Spark 集群 任务提交模式
Spark 集群的模式及提交任务的方式
- 本文大致的内容图
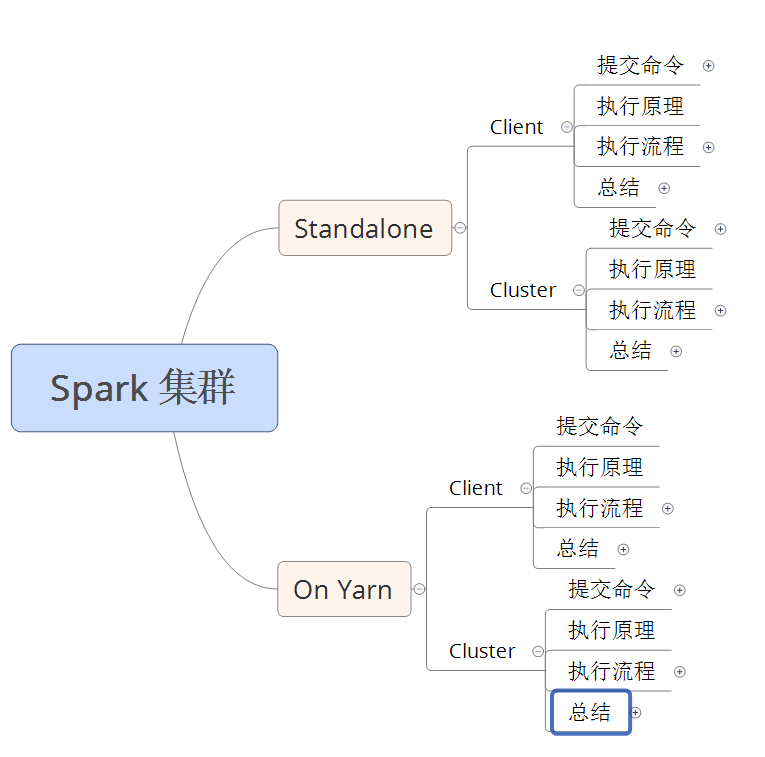
Spark 集群的两种模式:
Standalone 模式
Standalone-client 任务提交方式
提交命令
./spark-submit
--master spark://node1:7077 (主节点的位置)
--class 类的包+类名
jar包的位置
1000 # 分区参数, 也可以说是并行度
||
./spark-submit
--master spark://node1:7077
--deploy-mode client
--class 类的包+类名
jar包的位置
100 # 分区参数, 也可以说是并行度
执行原理

执行流程
- client 模式提交任务后, 会在客户端启动Driver进程
- Driver 会向 Master 申请启动 Application启动的资源
- 资源申请成功, Driver 端将 task 发送到 worker端执行
- Worker 端将 task 执行结果 返回 到 Driver 端
总结
- client模式适用于测试调试程序。
- Driver进程是在客户端启动的。这里的客户端指的是应用程序的当前节点
- 在Driver端可以看到task执行的情况。
- 生产环境下不能使用client模式是因为: 假设提交100个 Application 到集群运行, Driver每次都会在client端启动, 那么就会导致客户端100次网卡流量暴增。
Standalone-cluster 任务提交方式
提交命令
./spark-submit
