使用sklearn进行K_Means聚类算法
再附上一篇翻译文档
http://blog.csdn.net/xiaoyi_zhang/article/details/52269242
再给一个百度上找的例子(侵权删):
# -*- coding: utf-8 -*-
from sklearn.cluster import KMeans
from sklearn.externals import joblib
import numpy
final = open('c:/test/final.dat' , 'r')
data = [line.strip().split('\t') for line in final]
feature = [[float(x) for x in row[3:]] for row in data]
#调用kmeans类
clf = KMeans(n_clusters=9)
s = clf.fit(feature)
print s
#9个中心
print clf.cluster_centers_
#每个样本所属的簇
print clf.labels_
#用来评估簇的个数是否合适,距离越小说明簇分的越好,选取临界点的簇个数
print clf.inertia_
#进行预测
print clf.predict(feature)
#保存模型
joblib.dump(clf , 'c:/km.pkl')
#载入保存的模型
clf = joblib.load('c:/km.pkl')
'''
#用来评估簇的个数是否合适,距离越小说明簇分的越好,选取临界点的簇个数
for i in range(5,30,1):
clf = KMeans(n_clusters=i)
s = clf.fit(feature)
print i , clf.inertia_
'''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
初学者讲解如下:
参考http://www.cnblogs.com/meelo/p/4272677.html
sklearn对于所有的机器学习算法有一个一致的接口,一般需要以下几个步骤来进行学习:
1、初始化分类器,根据不同的算法,需要给出不同的参数,一般所有的参数都有一个默认值。 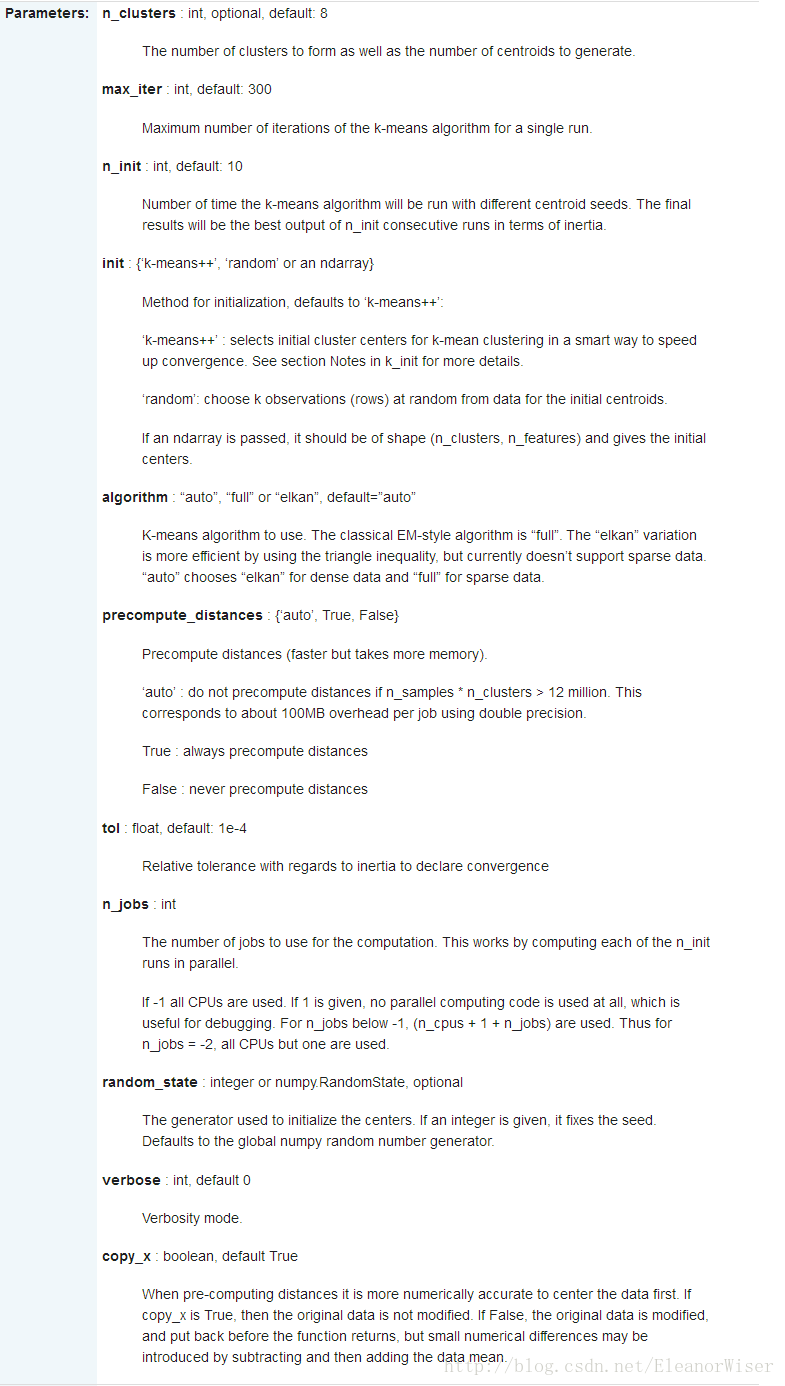
(1)对于K均值聚类,我们需要给定类别的个数n_cluster,默认值为8;
(2)max_iter为迭代的次数,这里设置最大迭代次数为300;
(3)n_init设为10意味着进行10次随机初始化,选择效果最好的一种来作为模型;
