入门大数据---HDFS,Zookeeper,ZookeeperFailOverController(简称:ZKFC),JournalNode是什么?
HDFS介绍:
简述:
Hadoop Distributed File System(HDFS)是一种分布式文件系统,设计用于在商用硬件上运行。它与现有的分布式文件系统有许多相似之处。但是,与其他分布式文件系统的差异很大。HDFS具有高度容错能力,旨在部署在低成本硬件上。HDFS提供对应用程序数据的高吞吐量访问,适用于具有大型数据集的应用程序。HDFS放宽了一些POSIX要求,以实现对文件系统数据的流式访问。HDFS最初是作为Apache Nutch网络搜索引擎项目的基础设施而构建的。HDFS是Apache Hadoop Core项目的一部分。
主要成分:
HDFS主要由NameNode和DataNode组成。NameNode负责存储数据的元数据信息和数据的偏移量。DataNode负责存储数据。
数据进入先通过NameNode
NameNode在Hadoop1.x存在一个,在Hadoop2.x可以有两个了。推荐使用2.x,因为2.x相比1.x更能快速切换新的NameNode。
NameNode里面由EditLog和FsImage组成,EdtiLog记录的是操作日志,FsImage记录的所有文件的元数据(包括:文件大小,文件名称,创建时间等等)。另外FsImage还记录了文件的偏移量,不过这个偏移量是由DataNode做心跳机制反馈给NameNode的。当NameNode启动或者触发配置的检查点时,它会读取EditLog和FsImage,并使用EditLog应用到FsImage并加载到缓存,然后刷新EditLog。
我画了个交互图如下:

下面这则漫画摘自https://blog.csdn.net/hudiefenmu,他很形象的讲解了文件的写入原理,读取原理以及处理故障原理。
HDFS写数据原理:
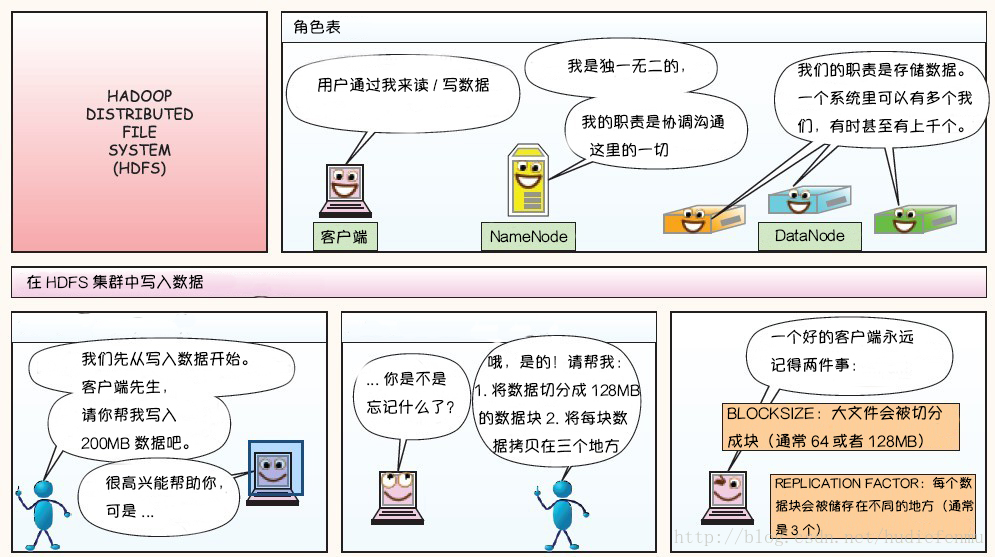
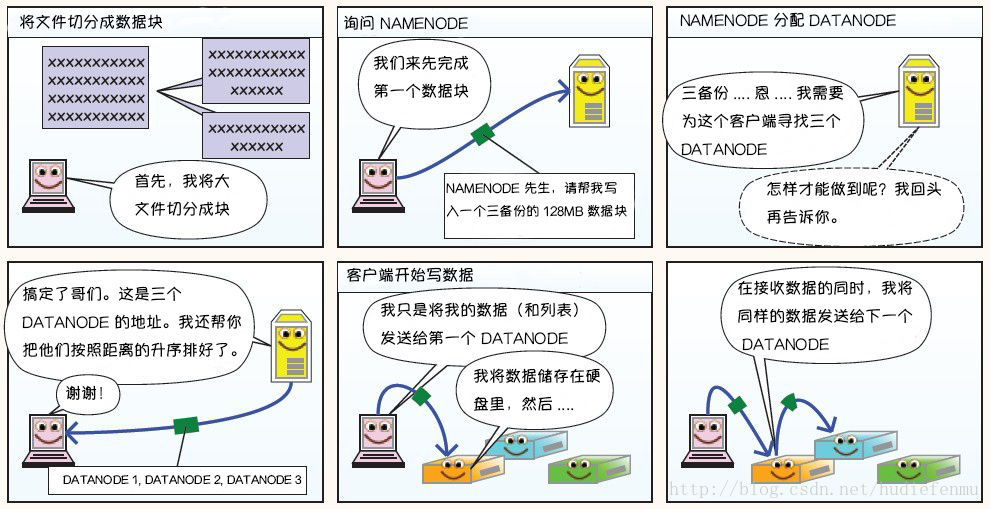