--master spark://node1:7077
--deploy-mode cluster
--class 包+类名
jar包的位置
100 # 分区参数, 也可以说是并行度 #注意:Standalone-cluster提交方式,应用程序使用的所有jar包和文件,必须保证所有的worker节点都要有,因为此种方式,spark不会自动上传包。
# 解决方式:
# 1.将所有的依赖包和文件打到同一个包中,然后放在hdfs上。
# 2.将所有的依赖包和文件各放一份在worker节点上。
执行原理
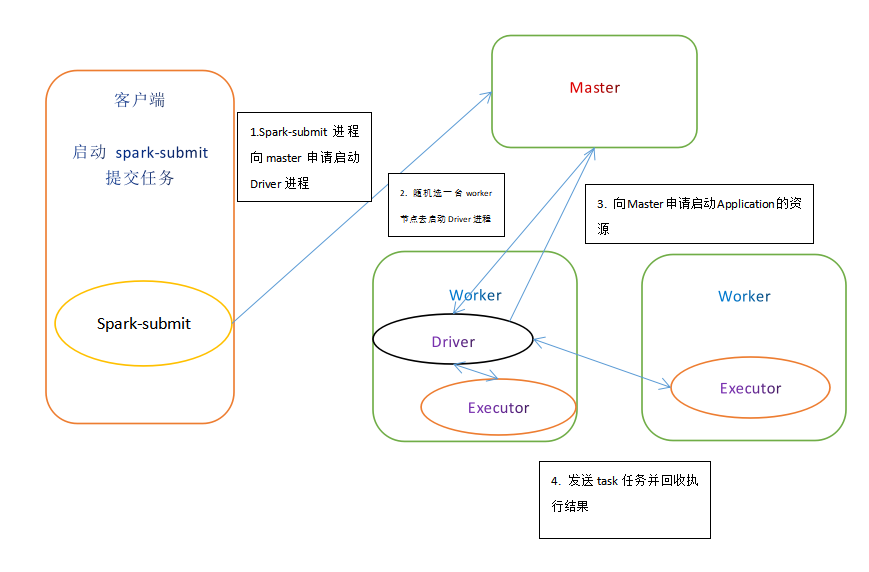
执行流程
- cluster模式提交应用程序后会先向 Master 请求启动 Driver
- Master 接收请求, 随机在集中的一台节点启动Driver进程
- Driver启动后为当前的应用程序申请资源
- Driver端发送task到worker节点上执行
- worker 将执行情况和执行结果返回 Driver
总结
- Standalone-cluster 运行方式适用于生产环境
- 此时在driver端界面看不到执行任务情况
- 由于driver会被随机分配到worker节点上启动, 那么不会有流量激增问题
On Yarn 模式
Yarn-client 任务提交方式
提交命令
./spark-submit
--master yarn
--class 包+类名
jar文件位置
100
||
./spark-submit
--master yarn–client
--class 包+类名
jar文件位置
100
||
./spark-submit
--master yarn
