向Spark集群提交任务
1.启动spark集群。
启动Hadoop集群
- cd /usr/local/hadoop/
- sbin/start-all.sh
启动Spark的Master节点和所有slaves节点
- cd /usr/local/spark/
- sbin/start-master.sh
- sbin/start-slaves.sh
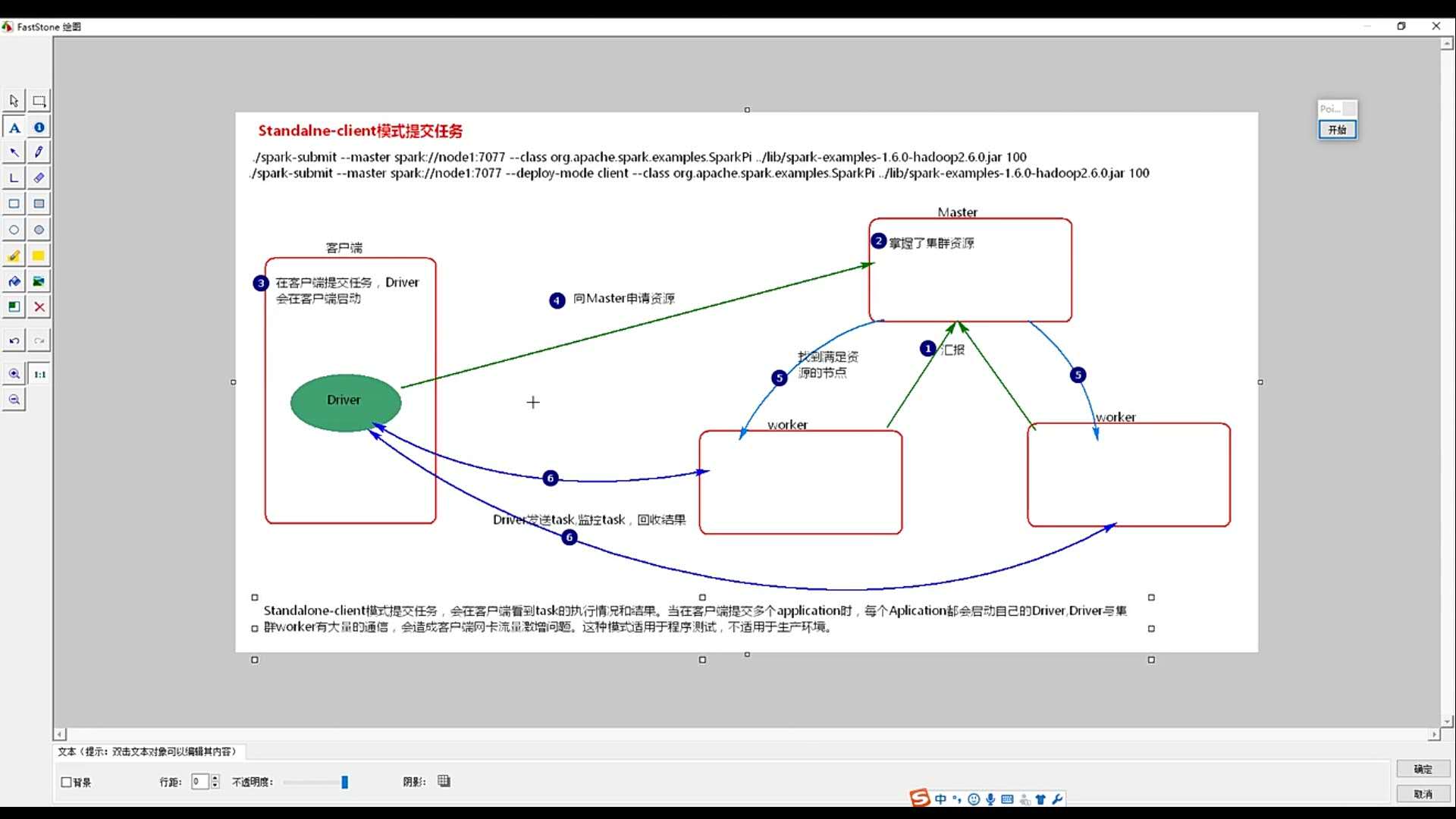
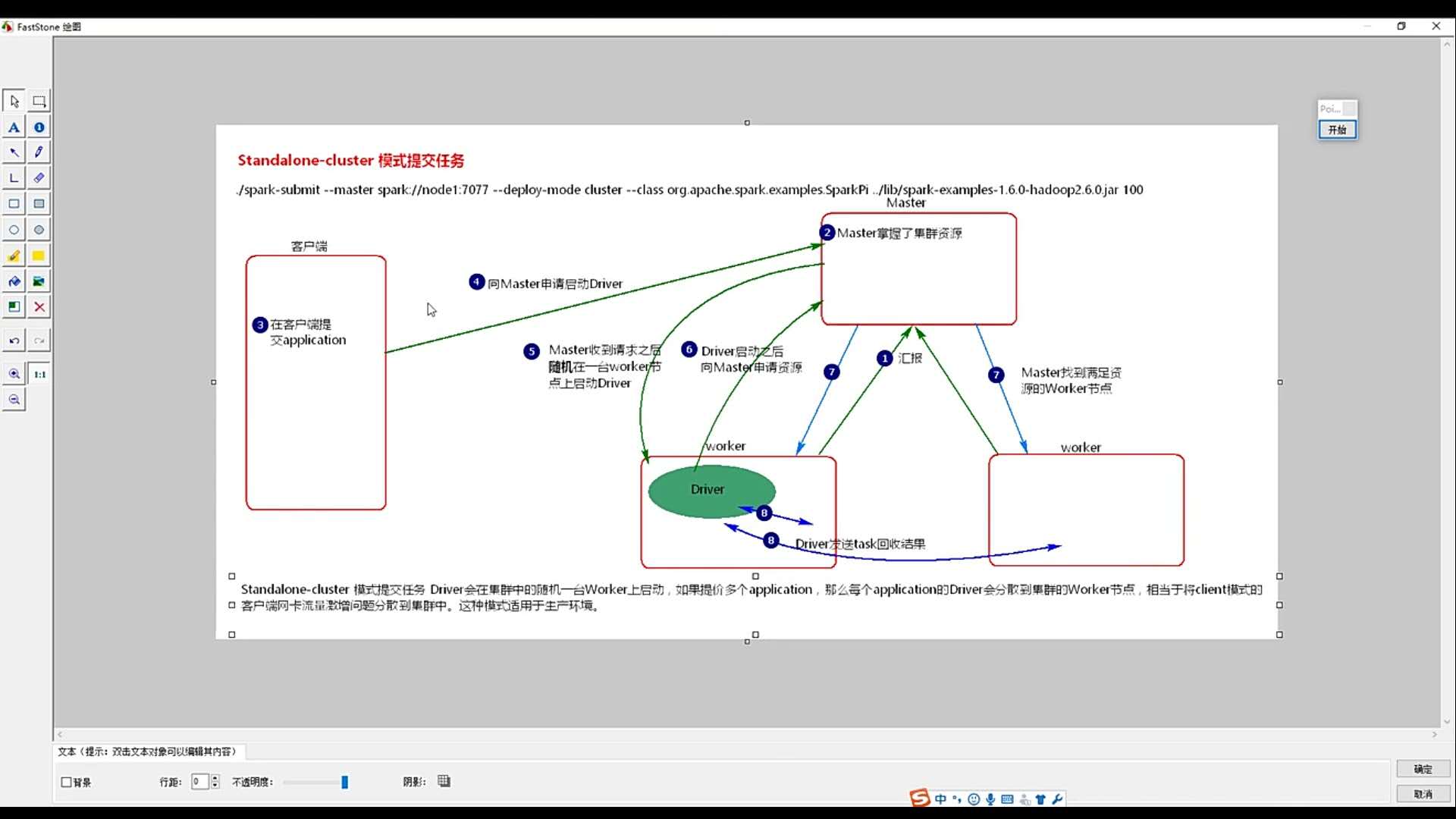
