Hadoop安装教程_分布式
Hadoop的分布式安装
hadoop安装伪分布式以后就可以进行启动和停止操作了。
首先需要格式化HDFS分布式文件系统。hadoop namenode -format
然后就可以启动了。start-all.sh
此时使用jps命令可以查看启动的5个守护进程
也可以通过web查看是否启动成功。
localhost:50070查看 NameNode 节点,localhost:50030查看 JobTracker 节点
停止命令。stop-all.sh
一、配置IP
这是使用了两台已经配置好 hadoop 单机环境的 Ubuntu
Ubuntu_master:192.168.1.3
ubuntu_slave:192.168.1.6
二、配置主机名及 hosts 文件
为了能使用 登录以及 ping 更简单
我们在这里配置地址及主机名到 hosts 文件
在 /etc/hosts 文件中添加以下内容:
192.168.1.3 master
192.168.1.6 slave
同时使用 nmtui 命令修改自己的主机名,重启生效
三、配置 hadoop 环境变量
使用 vim ~/.bashrc 编辑用户环境配置文件
在该文件中加入下列内容:
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
然后使用 source ~/.bashrc 使其生效
用 hadoop version 命令检查上述操作是否生效
四、配置 hadoop 配置文件
1、slaves 将数据节点主机名写入其中
2、core-site.xml 配置文件

3、hdfs-site.xml 配置文件

4、mapred-site.xml 配置文件

5、yarn-site.xml 配置文件

五、将配置文件拷贝至各 slave 节点
在 /usr/local/hadoop 目录下
tar -zcvf etc.tar.gz etc 将文件夹打包
scp etc.tar.gz slave:/home 传送
此时报权限错误而无法传送
原因是:当前用户没有在 /home 下的写权限
当我用 root 身份登录时,发现依然不行
一直报访问拒绝错误
原因是:ssh 设置不可使用 root 什么登录
解决办法:/etc/ssh/sshd_config 配置文件中
PermitRootLogin 的值改为 yes
这里我们使用 scp etc.tar.gz slave:/home/haojun 命令传送
然后 ssh slave 登录到 slave
然后 rm -rf /usr/local/hadoop/etc 删除原配置文件
然后 tar -zxvf etc.tar.gz -C /usr/local/hadoop 解压新配置文件
此时应确保解压后的权限与当前用户一致,否则应
sudo chown -R haojun:haojun /usr/local/hadoop/etc 更改权限
六、执行 NameNode 初始化并关闭防火墙
在 master 节点上 执行
hdfs namenode -format 即可
出现类似下面信息即表示成功:

如果没有,则查看上面的执行日志,以更改错误
多数错误是配置文件书写错误!也就是笔误!!
命令 作用
sudo ufw status 查看防火墙状态
sudo ufw enable 激活防火墙
sudo ufw disable 关闭防火墙
以上三条命令适用于发行版为 Ubuntu 的 Linux
七、启动 hadoop
start-dfs.sh 启动第一、二名称节点
start-yarn.sh 启动资源管理器
mr-jobhistory-daemon.sh start historyserver 启动工作历史服务
jps 查看节点启动情况
hdfs dfsadmin -report 查看数据节点启动情况
正常情况下,master 应该有如下图,slave 亦是。
 此时亦可通过web访问:http://master:50070/ 查看各节点启动情况
此时亦可通过web访问:http://master:50070/ 查看各节点启动情况
补充:如无法正常启动,还可通过删除 tmp、logs 等文件夹并重新初始化 NameNode 节点的方式排错。

八、执行分布式实例
8.1创建 HDFS 上的用户目录
hdfs dfs -mkir -p /user/hadoop
8.2创建 input 文件夹
hdfs dfs -mkidr input
此处报文件不存在错误
再次开机时以及可以。
可能是之前某些操作没有执行成功,或者命令打错根本没有执行。
hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input
拷贝样例文件
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output ‘dfs[a-z.]+’
执行命令