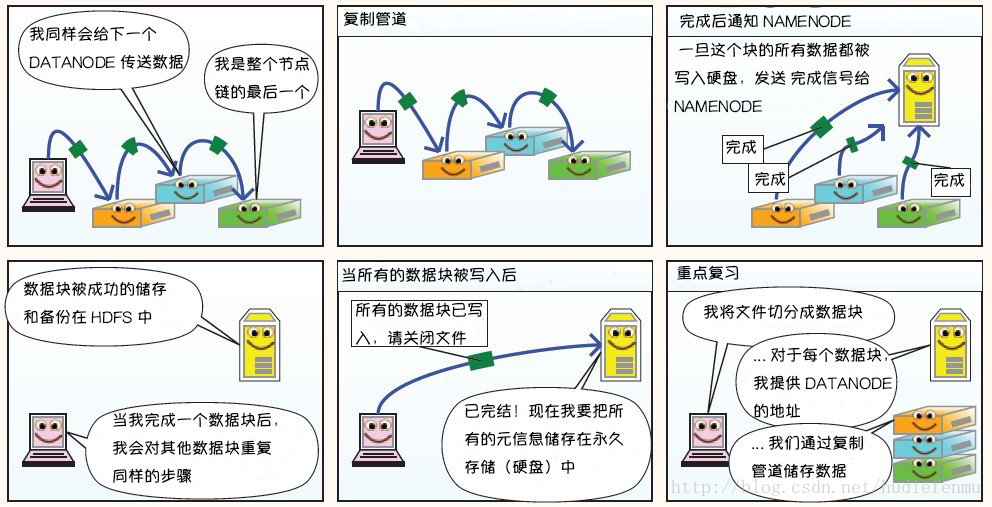
HDFS读数据原理:
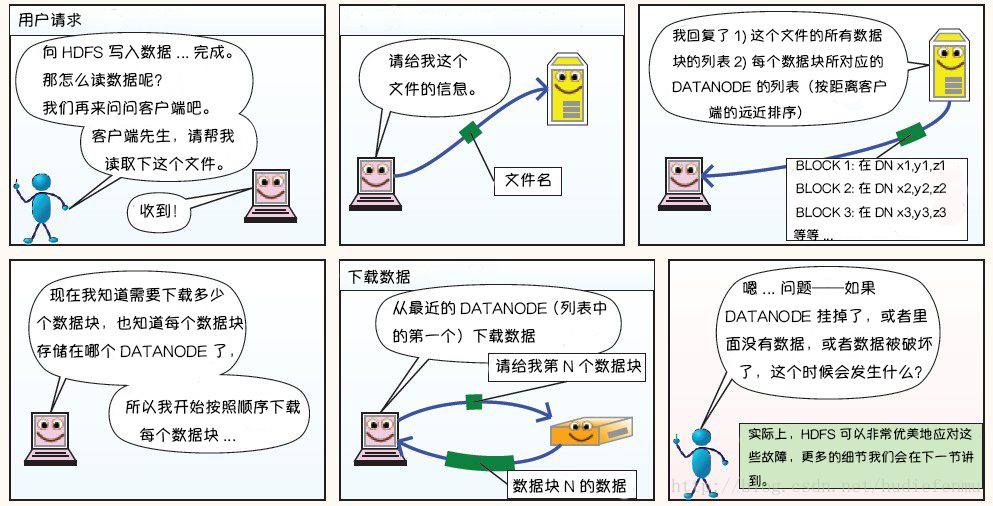
HDFS故障类型和其检测方法:
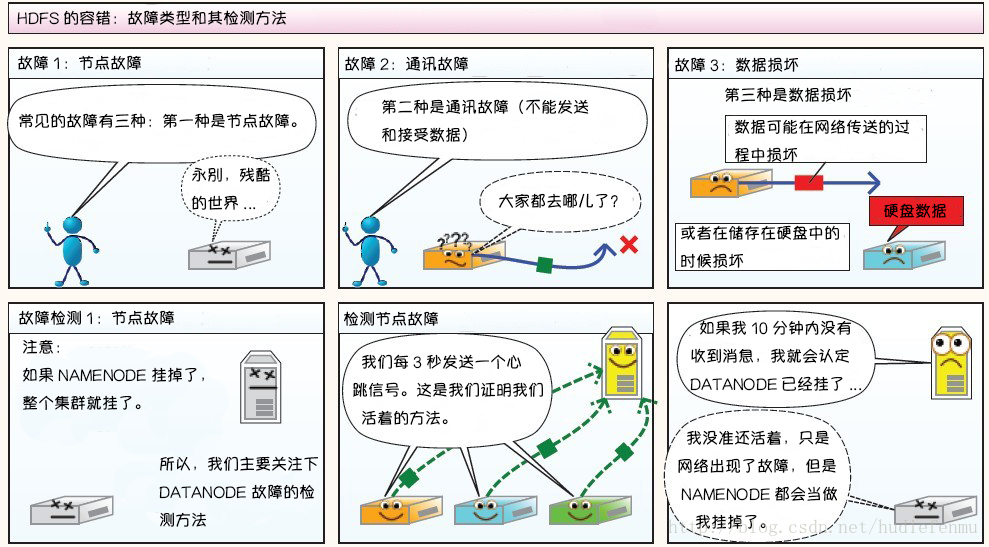
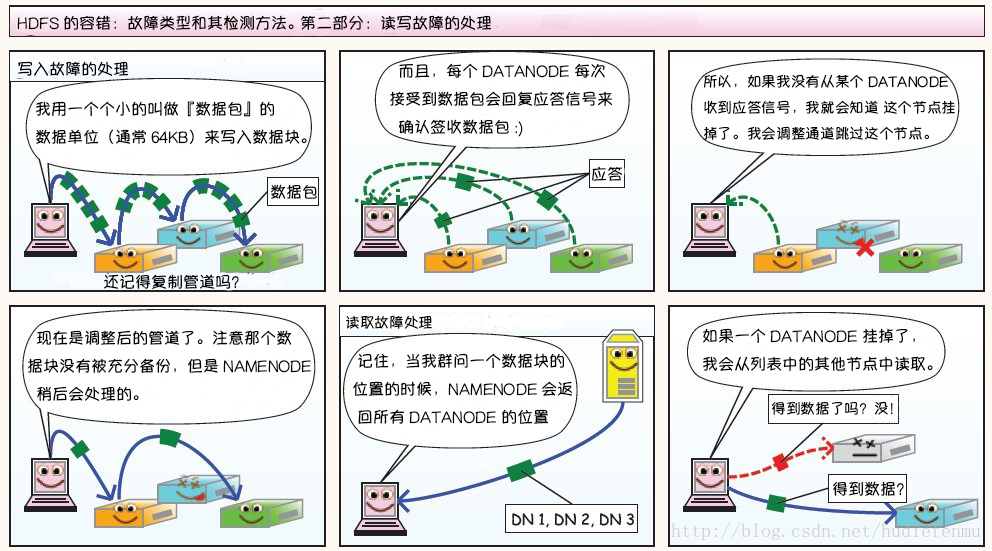
-读写故障的处理
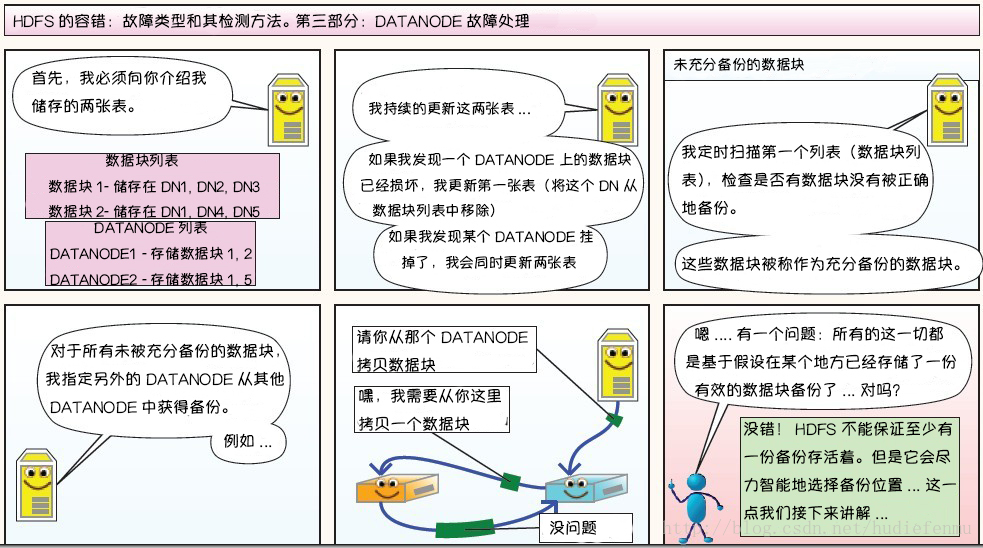
-DataNode故障处理
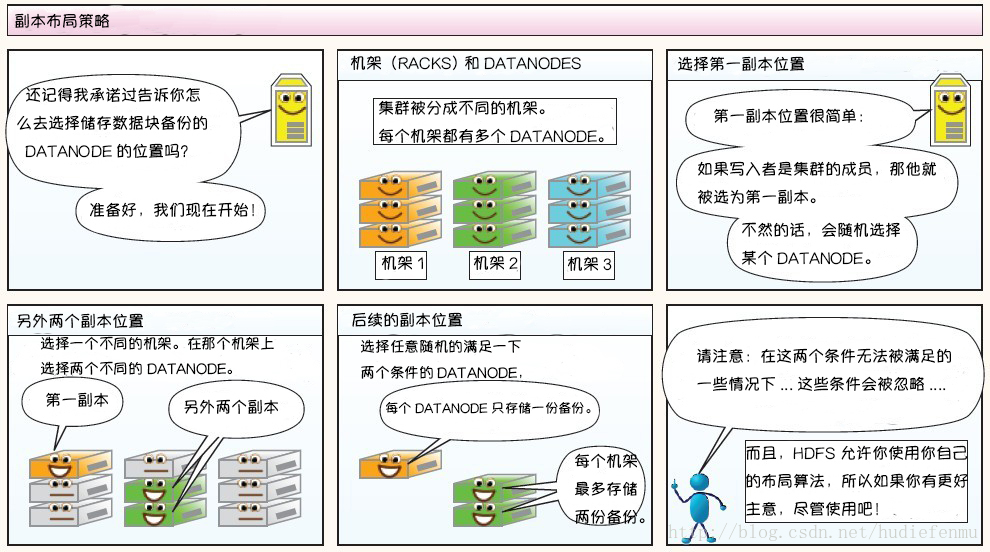
-副本布局策略
Quorum Journal Manager :
简述:
由于部署了两个NameNode,并且仅仅允许一台(ActiveNode)对外提供服务,另一台(StandByNode)在NameNode不可用的时候切换过去,这样就要保证StandBy数据是最新的。 而JournalManager就是接受ActiveNode的变动日志,然后StandBy节点读取同步更新数据。