2.standalone模式:
向独立集群管理器提交应用,需要把spark://master:7077作为主节点参数递给spark-submit。下面我们可以运行Spark安装好以后自带的样例程序SparkPi,它的功能是计算得到pi的值(3.1415926)。
在Shell中输入如下命令:
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 examples/jars/spark-examples_2.11-2.0.2.jar 100 2>&1 | grep "Pi is roughly"
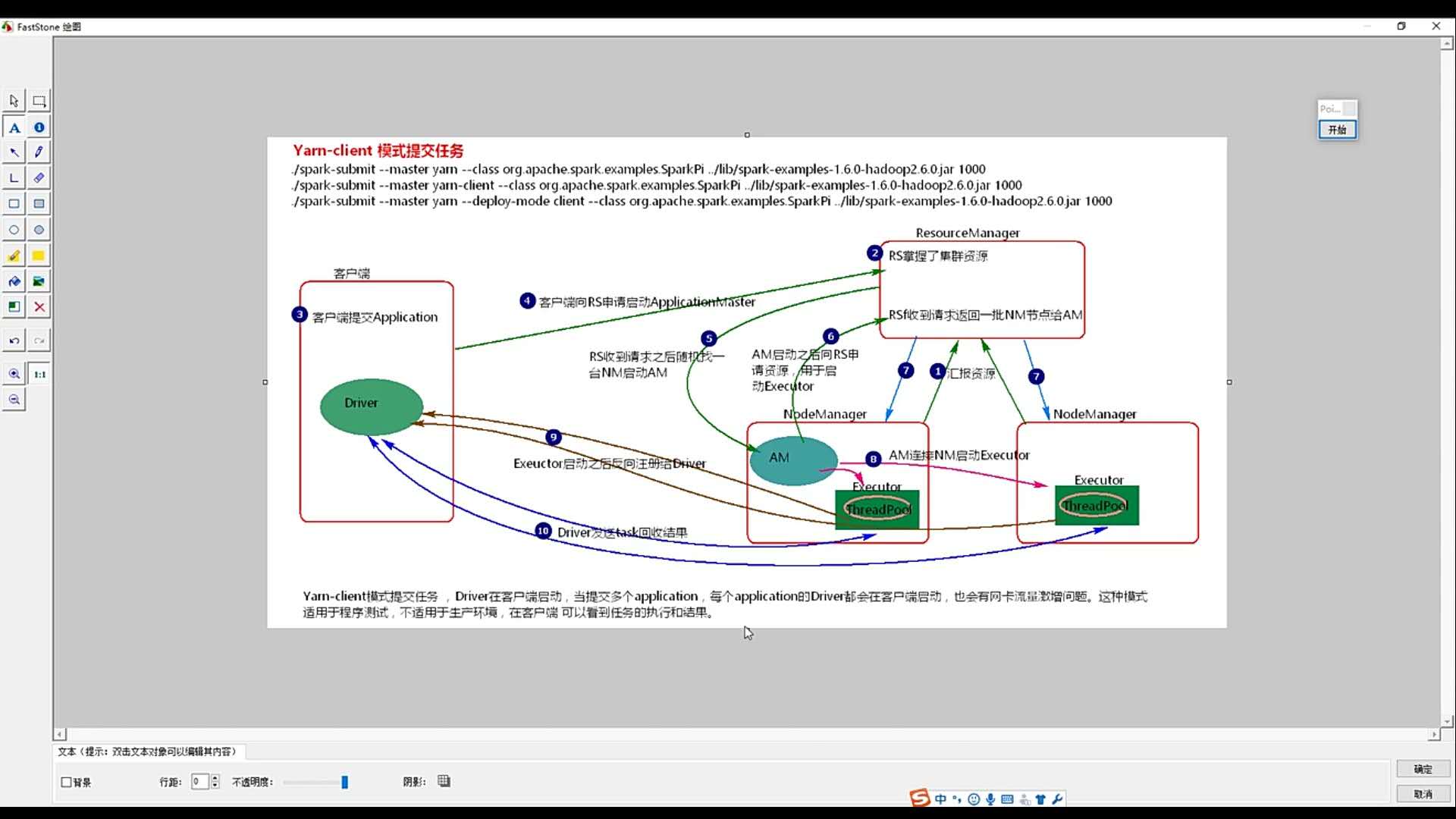
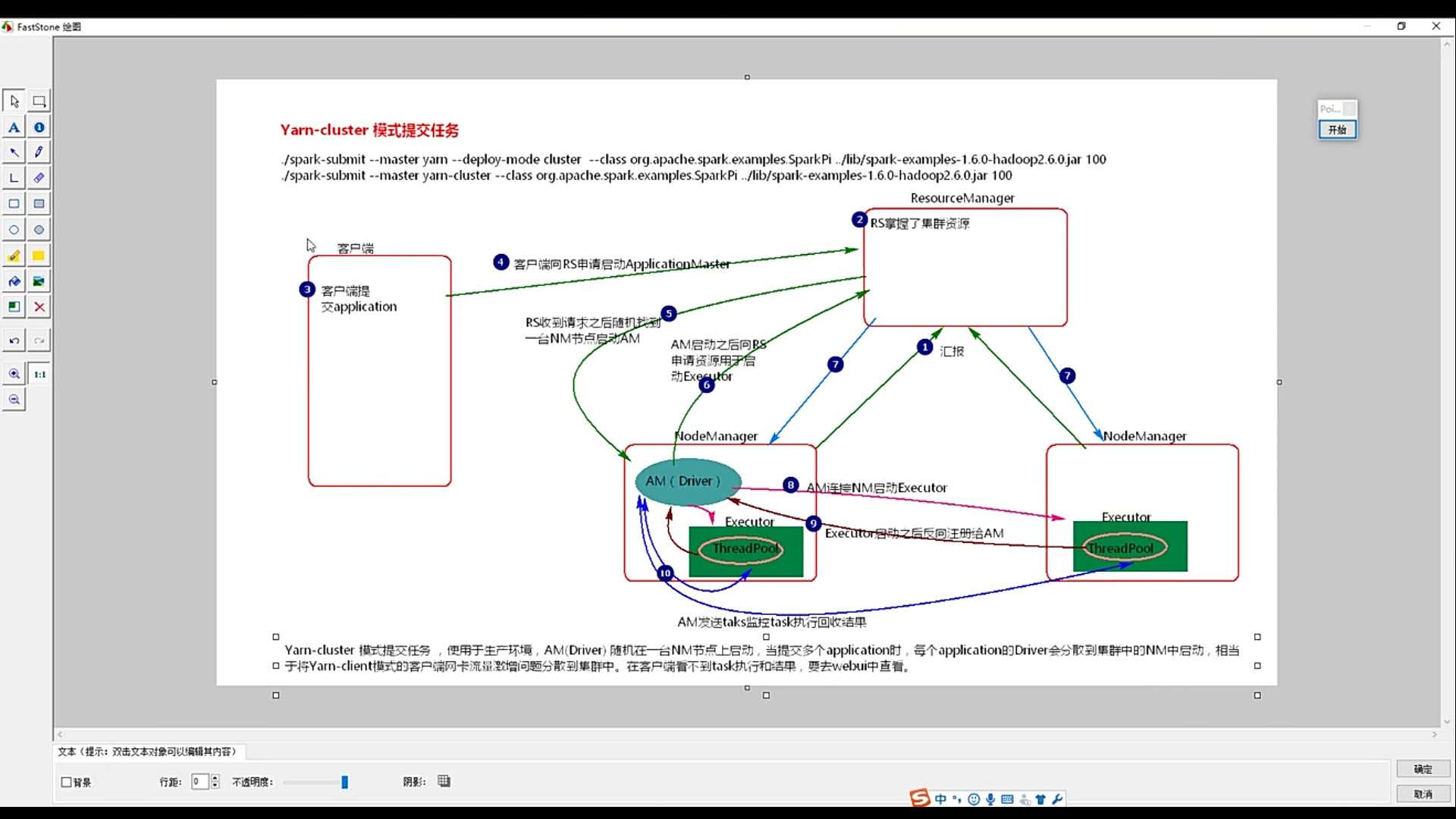
3.hadoop yarn 管理模式:
向Hadoop YARN集群管理器提交应用,需要把yarn-cluster作为主节点参数递给spark-submit。请登录Linux系统,打开一个终端,在Shell中输入如下命令:
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster examples/jars/spark-examples_2.11-2.0.2.jar

输入途中的urI,即可查看任务进程。
向Spark集群提交任务的更多相关文章
- Docker中提交任务到Spark集群
1. 背景描述和需求 数据分析程序部署在Docker中,有一些分析计算需要使用Spark计算,需要把任务提交到Spark集群计算. 接收程序部署在Docker中,主机不在Hadoop集群上.与Spa ...
