Spark 集群 任务提交模式
Spark 集群的模式及提交任务的方式
- 本文大致的内容图
Spark 集群的两种模式:
Standalone 模式
Standalone-client 任务提交方式
提交命令
./spark-submit
--master spark://node1:7077 (主节点的位置)
--class 类的包+类名
jar包的位置
1000 # 分区参数, 也可以说是并行度
||
./spark-submit
--master spark://node1:7077
--deploy-mode client
--class 类的包+类名
jar包的位置
100 # 分区参数, 也可以说是并行度
执行原理

执行流程
- client 模式提交任务后, 会在客户端启动Driver进程
- Driver 会向 Master 申请启动 Application启动的资源
- 资源申请成功, Driver 端将 task 发送到 worker端执行
- Worker 端将 task 执行结果 返回 到 Driver 端
总结
- client模式适用于测试调试程序。
- Driver进程是在客户端启动的。这里的客户端指的是应用程序的当前节点
- 在Driver端可以看到task执行的情况。
- 生产环境下不能使用client模式是因为: 假设提交100个 Application 到集群运行, Driver每次都会在client端启动, 那么就会导致客户端100次网卡流量暴增。
Standalone-cluster 任务提交方式
提交命令
./spark-submit
--master spark://node1:7077
--deploy-mode cluster
--class 包+类名
jar包的位置
100 # 分区参数, 也可以说是并行度 #注意:Standalone-cluster提交方式,应用程序使用的所有jar包和文件,必须保证所有的worker节点都要有,因为此种方式,spark不会自动上传包。
# 解决方式:
# 1.将所有的依赖包和文件打到同一个包中,然后放在hdfs上。
# 2.将所有的依赖包和文件各放一份在worker节点上。
执行原理
