1.6 Hive配置metastore
一、配置
1、配置文件
#创建配置文件
[root@hadoop-senior ~]# cd /opt/modules/hive-0.13.1/conf/ [root@hadoop-senior conf]# ls
hive-default.xml.template hive-env.sh hive-exec-log4j.properties.template hive-log4j.properties.template [root@hadoop-senior conf]# touch hive-site.xml #
此时可以对比着hive-default.xml.template文件来修改;
hive-default.xml.template是一个模板文件; #hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration> <property>
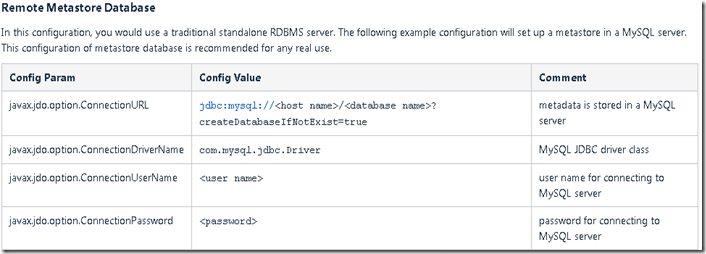
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop-senior.ibeifeng.com:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property> <property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property> </configuration>
hive-site.xml配置文件中,JDBC的配置可参考官网:https://cwiki.apache.org/confluence/display/Hive/AdminManual+Metastore+Administration
jdbc:mysql://hadoop-senior.ibeifeng.com:3306/metastore?createDatabaseIfNotExist=true
- hadoop-senior.ibeifeng.com #mysql主机名
- 3306 #mysql 端口
- metastore #存储hive元数据的库,此库不用创建,会自动生成
- createDatabaseIfNotExist=true #此句就是判断metastore库是否存在的,不存在则自动创建
另外用户名、密码是mysql的,我这里是root、123456
现在hive与mysql是在同一台服务器上;
2、拷贝mysq1驱动jar包,到Hive安装目录的1ib下
[root@hadoop-senior mysql-libs]# tar zxf mysql-connector-java-5.1.27.tar.gz [root@hadoop-senior mysql-libs]# ls
MySQL-client-5.6.24-1.el6.x86_64.rpm mysql-connector-java-5.1.27 mysql-connector-java-5.1.27.tar.gz MySQL-server-5.6.24-1.el6.x86_64.rpm [root@hadoop-senior mysql-libs]# cd mysql-connector-java-5.1.27 [root@hadoop-senior mysql-connector-java-5.1.27]# ls
build.xml CHANGES COPYING docs mysql-connector-java-5.1.27-bin.jar README README.txt src [root@hadoop-senior mysql-connector-java-5.1.27]# cp mysql-connector-java-5.1.27-bin.jar /opt/modules/hive-0.13.1/lib/
3、进入hive
#连接hive
[root@hadoop-senior hive-0.13.1]# bin/hive
Logging initialized using configuration in jar:file:/opt/modules/hive-0.13.1/lib/hive-common-0.13.1.jar!/hive-log4j.properties
hive> #查看mysql库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| metastore |
| mysql |
| performance_schema |
| test |
+--------------------+
5 rows in set (0.00 sec) 可见已经多了一个metastore 库,此库不用创建,是自动生成的; #hive的元数据都在metastore库中,在mysql中查看
mysql> use metastore;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A Database changed
mysql> show tables;
+---------------------------+
| Tables_in_metastore |
+---------------------------+
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| DATABASE_PARAMS |
| DBS |
| FUNCS |
| FUNC_RU |
| GLOBAL_PRIVS |
| PARTITIONS |
| PARTITION_KEYS |
| PARTITION_KEY_VALS |
| PARTITION_PARAMS |
| PART_COL_STATS |
| ROLES |
| SDS |
| SD_PARAMS |
| SEQUENCE_TABLE |
| SERDES |
| SERDE_PARAMS |
| SKEWED_COL_NAMES |
| SKEWED_COL_VALUE_LOC_MAP |
| SKEWED_STRING_LIST |
| SKEWED_STRING_LIST_VALUES |
| SKEWED_VALUES |
| SORT_COLS |
| TABLE_PARAMS |
| TAB_COL_STATS |
| TBLS |
| VERSION |
+---------------------------+
29 rows in set (0.00 sec)
1.6 Hive配置metastore的更多相关文章
- Hive初步使用、安装MySQL 、Hive配置MetaStore、配置Hive日志《二》
一.Hive的简单使用 基本的命令和MySQL的命令差不多 首先在 /opt/datas 下创建数据 students.txt 1001 zhangsan 1002 lisi 1003 wangwu ...
