在Hadoop集群上的Hive配置
1. 系统环境
Oracle VM VirtualBox
Ubuntu 16.04
Hadoop 2.7.4
Java 1.8.0_111
hadoop集群
master:192.168.19.128
slave1:192.168.19.129
slave2:192.168.19.130
MySQL安装在master机器上,hive服务器也安装在master上
hive版本: https://mirrors.cnnic.cn/apache/hive/hive-2.3.0/apache-hive-2.3.0-bin.tar.gz
2.mysql安装
本文使用MySQL作为远程元数据库,部署在master节点上
2.1安装mysql
安装mysql服务端
sudo apt-get install mysql-server
安装mysql客户端
sudo apt-get install mysql-client
期间会有命令窗口会有跳窗提醒输入密码,一定要记住密码,登录Mysql和后续的配置都需要密码。
2.2.查看mysql服务是否启动
sudo netstat -tap | grep mysql
2.3.设置mysql远程访问
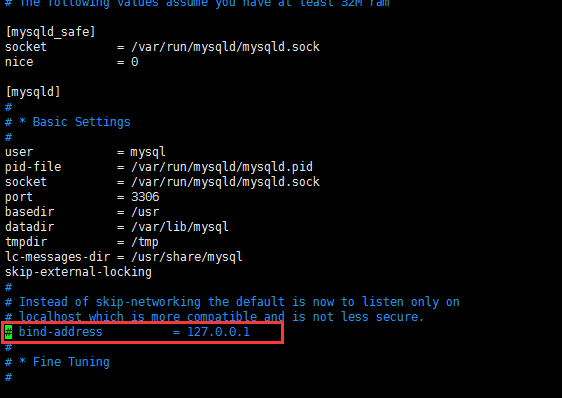
a).编辑mysql配置文件,把其中bind-address = 127.0.0.1注释了
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
b). 使用root进入mysql命令行,执行如下2个命令,示例中mysql的root账号密码就是按照mysql时输入的密码
mysql -u root -p
命令窗口会有提示输入密码,即是安装mysql时输入的密码
c).授权root账户,并授予它远程连接的权力
添加一个用户名是root且密码是root的远程访问用户
grant all on *.* to root@'%' identified by 'root' with grant option;
d).运行完后紧接着输入,以更新数据库:
FLUSH PRIVILEGES;
e).执行quit退出mysql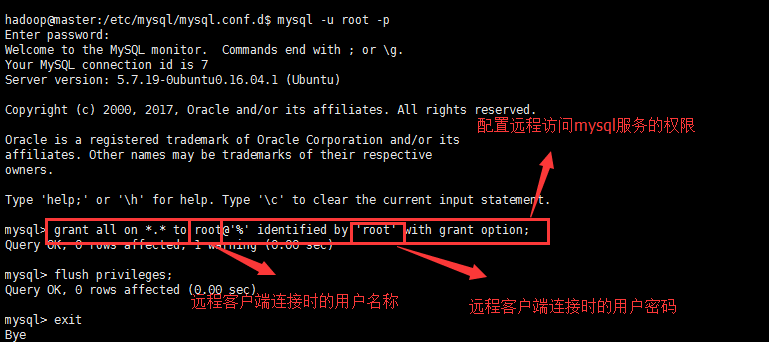
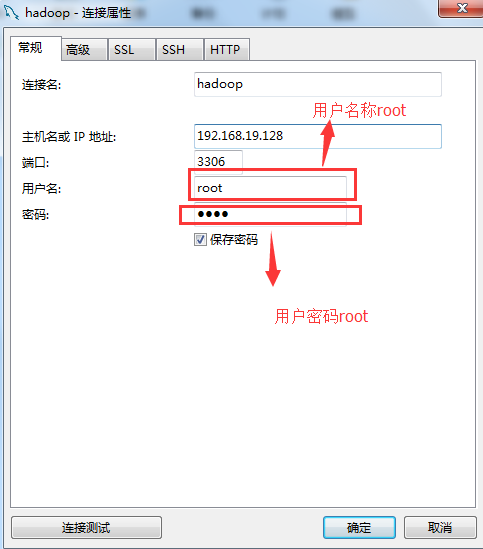
2.4.重启mysql
/etc/init.d/mysql restart
重启成功后,在其他计算机上,便可以登录。
MySQL卸载:
1、sudo apt-get autoremove --purge mysql-server-5.0
2、sudo apt-get remove mysql-server
3、sudo apt-get autoremove mysql-server
4、sudo apt-get remove mysql-common --这个很重要
5、dpkg -l |grep ^rc|awk '{print $2}' |sudo xargs dpkg -P -- 清除残留数据
3.Hive安装配置
3.1.下载Hive安装包
wget https://mirrors.cnnic.cn/apache/hive/hive-2.3.0/apache-hive-2.3.0-bin.tar.gz
3.2.解压
tar -zxfv apache-hive-2.3.0-bin.tar.gz
3.3.将解压后的目录移动到自己指定的安装目录
mv apache-hive-2.3.0-bin /home/hadoop/software/
3.4.配置环境变量
sudo vim /etc/profile
export HIVE_HOME=/home/hadoop/software/apache-hive-2.3.0-bin
export PATH=$HIVE_HOME/bin:$PATH
3.5.使环境变量生效
source /etc/profile
3.6.修改conf/下的几个template模板并重命名
a).复制hive-env.sh.template创建为hive-env.sh
cp hive-env.sh.template hive-env.sh
给hive-env.sh增加执行权限
chmod 755 hive-env.sh
修改conf/hive-env.sh 文件
HADOOP_HOME=/home/hadoop/software/hadoop-2.7.4
b).复制hive-default.xml.template创建为hive-site.xml
cp hive-default.xml.template hive-site.xml
修改hive-site.xml文件内容
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<!--配置缓存目录-->
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hadoop/software/apache-hive-2.3.0-bin/iotmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hadoop/software/apache-hive-2.3.0-bin/iotmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
根据hive-site-xml,创建缓存目录
cd /home/hadoop/software/apache-hive-2.3.0-bin/
mkdir iotmp
3.7.修改 bin/hive-config.sh 文件
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_121
