面试之Hashtable和ConcurrentHashMap
那么要如何保证HashMap的线程安全呢? 方法有很多,比如使用Hashtable或者Collections.synchronizedMap,但是这两位选手都有一个共同的问题:性能。因为不管是读还是写操作,他们都会给整个集合上锁,导致同一时间的其他操作被阻塞。
虽然Hashtable和Collections.synchronizedMap解决了HashMap的线程不安全的问题,但是带来了运行效率不佳的问题。
基于以上所述,兼顾了线程安全和运行效率的ConcurrentHashMap就出现了。
在了解了HashMap之后,接下来就开始了解一下ConcurrentHashMap。
ConcurrentHashMap与HashMap相比,最关键的是要理解一个概念:segment。
Segment其实就是一个Hashmap 。Segment也包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点。
Segment对象在ConcurrentHashMap集合中有2的N次方个,共同保存在一个名为segments的数组当中。(类比HashMap来理解Segment就好)
因此ConcurrentHashMap的结构为:
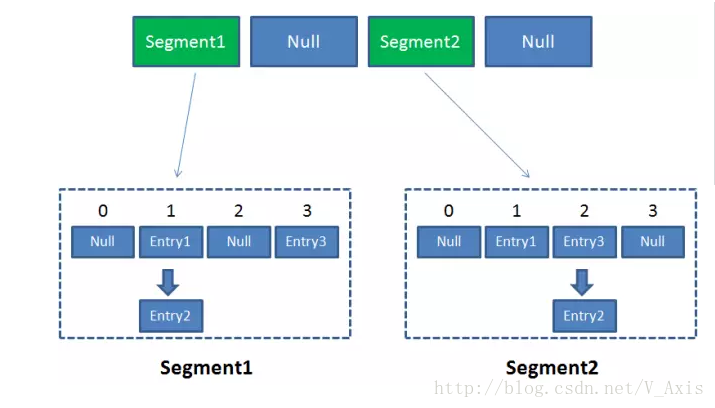
换言之,ConcurrentHashMap是一个双层哈希表。在一个总的哈希表下面,有若干个子哈希表。(这样的双层结构,类似于数据库水平拆分来理解)
ConcurrentHashMap如此的设计,优势主要在于:
每个segment的读写是高度自治的,segment之间互不影响。这称之为“锁分段技术”;
看一下并发情况下的ConcurrentHashMap:
情景一:不同segment的并发写入
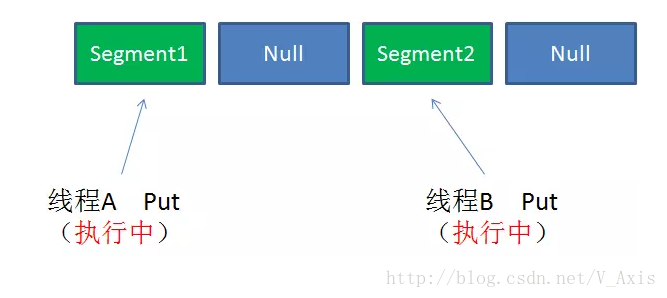
不同的Segment是可以并发执行put操作的
情景二:同一segment的并发写入
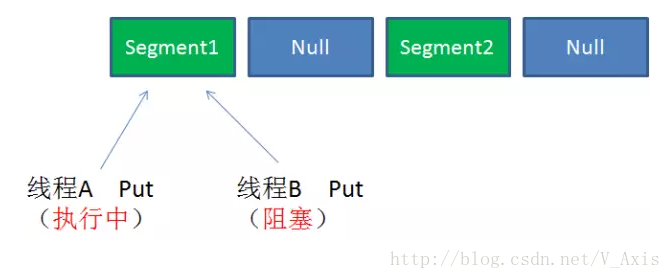
因为segment的写入是上锁的,因此对 同一segment的并发写入会被阻塞;
情景三:同一segment的一写一读
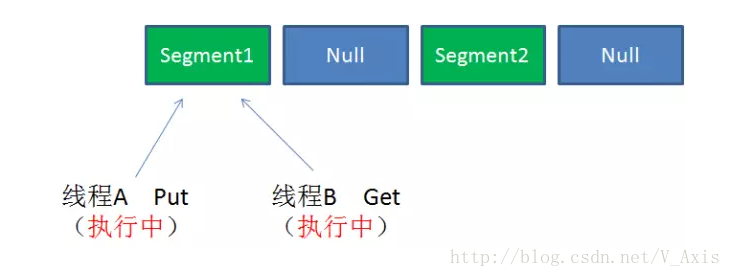
同一segment的写和读是可以并发执行的;
看到此处,就已经知道了ConcurrentHashMap的并发情况,有兴趣的话可以继续看下ConcurrentHashMap的具体读写过程。
Get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
Put方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.再次通过hash值,定位到Segment当中数组的具体位置。
5.插入或覆盖HashEntry对象。
6.释放锁。
看到此处,对于ConcurrentHashMap的Get和Put的过程(读写过程)就有了一个完整的了解了。
基于上述,会有一个问题:
每一个segment各自持有锁,那么在调用size()方法的时候(size()在实际开发大量使用),怎么保持一致性呢?