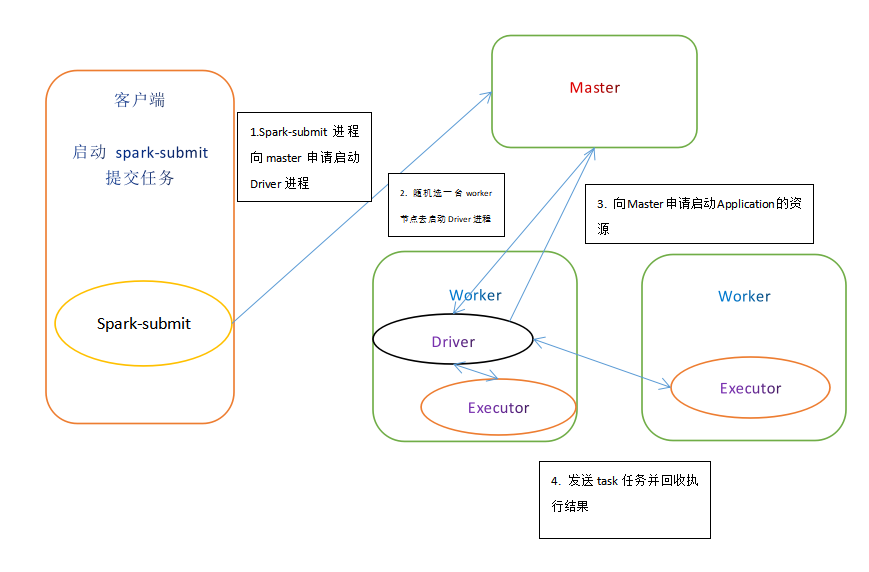
执行流程
- cluster模式提交应用程序后会先向 Master 请求启动 Driver
- Master 接收请求, 随机在集中的一台节点启动Driver进程
- Driver启动后为当前的应用程序申请资源
- Driver端发送task到worker节点上执行
- worker 将执行情况和执行结果返回 Driver
总结
- Standalone-cluster 运行方式适用于生产环境
- 此时在driver端界面看不到执行任务情况
- 由于driver会被随机分配到worker节点上启动, 那么不会有流量激增问题
On Yarn 模式
Yarn-client 任务提交方式
提交命令
./spark-submit
--master yarn
--class 包+类名
jar文件位置
100
||
./spark-submit
--master yarn–client
--class 包+类名
jar文件位置
100
||
./spark-submit
--master yarn
--deploy-mode client
--class 包+类名
jar文件位置
100
执行原理
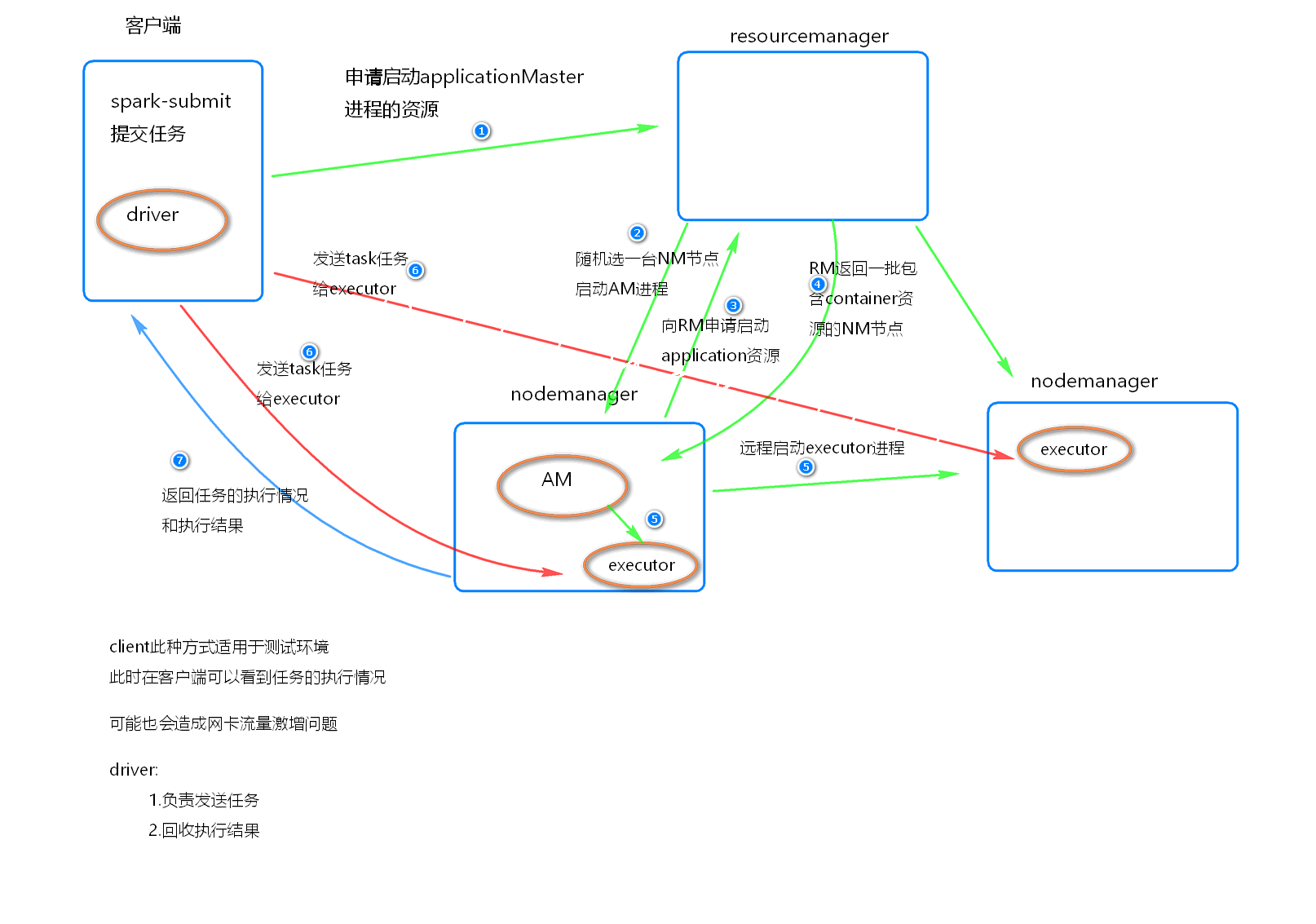
执行流程
- 客户端提交一个 Application, 在客户端启动一盒Driver 进程。
- 应用程序启动后会向RM(ResourceManager) 发送请求, 启动AM(ApplicationMaster)
- RM 收到请求, 随机选择一台 NM(NodeManager)启动AM。这里的NM相当于Standalone中的Worker节点
- AM 启动后, 会向 RS 请求一批container资源, 用于启动Executor
- RM会找到一批NM返回给AM, 用于启动Executor
- AM会向NM发送命令启动Executor
- Executor 启动后, 会反向注册给Driver, Driver 发送 task 到 Executor, 执行情况和结果返回给Driver端
总结
Yarn-client模式同样适用于测试, 因为Driver运行在本地, Driver会与yarn集群中的Executor 进行大量的通信, 会造成客户机网卡流量的大量增加