- Spark系列—01 Spark集群的安装
一.概述 关于Spark是什么.为什么学习Spark等等,在这就不说了,直接看这个:http://spark.apache.org, 我就直接说一下Spark的一些优势: 1.快 与Hadoop的Ma ...
- Spark集群安装与配置
一.Scala安装 1.https://www.scala-lang.org/download/2.11.12.html下载并复制到/home/jun下解压 [jun@master ~]$ cd sc ...
- Spark集群模式&Spark程序提交
Spark集群模式&Spark程序提交 1. 集群管理器 Spark当前支持三种集群管理方式 Standalone-Spark自带的一种集群管理方式,易于构建集群. Apache Mesos- ...
- Spark集群的任务提交执行流程
本文转自:https://www.linuxidc.com/Linux/2018-02/150886.htm 一.Spark on Standalone 1.spark集群启动后,Worker向Mas ...
- Spark集群之yarn提交作业优化案例
Spark集群之yarn提交作业优化案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.启动Hadoop集群 1>.自定义批量管理脚本 [yinzhengjie@s101 ...
- Eclipse提交代码到Spark集群上运行
Spark集群master节点: 192.168.168.200 Eclipse运行windows主机: 192.168.168.100 场景: 为了测试在Eclipse上开发的代码在Spa ...
- 将java开发的wordcount程序提交到spark集群上运行
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤. 第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /s ...
- Spark集群任务提交流程----2.1.0源码解析
Spark的应用程序是通过spark-submit提交到Spark集群上运行的,那么spark-submit到底提交了什么,集群是怎样调度运行的,下面一一详解. 0. spark-submit提交任务 ...
随机推荐
- Docker入门 - 006 Docker 多种数据库的安装
Docker 安装 MySQL 查找Docker Hub上的mysql镜像 root@VM_16_14_centos ~# docker search mysql INDEX NAME DESCRIP ...
- Light OJ 1012
经典搜索水题...... #include<bits/stdc++.h> using namespace std; const int maxn = 20 + 13; const int ...
- SP2-0734: 未知的命令开头 "exp wlc/ra..." - 忽略了剩余的行。
SP2-0734: 未知的命令开头 "exp wlc/ra..." - 忽略了剩余的行. 原来只需要在 $exp wlc/radial_wlc123@ora11g owner=w ...
- PL/SQL设置
PL/SQL 自定义快捷键(比如输入s,直接就显示select * from) 1.1 修改Code assistant快捷键tools->preferences->User Interf ...
- LuoGu P1541 乌龟棋
题目传送门 乌龟棋我并不知道他为啥是个绿题0.0 总之感觉思维含量确实不太高(虽然我弱DP)(毛多弱火,体大弱门,肥胖弱菊,骑士弱梯,入侵弱智,沙华弱Dp) 总之,设计出来状态这题就很简单了 设 f[ ...
- thinkphp (tcms)
使用的是:3.2.3模板: js获取thinkphp数组时:var obj = {:json_encode($obj)}: 转成js对象:进而再处理: 创建公共控制器: thinkphp:ajax返回 ...
- django 中自定义过滤器
多参数过滤器
- verilog 异步复位代码
module reset_sync (input clk, input reset_in, output reset_out); (* ASYNC_REG = 'b1; (* ASYNC_REG = ...
- func_get_args函数
func_get_args ------获取一个函数的所有参数 function foo() { $numargs = func_num_args(); //参数数量 echo "参数个数是 ...
- 渗透测试(theharvester >>steghide)
1.不喜欢自己搭建平台来做测试,所以啦..... 网络信息安全漏洞的威胁总结起来就是人的漏洞,拿DNS服务器来说,一般不出现问题就不会管他,所以很多会被黑客利用,DNS服务器保存了企业内部的IP地址列 ...