结合上面的NameNode我画了个图如下:
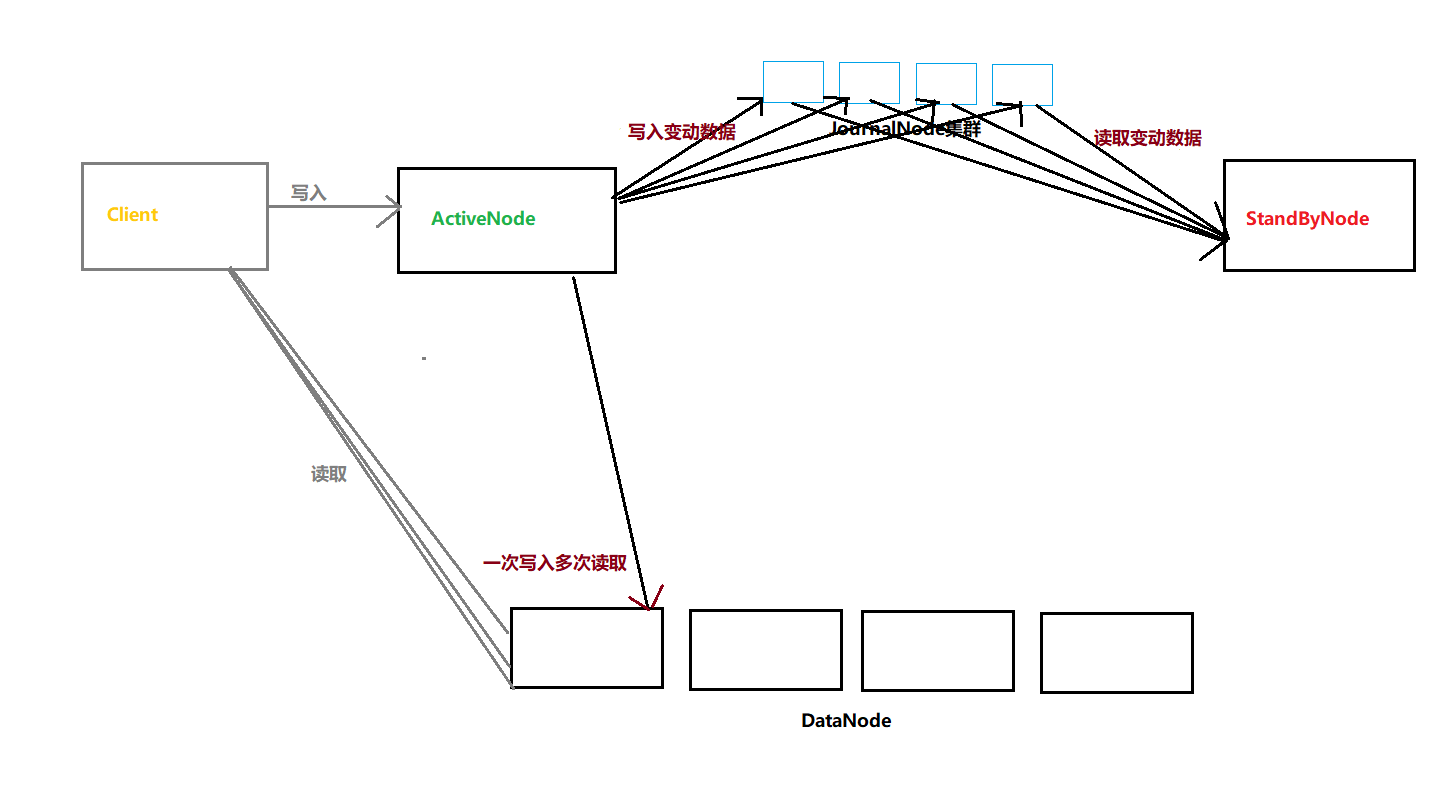
Zookeeper和ZookeeperFailOverController介绍:
简述:
Zookeeper简称ZK,ZookeeperFailOverController简称ZKFC
上面使用JournalManager遇到故障的时候需要手动切换NameNode节点,这样处理会很不及时,所以必须想个办法自动切换,这样就有了Zookeeper,然后配套的出现了ZKFC,ZKFC和NameNode是一一对应的,它是一个守护进程,它负责和ZK通信,并且时刻检查NameNode的健康状况。它通过不断的ping,如果能ping通,则说明节点是健康的。然后ZKFC会和ZK保持一个持久通话,及Session对话,并且ActiveNode在ZK里面记录了一个"锁",这样就会Prevent其它节点成为ActiveNode,当会话丢失时,ZKFC会发通知给ZK,同时删掉"锁",这个时候其它NameNode会去争抢并建立新的“锁”,这个过程叫ZKFC的选举。
结合上面简要图如下:

入门大数据---HDFS,Zookeeper,ZookeeperFailOverController(简称:ZKFC),JournalNode是什么?的更多相关文章
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 入门大数据---基于Zookeeper搭建Spark高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 2020/4/26 大数据的zookeeper分布式安装
大数据的zookeeper分布式安装 **** 前面的文章已经提到Hadoop的伪分布式安装.现在就在原有的基础上安装zookeeper. 首先启动Hadoop平台 [root@master ~]# ...