ApplicationMaster 的作用:
为当前的Application申请资源
给NodeManager发送消息启动Executor
Yarn-cluster 任务提交方式
提交命令
./spark-submit
--master yarn
--deploy-mode cluster
--class 包+类名
jar文件位置
100
||
/spark-submit
--master yarn-cluster
--class 包+类名
jar文件位置
100
执行原理
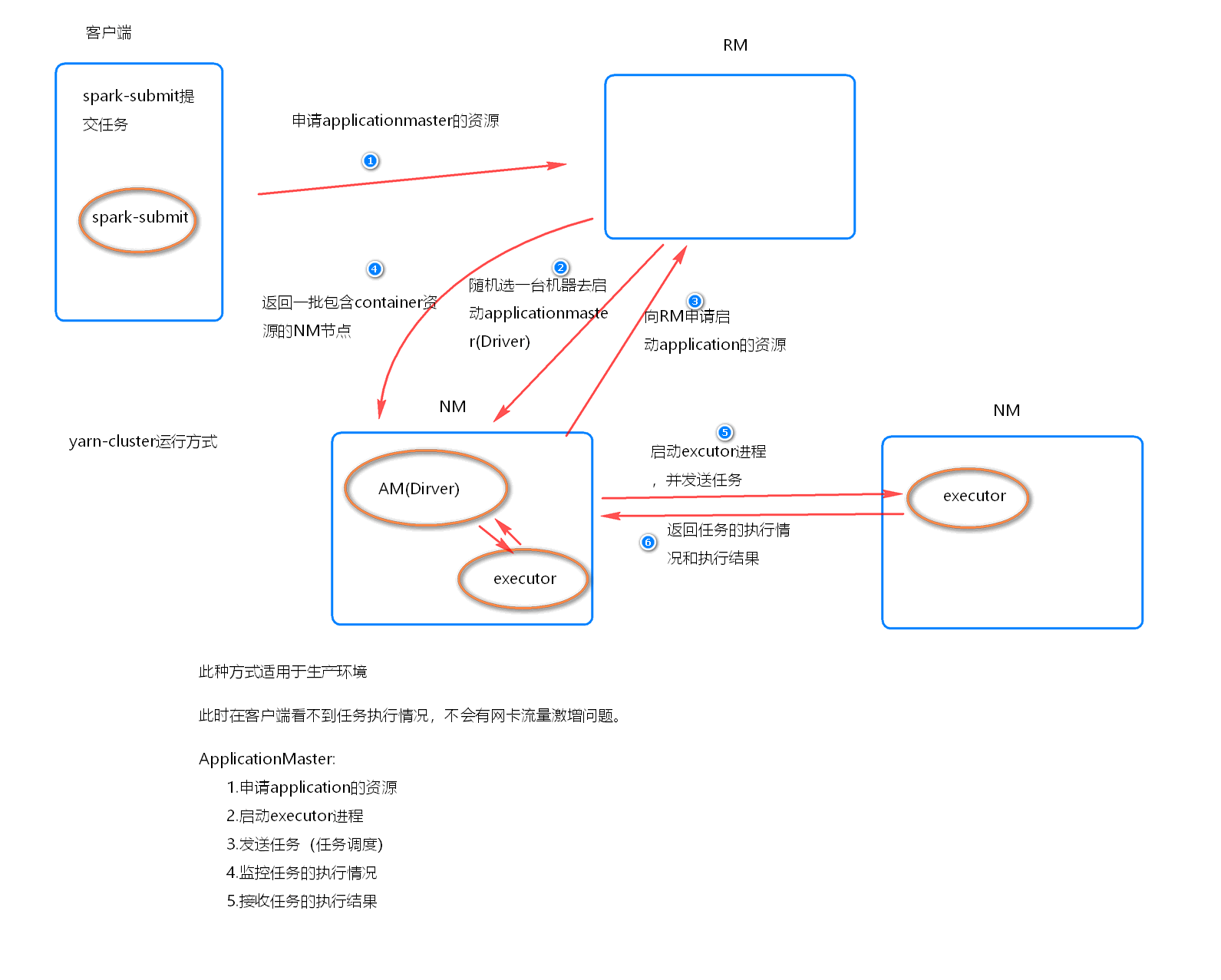
执行流程
- 客户机提交Application应用程序, 发送请求到RM(ResourceManager), 请求启动(ApplicationMaster)
- RM收到请求后随即在一台 NM(NodeManager) 上启动 AM(相当于Driver 端)
- AM启动后, AM 发送请求到 RM, 申请一批容器(container)来启动Executor
- RM 返回一批 NM 节点 给 AM
- AM 连接到 NM, 发送请求到 NM 启动 Executor
- Executor 反向注册到 AM 所在节点的 Driver,Driver再发送task到Executor
总结
- Yarn-Cluster 主要用于生产环境中, 因为 Driver运行在 Yarn 集群中某一台NodeManager中, 每次提交任务的 Driver 所在机器都是随机的, 并不会产生一台机器网卡流量激增的现象。
- 缺点是提交任务不能看到日志, 只能通过yarn查看日志
- ApplicationMaster的作用
- 为当前的 Application 申请资源
- 给NodeManger 发送消息启动 Executor
- 任务调度
Spark 集群 任务提交模式的更多相关文章
- Spark集群任务提交
1. 集群管理器 Spark当前支持三种集群管理方式 Standalone—Spark自带的一种集群管理方式,易于构建集群. Apache Mesos—通用的集群管理,可以在其上运行Hadoop Ma ...