详细描述一下上面问题的情景:
Size方法的目的是统计ConcurrentHashMap的总元素数量, 肯定要把每个segment内部的元素数量都加起来。
那么假设一种情况,在统计segment元素数量的过程中,在统计结束前,已统计过的segment插入了新的元素,size()返回的数量就会出现不一致的问题。
为解决这个问题,ConcurrentHashMap的Size()方法是通过一个嵌套循环解决的,大体过程如下:
1.遍历所有的Segment。
2.把Segment的元素数量累加起来。
3.把Segment的修改次数累加起来。
4.判断所有Segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是。说明没有修改,统计结束。
5.如果尝试次数超过阈值,则对每一个Segment加锁,再重新统计。
6.再次判断所有Segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。
7.释放锁,统计结束。
这种解决办法是不是似曾相识?没错,这种思想和乐观锁悲观锁的思想如出一辙(不熟悉乐观锁的道友可以看我转的一篇非常生动的介绍,传送门)
为了不锁所有segment,首先乐观地假设size过程中不会有修改。当尝试一定次数,才无奈转悲观,锁住所有segment以保证一致性。
补充:
1、以上都是基于Java1.7的ConcurrentHashMap原理和代码;
2、ConcurrentHashMap在对Key求Hash值的时候进行了两次Hash,目的是为了实现Segment均匀分布。
小结
说了那么多,针对Map子类的安全性可以总结如下几点:
- HashMap采用链地址法解决哈希冲突,多线程访问哈希表的位置并修改映射关系的时候,后执行的线程会覆盖先执行线程的修改,所以不是线程安全的
- Hashtable采用synchronized关键字解决了并发访问的安全性问题但是效率较低
- ConcurrentHashMap使用了线程锁分段技术,每次访问只允许一个线程修改哈希表的映射关系,所以是线程安全的
面试之Hashtable和ConcurrentHashMap的更多相关文章
- java面试考点-HashTable/HashMap/ConcurrentHashMap
HashTable 内部数据结构是数组+链表,键值对不允许为null,线程安全,但是锁是整表锁,性能较差/效率低 HashMap 结构同HashTable,键值对允许为null,线程不安全, 默认初始 ...
- HashMap、Hashtable、ConcurrentHashMap面试总结
原文链接:https://www.cnblogs.com/hexinwei1/p/10000779.html 小总结 HashMap.Hashtable.ConcurrentHashMap HashM ...
- HashMap,HashTable,ConcurrentHashMap异同比较
0. 前言 HashMap和HashTable的区别一种比较简单的回答是: (1)HashMap是非线程安全的,HashTable是线程安全的. (2)HashMap的键和值都允许有null存在,而H ...
- HashMap、HashTable、ConcurrentHashMap、HashSet区别 线程安全类
HashMap专题:HashMap的实现原理--链表散列 HashTable专题:Hashtable数据存储结构-遍历规则,Hash类型的复杂度为啥都是O(1)-源码分析 Hash,Tree数据结构时 ...