(4) init=’k-means++’ 会由程序自动寻找合适的n_clusters;
(5)tol:float形,默认值= 1e-4,与inertia结合来确定收敛条件;
(6)n_jobs:指定计算所用的进程数;
(7)verbose 参数设定打印求解过程的程度,值越大,细节打印越多;
(8)copy_x:布尔型,默认值=True。当我们precomputing distances时,将数据中心化会得到更准确的结果。如果把此参数值设为True,则原始数据不会被改变。如果是False,则会直接在原始数据
上做修改并在函数返回值时将其还原。但是在计算过程中由于有对数据均值的加减运算,所以数据返回后,原始数据和计算前可能会有细小差别。
属性: 
(1)cluster_centers_:向量,[n_clusters, n_features]
Coordinates of cluster centers (每个簇中心的坐标??);
(2)Labels_:每个点的分类;
(3)inertia_:float,每个点到其簇的质心的距离之和。
比如我的某次代码得到结果: 
2、对于非监督机器学习,输入的数据是样本的特征,clf.fit(X)就可以把数据输入到分类器里。
3、用分类器对未知数据进行分类,需要使用的是分类器的predict方法。
使用sklearn进行K_Means聚类算法的更多相关文章
- Python实现 K_Means聚类算法
使用 Python实现 K_Means聚类算法: 问题定义 聚类问题是数据挖掘的基本问题,它的本质是将n个数据对象划分为 k个聚类,以便使得所获得的聚类满足以下条件: 同一聚类中的数据对象相似度较高 ...
- python机器学习(1:K_means聚类算法)
一.算法介绍 K-means算法是最简单的也是最著名的划分聚类算法,由于简洁和效率使得他成为所有聚类算法中最广泛使用的.算法的目的是使各个样本与所在均值的误差平方和达到最小(这也是评价K-means算 ...
- python聚类算法解决方案(rest接口/mpp数据库/json数据/下载图片及数据)
1. 场景描述 一直做java,因项目原因,需要封装一些经典的算法到平台上去,就一边学习python,一边网上寻找经典算法代码,今天介绍下经典的K-means聚类算法,算法原理就不介绍了,只从代码层面 ...
- 机器学习:Python实现聚类算法(一)之AP算法
1.算法简介 AP(Affinity Propagation)通常被翻译为近邻传播算法或者亲和力传播算法,是在2007年的Science杂志上提出的一种新的聚类算法.AP算法的基本思想是将全部数据点都 ...