--deploy-mode client
--class 包+类名
jar文件位置
100
执行原理
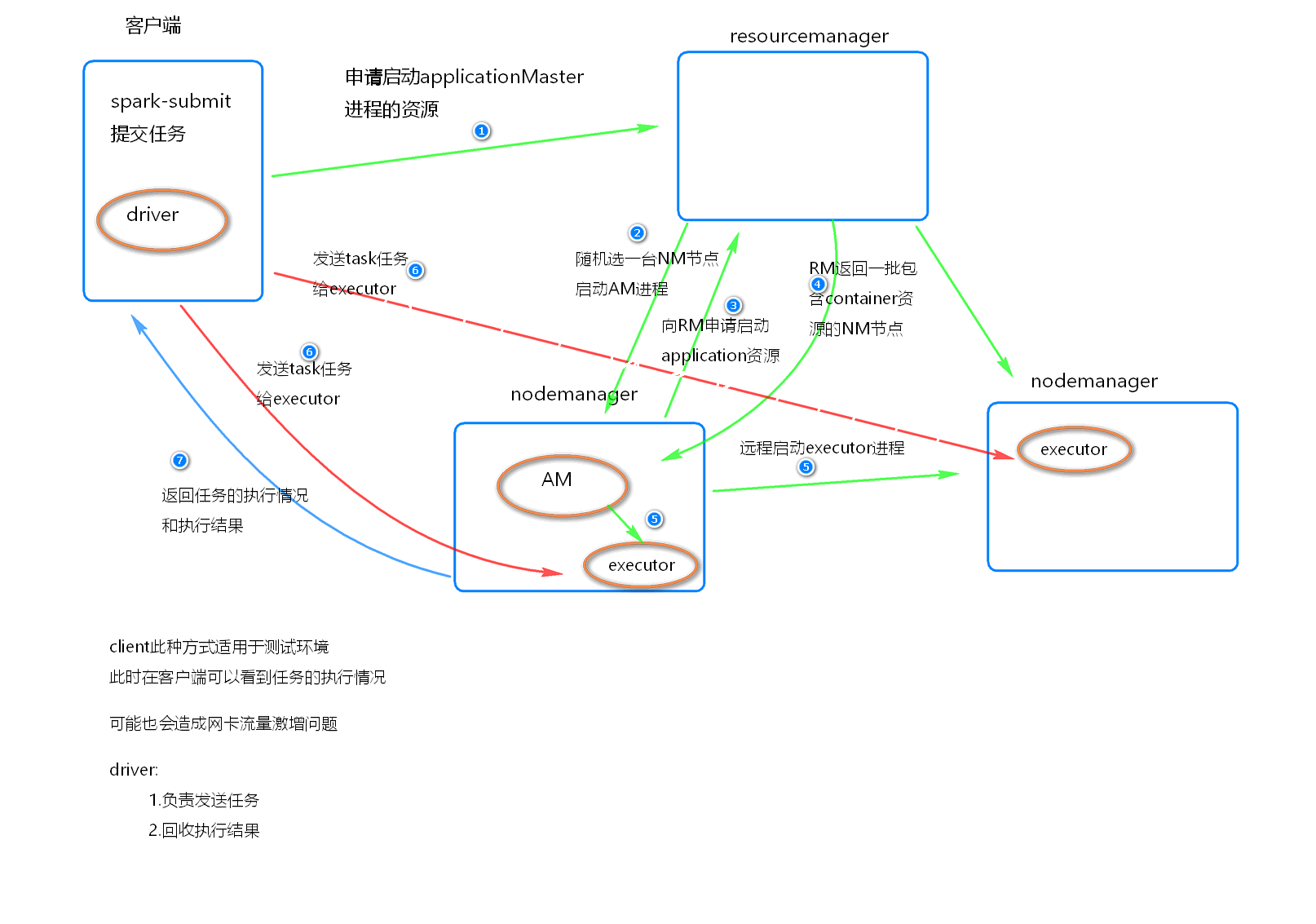
执行流程
- 客户端提交一个 Application, 在客户端启动一盒Driver 进程。
- 应用程序启动后会向RM(ResourceManager) 发送请求, 启动AM(ApplicationMaster)
- RM 收到请求, 随机选择一台 NM(NodeManager)启动AM。这里的NM相当于Standalone中的Worker节点
- AM 启动后, 会向 RS 请求一批container资源, 用于启动Executor
- RM会找到一批NM返回给AM, 用于启动Executor
- AM会向NM发送命令启动Executor
- Executor 启动后, 会反向注册给Driver, Driver 发送 task 到 Executor, 执行情况和结果返回给Driver端
总结
Yarn-client模式同样适用于测试, 因为Driver运行在本地, Driver会与yarn集群中的Executor 进行大量的通信, 会造成客户机网卡流量的大量增加
ApplicationMaster 的作用:
为当前的Application申请资源
给NodeManager发送消息启动Executor
Yarn-cluster 任务提交方式
提交命令
./spark-submit
--master yarn
--deploy-mode cluster
--class 包+类名
jar文件位置
100
||
/spark-submit
--master yarn-cluster