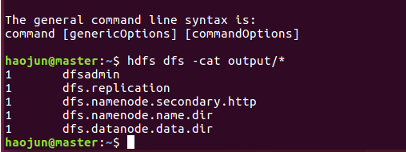
hdfs dfs -cat output/*
即可查看如下图结果
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver
以上是关闭命令
Hadoop安装教程_分布式的更多相关文章
- Hadoop安装教程_伪分布式
文章更新于:2020-04-09 注1:hadoop 的安装及单机配置参见:Hadoop安装教程_单机(含Java.ssh安装配置) 注2:hadoop 的完全分布式配置参见:Hadoop安装教程_分 ...
- Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0
Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0 环境 本教程使用 CentOS 6.4 32位 作为系统环境,请自行安装系统.如果用的是 Ubuntu 系统,请查 ...
- 转载:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文 http://www.powerxing.com/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单,书上有写到, ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
摘自: http://www.cnblogs.com/kinglau/p/3796164.html http://www.powerxing.com/install-hadoop/ 当开始着手实践 H ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04(转)
http://www.powerxing.com/install-hadoop/ http://blog.csdn.net/beginner_lee/article/details/6429146 h ...
- 【转】Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文链接:http://dblab.xmu.edu.cn/blog/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单, ...
- Hadoop安装教程_单机/伪分布式配置
环境 本教程使用 CentOS 6.4 32位 作为系统环境,请自行安装系统(可参考使用VirtualBox安装CentOS).如果用的是 Ubuntu 系统,请查看相应的 Ubuntu安装Hadoo ...
- 新手推荐:Hadoop安装教程_单机/伪分布式配置_Hadoop-2.7.1/Ubuntu14.04
下述教程本人在最新版的-jre openjdk-7-jdk OpenJDK 默认的安装位置为: /usr/lib/jvm/java-7-openjdk-amd64 (32位系统则是 /usr/lib/ ...
- Hadoop安装教程_集群/分布式配置
配置集群/分布式环境 集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slav ...
随机推荐
- RStudio终端操作
转于:https://support.rstudio.com/hc/en-us/articles/115010737148-Using-the-RStudio-Terminal#send 原文是英文版 ...
- Maven pom.xml 添加本地jar包依赖以及打包方法
Maven项目打包时,如果遇到需要添加本地jar包依赖的时候,可以选择两种方法: 1. 安装到本地仓库 第一种方法比较常规,适用于需要添加的jar包也是由maven项目导出,含有pom文件的时候.只需 ...
- QT使用信号量QSemaphore处理大量数据
实现如下:
- Linux 中useradd命令的使用
Linux 系统中通常都是root用户具有超级权限,超级用户root一般是不需要创建的,然而很多时候root用户不是任何人都可以使用的,毕竟最高权限的用户,任意使用的话,会对系统造成很多不必要的破坏. ...
- win10环境下如何修改Python pip的更新源?
1.在window的文件夹窗口输入 : %APPDATA%2.在弹出的路径中新建pip文件夹,然后到pip文件夹里面去新建个pip.ini文件,然后再里面输入内容 [global] timeout = ...
- 《前端之路》- TypeScript (三) ES5 中实现继承、类以及原理
目录 一.先讲讲 ES5 中构造函数(类)静态方法和多态 1-1 JS 中原型以及原型链 例子一 1-2 JS 中原型以及原型链中,我们常见的 constructor.prototype.**prot ...
- 3000字编程入门--附带Java学习路线及视频
Title: 编程入门 GitHub: BenCoper Reference: 尚硅谷-2019 Study: 文字版+视频+实战(第一个自学的网站) Explain: 文末附带Java学习视频以及项 ...
- [Dynamic Programming]动态规划之背包问题
动态规划之背包问题 例题 现有4样物品n = ['a', 'b', 'c', 'd'],重量分别为w = [2, 4, 5, 3],价值分别为v = [5, 4, 6, 2].背包最大承重c = 9. ...
- python之路---装饰器函数
阅读目录 楔子 装饰器的形成过程 开放封闭原则 谈装饰器主要功能和装饰器固定结构 带参数的装饰器 多个装饰器装饰一个函数 返回顶部 楔子 作为一个会写函数的python开发,我们从今天开始要去公司上班 ...
- Mybatis三剑客介绍
1.MyBatis generator 利用mybatis-generator自动生成代码 下载地址: https://download.csdn.net/download/qq_36625806/ ...