248b80fb57)。 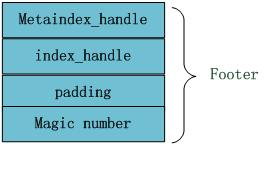
图4 Footer
上面主要介绍的是数据管理区的内部结构,下面我们看看数据区的一个Block的数据部分内部是如何布局的,图5是其内部布局示意图。
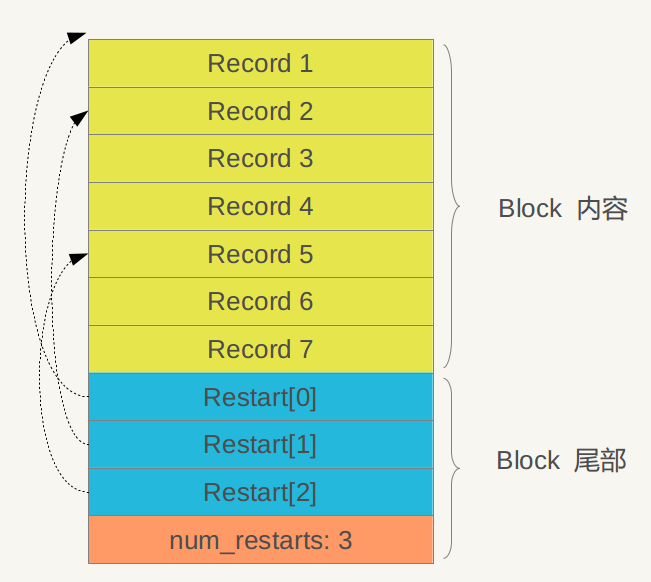
图5 Data Block内部结构
从图中可以看出,其内部也分为两个部分,前面是一个个KV记录,其顺序是根据Key值由小到大排列的,在Block尾部则是一些“重启点”(Restart Point),其实是一些指针,指出Block内容中的一些记录位置。
“重启点”是干什么的呢?简单来说就是进行数据压缩,减少存储空间。我们一再强调,Block内容里的KV记录是按照Key大小有序的,这样的话,相邻的两条记录很可能Key部分存在重叠,比如key i=“the car”,Key i+1=“the color”,那么两者存在重叠部分“the c”,为了减少Key的存储量,Key i+1可以只存储和上一条Key不同的部分“olor”,两者的共同部分从Key i中可以获得。记录的Key在Block内容部分就是这么存储的,主要目的是减少存储开销。“重启点”的意思是:在这条记录开始,不再采取只记载不同的Key部分,而是重新记录所有的Key值,假设Key i+1是一个重启点,那么Key里面会完整存储“the color”,而不是采用简略的“olor”方式。但是如果记录条数比较多,随机访问一条记录,需要从头开始一直解析才行,这样也产生很大的开销,所以设置了多个重启点,Block尾部就是指出哪些记录是这些重启点的。 
在Block内容区,每个KV记录的内部结构是怎样的?图6给出了其详细结构,每个记录包含5个字段:key共享长度,key非共享长度,value长度,key非共享内容,value内容。比如上面的“the car”和“the color”记录,key共享长度5;key非共享长度是4;而key非共享内容则实际存储“olor”;value长度及内容分别指出Key:Value中Value的长度和存储实际的Value值。
上面讲的这些就是.sst文件的全部内部奥秘。
原文:https://blog.csdn.net/tankles/article/details/7663905?utm_source=copy
leveldb 学习记录(五)SSTable格式介绍的更多相关文章
- leveldb 学习记录(七) SSTable构造
使用TableBuilder构造一个Table struct TableBuilder::Rep { // TableBuilder内部使用的结构,记录当前的一些状态等 Options options ...
- leveldb 学习记录(六)SSTable:Block操作
block结构示意图 sstable中Block 头文件如下: class Block { public: // Initialize the block with the specified con ...
- leveldb 学习记录(三) MemTable 与 Immutable Memtable
前文: leveldb 学习记录(一) skiplist leveldb 学习记录(二) Slice 存储格式: leveldb数据在内存中以 Memtable存储(核心结构是skiplist 已介绍 ...