--class 包+类名
jar文件位置
100
执行原理
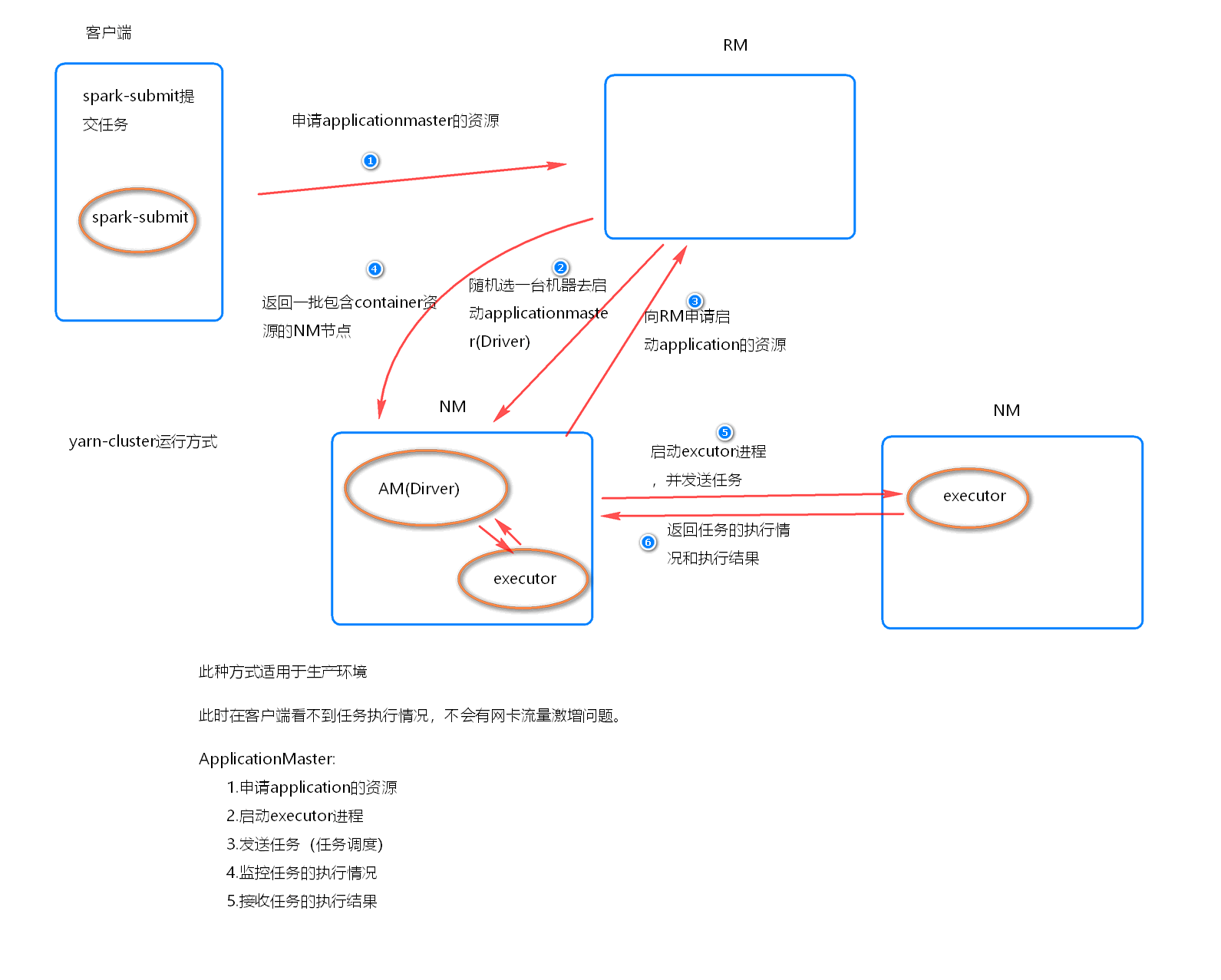
执行流程
- 客户机提交Application应用程序, 发送请求到RM(ResourceManager), 请求启动(ApplicationMaster)
- RM收到请求后随即在一台 NM(NodeManager) 上启动 AM(相当于Driver 端)
- AM启动后, AM 发送请求到 RM, 申请一批容器(container)来启动Executor
- RM 返回一批 NM 节点 给 AM
- AM 连接到 NM, 发送请求到 NM 启动 Executor
- Executor 反向注册到 AM 所在节点的 Driver,Driver再发送task到Executor
总结
- Yarn-Cluster 主要用于生产环境中, 因为 Driver运行在 Yarn 集群中某一台NodeManager中, 每次提交任务的 Driver 所在机器都是随机的, 并不会产生一台机器网卡流量激增的现象。
- 缺点是提交任务不能看到日志, 只能通过yarn查看日志
- ApplicationMaster的作用
- 为当前的 Application 申请资源
- 给NodeManger 发送消息启动 Executor
- 任务调度
Spark 集群 任务提交模式的更多相关文章
- Spark集群任务提交
1. 集群管理器 Spark当前支持三种集群管理方式 Standalone—Spark自带的一种集群管理方式,易于构建集群. Apache Mesos—通用的集群管理,可以在其上运行Hadoop Ma ...