- HashMap,Hashtable,ConcurrentHashMap 和 synchronized Map 的原理和区别
HashMap 是否是线程安全的,如何在线程安全的前提下使用 HashMap,其实也就是HashMap,Hashtable,ConcurrentHashMap 和 synchronized Map 的 ...
- Java集合——HashMap、HashTable以及ConCurrentHashMap异同比较
0. 前言 HashMap和HashTable的区别一种比较简单的回答是: (1)HashMap是非线程安全的,HashTable是线程安全的. (2)HashMap的键和值都允许有null存在,而H ...
- Java Main Differences between HashMap HashTable and ConcurrentHashMap
转自这篇帖子:http://www.importnew.com/7010.html HashMap和Hashtable的比较是Java面试中的常见问题,用来考验程序员是否能够正确使用集合类以及是否可以 ...
- Hashtable与ConcurrentHashMap区别
Hashtable与ConcurrentHashMap区别 ConcurrentHashMap融合了hashtable和hashmap二者的优势. hashtable是做了同步的,是线性安全的,(2) ...
- Hashtable、ConcurrentHashMap源码分析
Hashtable.ConcurrentHashMap源码分析 为什么把这两个数据结构对比分析呢,相信大家都明白.首先二者都是线程安全的,但是二者保证线程安全的方式却是不同的.废话不多说了,从源码的角 ...
随机推荐
- Java实现 蓝桥杯VIP 算法提高 企业奖金发放
算法提高 企业奖金发放 时间限制:1.0s 内存限制:512.0MB 企业发放的奖金根据利润提成.利润低于或等于10万元时,奖金可提10%:利润高于10万元,低于20万元时,低于10万元的部分按10% ...
- Java实现埃拉托色尼筛选法
1 问题描述 Compute the Greatest Common Divisor of Two Integers using Sieve of Eratosthenes. 翻译:使用埃拉托色尼筛选 ...
- java实现南北朝时
南北朝时,我国数学家祖冲之首先把圆周率值计算到小数点后六位,比欧洲早了 1100 年! 他采用的是称为"割圆法"的算法,实际上已经蕴含着现代微积分的思想. 如图[1.jpg]所示, ...
- 算法讲堂二:组合数学 & 概率期望DP
组合数学 1. 排列组合 1. 加法原理 完成一列事的方法有 n 类,其中第 i 类方法包括\(a_i\)种不同的方法,且这些方法互不重合,则完成这件事共有 \(a_1 + a_2 + \cdots ...
- 若linux 的分区硬盘满,如何处理?
一.确定是不是真的是磁盘空间不足 输入命令:df –lh 查看磁盘信息 二.如何定位最大文件目录 输入命令:cd / 进入根目录. 输入命令:du -h max-depth=1 寻找当前目录,哪个文件 ...
- 大数据之Hudi + Kylin的准实时数仓实现
问题导读:1.数据库.数据仓库如何理解?2.数据湖有什么用途?解决什么问题?3.数据仓库的加载链路如何实现?4.Hudi新一代数据湖项目有什么优势? 在近期的 Apache Kylin × Apach ...
- TypeError: this.xxx.substring is not a function的解决办法
这是因为已经改变了xxx的值的类型,不再是字符串的话将不会拥有substring函数, 我当时这样写的时候,直接将number类型赋予了this.enter,所以导致了错误. 改为这样之后可以使用su ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(七)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 《Java并发编程的艺术》第4章 Java并发编程基础 ——学习笔记
参考https://www.cnblogs.com/lilinzhiyu/p/8086235.html 4.1 线程简介 进程:操作系统在运行一个程序时,会为其创建一个进程. 线程:是进程的一个执行单 ...
- Vue中hash模式和history模式的区别
vue-router 中hash模式和history模式. 在vue的路由配置中有mode选项,最直观的区别就是在hash模式下的地址栏里的URL夹杂着‘#’号 ,而history模式下没有.vue默 ...