- leveldb 学习记录(四) skiplist补与变长数字
在leveldb 学习记录(一) skiplist 已经将skiplist的插入 查找等操作流程用图示说明 这里在介绍 下skiplist的代码 里面有几个模块 template<typenam ...
- leveldb 学习记录(四)Log文件
前文记录 leveldb 学习记录(一) skiplistleveldb 学习记录(二) Sliceleveldb 学习记录(三) MemTable 与 Immutable Memtablelevel ...
- leveldb 学习记录(八) compact
随着运行时间的增加,memtable会慢慢 转化成 sstable. sstable会越来越多 我们就需要进行整合 compact 代码会在写入查询key值 db写入时等多出位置调用MaybeSche ...
- Ansible学习记录五:PlayBook学习
0.介绍 Playbooks 是 Ansible 管理配置.部署应用和编排的语言,可以使用 Playbooks 来描述你想在远程主机执行的策略或者执行的一组步骤过程等 类似于一组任务集,定义好像项目, ...
- Linux 学习记录 五(软件的安装升级).
一.gcc gcc是Linux上面最标准的C语言的编译程序,用来源代码的编译链接. gcc -c hello.c 编译产生目标文件hello.o gcc -O hello.c 编译产生目标文件,并进行 ...
- leveldb 学习记录(一) skiplist
leveldb LevelDb是一个持久化存储的KV系统,并非完全将数据放置于内存中,部分数据也会存储到磁盘上. 想了解这个由谷歌大神编写的经典项目. 可以从数据结构以及数据结构的处理下手,也可以从示 ...
随机推荐
- pyqt5在xp下的配置
qt支持库得下载,pip的不行, designer在这个里面 https://sourceforge.net/projects/pyqt/files/PyQt5/PyQt-5.4.1/ python只 ...
- lavarel mongo 操作
本人使用环境 Ubuntu 18.04 LTS php7.2 lavarel5.5 mongodb的安装 mongodb 服务的安装 这个链接中有最全面最新的安装文档 https://docs ...
- 一些有用的Java学习资料
Better Java,一些好的Java实践 Google Java Style Guide 30个Java编程技巧 JDK8新增语法特性简介,对Java8中新增的函数接口.Lambda表达式.方法引 ...
- windows环境python2.7安装MySQLdb
我电脑是64位,并且安装python不是默认路径,使用pip和mysql-python的exe文件安装都失败了. 后在网上找到一种安装方法,记录下. 确保安装了wheel,我的2.7默认安装了 pip ...
- shell脚本大小写转换
几个方法 1.tr命令 2.sed替换 3.awk的tolower() toupper() 4.perl语言 详见 http://blog.51cto.com/wangxiaoyu/197623 L ...
- sqlserver 带输出参数的存储过程的创建与执行
创建 use StudentManager go if exists(select * from sysobjects where name='usp_ScoreQuery4') drop proce ...
- 刘志梅 201771010115 《面向对象程序设计(java)》 第九周学习总结
实验九 异常.断言与日志 实验时间 2018-10-25 1.实验目的与要求 (1) 程序中会出现的错误:用户输入错误.设备错误.代码错误.物理限制. 在Java程序设计语言中,异常对象都是派生于Th ...
- css3兼容性检测工具
1. Modernizr 会在Modernizr 会在页面加载后立即检测特性:然后创建一个包含检测结果的 JavaScript 对象,同时在 html 元素加入方便你调整 CSS 的 class ...
- CountDownLatch两种用法
1.当前线程等待其他线程执行完毕后在执行. 2.模拟高并发场景. 在多线程编程里,CountDownLatch是一个很好的计数器工具. 常用的两个方法: 1.计数器减一 public void cou ...
- Dubbo源码分析
Dubbo源码分析1 Dubbo源码分析2 dubbo源码阅读:rpc请求处理流程(1) 架构设计:系统间通信(17)——服务治理与Dubbo 中篇(分析) 13. Dubbo原理解析-注册中心之Zo ...