- Python实现聚类算法AP
1.算法简介 AP(Affinity Propagation)通常被翻译为近邻传播算法或者亲和力传播算法,是在2007年的Science杂志上提出的一种新的聚类算法.AP算法的基本思想是将全部数据点都 ...
- 机器学习:Python实现聚类算法(二)之AP算法
1.算法简介 AP(Affinity Propagation)通常被翻译为近邻传播算法或者亲和力传播算法,是在2007年的Science杂志上提出的一种新的聚类算法.AP算法的基本思想是将全部数据点都 ...
- 机器学习Sklearn系列:(五)聚类算法
K-means 原理 首先随机选择k个初始点作为质心 1. 对每一个样本点,计算得到距离其最近的质心,将其类别标记为该质心对应的类别 2. 使用归类好的样本点,重新计算K个类别的质心 3. 重复上述过 ...
- 转载: scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- 机器学习sklearn19.0聚类算法——Kmeans算法
一.关于聚类及相似度.距离的知识点 二.k-means算法思想与流程 三.sklearn中对于kmeans算法的参数 四.代码示例以及应用的知识点简介 (1)make_blobs:聚类数据生成器 sk ...
随机推荐
- ADB命令行控制界面开关
以下命令需要root权限: svc命令 这个脚本在/system/bin目录下,这个命令可以用来控制电源管理,wifi开关,数据开关(就是上网流量) svc power stayon [t ...
- Vue CLI3 开启gzip压缩
gizp压缩是一种http请求优化方式,通过减少文件体积来提高加载速度.html.js.css文件甚至json数据都可以用它压缩,可以减小60%以上的体积. webpack在打包时可以借助 compr ...
- JavaScript大杂烩12 - 理解Ajax
AJAX缘由 再次谈起这个话题,我深深的记得就在前几年,AJAX被炒的如火如荼,就好像不懂AJAX,就不会Web开发一样.要理解AJAX为什么会出现,就要先了解Web开发面临的问题. 我们先来回忆一下 ...
- 简述 Spring Cloud 是什么2
一.概念定义 Spring Cloud是一个微服务框架,相比Dubbo等RPC框架, Spring Cloud提供的全套的分布式系统解决方案. Spring Cloud对微服务基础框架Ne ...
- 带你熟悉SQLServer2016中的System-Versioned Temporal Table 版本由系统控制的临时表
什么是 System-Versioned Temporal Table? System-Versioned Temporal Table,暂且容我管它叫版本由系统控制的临时表,它是 SQL Serve ...
- EntityFramework Code-First 简易教程(九)-------一对多
一对多(One-to-Many)关系: 下面,我们来介绍Code-First的一对多关系,比如,在一个Standard(年级)类中包含多个Student类. 如果想了解更多关于one-to-one,o ...
- 软件发布时的 GA、RC、Beta
今天在使用 ovirt 的时候,遇到了其 Pre-release 版本并看到如下版本号:ovirt-node-ng-image-update-4.2.7-0.1.rc1.el7.noarch.rpm ...
- [HDFS_4] HDFS 的 Java 应用开发
0. 说明 在 IDEA下 进行 HDFS 的 Java 应用开发 通过编写代码实现对 HDFS 的增删改查操作 1. 流程 1.1 在项目下新建 Moudle 略 1.2 为 Moudle 添加 M ...
- 说说Android6.0动态申请权限的那些坑
白天在做SDK23版本的适配,遇到了不少坑,现在抽空记下来,以此为戒. 首先要知道哪些坑,就得先了解一些定义和基本使用方式. 那么先介绍一下动态申请的权限分组情况. 下面的权限组是由谷歌官方定义的,目 ...
- windows下设置JupyterNotebook默认目录
目录 windows下设置JupyterNotebook默认目录 生成配置文件 设置默认工作目录 设置快捷方式中的目标与起始位置 直接修改anaconda中的相关配置文件 windows下设置Jupy ...