- 大数据之 ZooKeeper原理及其在Hadoop和HBase中的应用
ZooKeeper是一个开源的分布式协调服务,由雅虎创建,是Google Chubby的开源实现.分布式应用程序可以基于ZooKeeper实现诸如数据发布/订阅.负载均衡.命名服务.分布式协调/通知. ...
- 大数据-hdfs技术
hadoop 理论基础:GFS----HDFS:MapReduce---MapReduce:BigTable----HBase 项目网址:http://hadoop.apache.org/ 下载路径: ...
- 入门大数据---HDFS-HA搭建
一.简述 上一篇了解了Zookeeper和HDFS的一些概念,今天就带大家从头到尾搭建一下,其中遇到的一些坑也顺便记录下. 1.1 搭建的拓扑图如下: 1.2 部署环境:Centos3.1,java1 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 【大数据】Zookeeper学习笔记
第1章 Zookeeper入门 1.1 概述 Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目. 1.2 特点 1.3 数据结构 1.4 应用场景 提供的服务包括:统 ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
随机推荐
- ES6-json与字符串的转换
1.ES5下的json 1.1 基本概念 是对象 简写形式,名字跟值(key和value)一样,留一个就行 方法 :function一块删 即show:function(){...}等价于show() ...
- Rocket - util - Broadcaster
https://mp.weixin.qq.com/s/ohBVNAXZUA538qSxfBGMKA 简单介绍Broadcaster的实现. 1. Broadcaster 广播即是 ...
- 题解 P5329 【[SNOI2019]字符串】
用栈的做法来水一发. 首先我们有一个暴力的做法,枚举每个被删除的字符,然后排序输出,时间复杂度:$ O ( N \times N \times LogN ) $ . 然后我们观察一下数据,发现有一个数 ...
- Spring Boot笔记(一) springboot 集成 swagger-ui
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1.添加依赖 <!--SpringBoot整合Swagger-ui--> <depen ...
- Java实现 蓝桥杯 算法提高 摩尔斯电码
算法提高 9-3摩尔斯电码 时间限制:1.0s 内存限制:256.0MB 提交此题 问题描述 摩尔斯电码破译.类似于乔林教材第213页的例6.5,要求输入摩尔斯码,返回英文.请不要使用"zy ...
- Java实现 蓝桥杯VIP 算法训练 字符串编辑
算法训练 字符串编辑 时间限制:1.0s 内存限制:512.0MB 问题描述 从键盘输入一个字符串(长度<=40个字符),并以字符 '.' 结束.编辑功能有: 1 D:删除一个字符,命令的方式为 ...
- 第四届蓝桥杯C++B组国(决)赛真题
解题代码部分来自网友,如果有不对的地方,欢迎各位大佬评论 题目1.猜灯谜 A 村的元宵节灯会上有一迷题: 请猜谜 * 请猜谜 = 请边赏灯边猜 小明想,一定是每个汉字代表一个数字,不同的汉字代表不同的 ...
- 使用Pycharm安装插件时发生错误
报错内容:pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host='files.pythonhosted.o ...
- C语言深入理解通过指针引用多维数组(指针中使用起始地址 元素地址 元素值的区分)
#include "pch.h" #include <iostream> #include<stdio.h> int main() { // std::co ...
- java实现Prim算法
1 问题描述 何为Prim算法? 普里姆算法(Prim算法),图论中的一种算法,可在加权连通图里搜索最小生成树.意即由此算法搜索到的边子集所构成的树中,不但包括了连通图里的所有顶点(英语:Vertex ...