- HIVE配置mysql metastore
HIVE配置mysql metastore hive中除了保存真正的数据以外还要额外保存用来描述库.表.数据的数据,称为hive的元数据.这些元数据又存放在何处呢? 如果不修改配置hive ...
- 【hive】——metastore的三种模式
Hive中metastore(元数据存储)的三种方式: 内嵌Derby方式 Local方式 Remote方式 [一].内嵌Derby方式 这个是Hive默认的启动模式,一般用于单元测试,这种存储方式有 ...
- hive配置以及在启动过程中出现的问题
一.hive配置 1.安装环境 在hadoop-1.2.1集群上安装hive-1.2.1 2.将hive-1.2.1环境变量添加到PATH路径下 使用如下命令打开配置文件 nano /etc/prof ...
- hadoop学习记录(四)hadoop2.6 hive配置
一.安装mysql 1安装服务器 sudo apt-get install mysql-server 2安装mysql客户端 sudo apt-get install mysql-client sud ...
- ubuntu中为hive配置远程MYSQL database
一.安装mysql $ sudo apt-get install mysql-server 启动守护进程 $ sudo service mysql start 二.配置mysql服务与连接器 1.安装 ...
- HA分布式集群二hive配置
一,概念 hive:是一种数据仓库,数据储存在:hdfs上,hsql是由替换简单的map-reduce,hive通过mysql来记录映射数据 二,安装 1,mysql安装: 1,检测是否有mariad ...
- 在Hadoop集群上的Hive配置
1. 系统环境Oracle VM VirtualBoxUbuntu 16.04Hadoop 2.7.4Java 1.8.0_111 hadoop集群master:192.168.19.128slave ...
- 集群搭建之Hive配置要点
注意点: 在启动Hive 的时候要先启动Hadoop和MySQL服务. Mysql 和 Hive 搭建在 yan00机器上. part1:MySQL配置相关 安装和配置相关命令: Yum instal ...
随机推荐
- smali函数分析
一.函数调用 smali中的函数和成员变量也分为两种,分别为 direct 和 virtual 两者的区别 1.direct method 是指private函数 2.virtual method 是 ...
- Day1 [上]- 认识Python
python简单介绍: python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为AB ...
- 使用Caffe完成图像目标检测 和 caffe 全卷积网络
一.[用Python学习Caffe]2. 使用Caffe完成图像目标检测 标签: pythoncaffe深度学习目标检测ssd 2017-06-22 22:08 207人阅读 评论(0) 收藏 举报 ...
- C语言malloc
在子函数里面动态申请的内存不会自动被系统收回的,因为这些空间在堆里面,而不是栈,平常所说的不能返回指向栈的指针,比如在子函数里面定义一个字符指针,指向常量"hello"因为函数调用 ...
- JavaScript事件在WebKit中的处理流程研究
本文主要探讨了JavaScript事件在WebKit中的注冊和触发机制. JS事件有两种注冊方式: 通过DOM节点的属性加入或者通过node.addEventListener()函数注冊: 通过DOM ...
- C# 打开指定的目录 记住路径中 / 与 \ 的使用方法
老生常谈的问题了,C#在指定目录时,路径中要使用 \\.直接看实例 using System; namespace OpenFile{ class OpenFile{ static void Main ...
- build a real-time analytics dashboard to visualize the number of orders getting shipped every minute to improve the performance of their logistics for an e-commerce portal
https://cloudxlab.com/blog/real-time-analytics-dashboard-with-apache-spark-kafka/
- Hadoop实战-使用Eclipse开发Hadoop API程序(四)
一.准备运行所需Jar包 1)avro-1.7.4.jar 2)commons-cli-1.2.jar 3)commons-codec-1.4.jar 4)commons-collections-3. ...
- aop学习总结一------使用jdk动态代理简单实现aop功能
aop学习总结一------使用jdk动态代理实现aop功能 动态代理:不需要为目标对象编写静态代理类,通过第三方或jdk框架动态生成代理对象的字节码 Jdk动态代理(proxy):目标对象必须实现接 ...
- MFC获取电脑硬盘序列号(附源代码)
在新建的project里面加入一个类 即:下面一个类 GetHDSerial.cpp <code class="hljs cs has-numbering" style= ...