- Spark集群任务提交流程----2.1.0源码解析
Spark的应用程序是通过spark-submit提交到Spark集群上运行的,那么spark-submit到底提交了什么,集群是怎样调度运行的,下面一一详解. 0. spark-submit提交任务 ...
- Spark集群之yarn提交作业优化案例
Spark集群之yarn提交作业优化案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.启动Hadoop集群 1>.自定义批量管理脚本 [yinzhengjie@s101 ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Spark集群模式&Spark程序提交
Spark集群模式&Spark程序提交 1. 集群管理器 Spark当前支持三种集群管理方式 Standalone-Spark自带的一种集群管理方式,易于构建集群. Apache Mesos- ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- Spark集群模式概述
作者:foreyou出处:http://www.foreyou.net/2015/06/22/spark-cluster-mode-overview/声明:本文采用以下协议进行授权: 署名-非商用|C ...
- 向Spark集群提交任务
1.启动spark集群. 启动Hadoop集群 cd /usr/local/hadoop/ sbin/start-all.sh 启动Spark的Master节点和所有slaves节点 cd /usr/ ...
- Spark集群的任务提交执行流程
本文转自:https://www.linuxidc.com/Linux/2018-02/150886.htm 一.Spark on Standalone 1.spark集群启动后,Worker向Mas ...
随机推荐
- pycharm安装报错Non-zero exit co?
pycharm安装第三方库时报错Non-zero exit co? 原因:版本找不到 解决思路: 1.用pip install pandas报错,尝试用python -m pip install -- ...
- MySQL操作之DML
目录 SQL语句的分类 DML语句 SQL语句的分类 DDL(Data Definition Languages)语句:数据定义语言.这些语句定义了不同的数据段. 数据库.表.列.索引等数据库对象的定 ...
- Vue下URL地址栏参数改变却不能刷新界面
在完成毕业设计(基于Vue的信息资讯展示与管理平台)的过程中,处理如下图所示的 点击左侧栏目列表跳转到对应文章列表 的问题时,初次点击可以跳转到对应的页面,但是当第二次点击时,虽然地址栏的参数改变了, ...
- APIView 的请求生命周期
目录 APIView 的请求生命周期 请求解析模块 响应渲染模块 序列化组件 Django 配置 """ 1)应用是否需要在INSTALLED_APPS中注册 在没有使用 ...
- Restful API及接口安全
一.简介 REST(Representational State Transfer,具体状态转移),是一种基于HTTP协议.URI(统一资源定位符).JSON和XML这些现有协议与标准的,针对网络应用 ...
- 三、js提交请求加载启动动画、请求完成成功回调、注销加载动画
1.通过Query post方式进行异步请求方法 jQuery.post(url, [data], [callback], [type]) 参数说明: url:发送请求地址 data:待发送 Key ...
- pytorch 调整tensor的维度位置
target.permute([0, 3, 1, 2]) 一定要使用permute以及中括号 一些在我这里没起到作用的网上的例子: 1. https://blog.csdn.net/zouxiaolv ...
- Django 3.0中不推荐使用的及已经删除的功能
3.0中不推荐使用的功能 django.utils.encoding.force_text()和smart_text()的别名被弃用.如果您的代码支持Python 2,smart_str()并且 fo ...
- 075、Java面向对象之定义匿名对象
01.代码如下: package TIANPAN; class Book { // 定义一个新的类 private String title; // 书的名字 private double price ...
- 通用dao的demo
代码片段 1. [代码]整型映射工具 ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package org.dave.common.databas ...