- Spark集群任务提交流程----2.1.0源码解析
Spark的应用程序是通过spark-submit提交到Spark集群上运行的,那么spark-submit到底提交了什么,集群是怎样调度运行的,下面一一详解. 0. spark-submit提交任务 ...
- Spark集群之yarn提交作业优化案例
Spark集群之yarn提交作业优化案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.启动Hadoop集群 1>.自定义批量管理脚本 [yinzhengjie@s101 ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Spark集群模式&Spark程序提交
Spark集群模式&Spark程序提交 1. 集群管理器 Spark当前支持三种集群管理方式 Standalone-Spark自带的一种集群管理方式,易于构建集群. Apache Mesos- ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- Spark集群模式概述
作者:foreyou出处:http://www.foreyou.net/2015/06/22/spark-cluster-mode-overview/声明:本文采用以下协议进行授权: 署名-非商用|C ...
- 向Spark集群提交任务
1.启动spark集群. 启动Hadoop集群 cd /usr/local/hadoop/ sbin/start-all.sh 启动Spark的Master节点和所有slaves节点 cd /usr/ ...
- Spark集群的任务提交执行流程
本文转自:https://www.linuxidc.com/Linux/2018-02/150886.htm 一.Spark on Standalone 1.spark集群启动后,Worker向Mas ...
随机推荐
- redis之Hash类型常用方法总结
redis之Hash类型常用方法总结 格式: 存--HMGET key field [field ...] 取--HMGET key field [field ...] M:表示能取多个值,many ...
- Python学习第三课——运算符
# 运算符 + - * / **(幂) %(取余) //(取整) num=9%2 print("余数为"+(str)(num)) #运算结果为 1 num1=9//2 print( ...
- 第3节 storm高级应用:2、storm与hdfs的整合工程环境准备;3、整合代码开发
======================================== 3. storm与hdfs的整合使用 3.1.功能需求: 实现随机发送订单数据,从计算订单的总金额,然后将订单中的数 ...
- 第1节 kafka消息队列:2、kafka的架构介绍以及基本组件模型介绍
3.kafka的架构模型 1.producer:消息的生产者,主要是用于生产消息的.主要是接入一些外部的数据源,从外部获取数据,比如说我们可以从flume获取数据,还可以通过ftp传入数据等,还可以通 ...
- 二十、oracle通过复合索引优化查询及不走索引的8种情况
1. 理解ROWID ROWID是由Oracle自动加在表中每行最后的一列伪列,既然是伪列,就说明表中并不会物理存储ROWID的值:你可以像使用其它列一样使用它,只是不能对该列的值进行增.删.改操作: ...
- array_multisort 对关联数组进行排序的问题 PHP
我们在php的数组操作中经常用到对数组进行排序的问题,这里说的是对关联数组进行排序需要用到函数 array_multisort . array_multisort(array_column($arr, ...
- 第1节 IMPALA:1、impala的基本介绍
impala的介绍: impala是cloudera公司开源提供的一款高效率的sql查询工具 impala可以兼容hive的绝大多数的语法,可以完全的替代表hive impala与hive的关系:紧耦 ...
- redheat7 sd 0:0:0:0: [sda] Assuming drive cache: write through(未解决)
以下是我上网查找的解决办法 1. sd 0:0:0:0: [sda] Assuming drive cache: write through 解决方法:/etc/default/grub 文件里去掉 ...
- 空中网4k/5k月薪挑选大四实习生的线程题
空中网4k/5k月薪挑选大四实习生的线程题 两年前,我们一个大四的学员去应聘空中网的实习生职位,空中网只给他出了三道线程题,拿回家做两天后再去给经理讲解,如果前两题做好了给4k月薪,第三道题也做出来的 ...
- R 《回归分析与线性统计模型》page93.6
rm(list = ls()) #数据处理 library(openxlsx) library(car) library(lmtest) data = read.xlsx("xiti4.xl ...