export HIVE_HOME=/home/hadoop/software/apache-hive-2.3.0-bin
export HADOOP_HOME=/home/hadoop/software/hadoop-2.7.4
3.8.下载mysql-connector-java-5.1.44-bin.jar文件,并放到/home/hadoop/software/apache-hive-2.3.0-bin/lib目录下
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.44.tar.gz
解压mysql-connector-java-5.1.44.tar.gz后,将mysql-connector-java-5.1.44-bin.jar放置在lib目录下
4.将apache-hive-2.3.0-bin分发到slave节点
scp -r apache-hive-2.3.0-bin hadoop@slave1:/home/hadoop/software/
scp -r apache-hive-2.3.0-bin hadoop@slave2:/home/hadoop/software/
slave端配置, 修改 conf/hive-site.xml 文件
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
5.Hive的mysql数据库配置
5.1.使用root用户登录mysql数据库
mysql -u root -p
5.2.创建hive用户
mysql> CREATE USER 'hive' IDENTIFIED BY 'hive';
5.3.给hive用户赋权限
mysql> GRANT ALL PRIVILEGES ON *.* TO 'hive'@'%' WITH GRANT OPTION;
5.4.更新数据库
mysql>flush privileges;
mysql> quit
5.5.Hive用户登录
hadoop@master:~$ mysql -u hive -p
5.6.创建Hive数据库
mysql>create database hive;
6.启动Hive
6.1.启动hadoop
6.2. 进入bin目录初始化表数据
hadoop@master:~/software/apache-hive-2.3.0-bin/bin$./schematool -dbType mysql -initSchema
6.3.启动metastore服务
hive –service metastore &
在 master 节点上运行 jps 应该会有RunJar 进程
6.4.服务器端访问
hadoop@master:~$ hive
6.5.客户端(slave)访问
hadoop@slave2:~$ hive
在Hadoop集群上的Hive配置的更多相关文章
- 在Hadoop集群上的HBase配置
之前,我们已经在hadoop集群上配置了Hive,今天我们来配置下Hbase. 一.准备工作 1.ZooKeeper下载地址:http://archive.apache.org/dist/zookee ...
- [转载] 把Nutch爬虫部署到Hadoop集群上
http://f.dataguru.cn/thread-240156-1-1.html 软件版本:Nutch 1.7, Hadoop 1.2.1, CentOS 6.5, JDK 1.7 前面的3篇文 ...
- 把Nutch爬虫部署到Hadoop集群上
原文地址:http://cn.soulmachine.me/blog/20140204/ 把Nutch爬虫部署到Hadoop集群上 Feb 4th, 2014 | Comments 软件版本:Nutc ...
- Hadoop集群上搭建Ranger
There are two types of people in the world. I hate both of them. Hadoop集群上搭建Ranger 在搭建Ranger工程之前,需要完 ...
- Hadoop集群搭建-02安装配置Zookeeper
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
- Hadoop集群上使用JNI,调用资源文件
hadoop是基于java的数据计算平台,引入第三方库,例如C语言实现的开发包将会大大增强数据分析的效率和能力. 通常在是用一些工具的时候都要用到一些配置文件.资源文件等.接下来,借一个例子来说明ha ...
- hadoop 把mapreduce任务从本地提交到hadoop集群上运行
MapReduce任务有三种运行方式: 1.windows(linux)本地调试运行,需要本地hadoop环境支持 2.本地编译成jar包,手动发送到hadoop集群上用hadoop jar或者yar ...
- MapReduce编程入门实例之WordCount:分别在Eclipse和Hadoop集群上运行
上一篇博文如何在Eclipse下搭建Hadoop开发环境,今天给大家介绍一下如何分别分别在Eclipse和Hadoop集群上运行我们的MapReduce程序! 1. 在Eclipse环境下运行MapR ...
- Hadoop集群搭建-05安装配置YARN
Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hadoop集群搭建-01前期准备 先保证集群5台虚 ...
随机推荐
- 281. Zigzag Iterator z字型遍历
[抄题]: Given two 1d vectors, implement an iterator to return their elements alternately. Example: Inp ...
- swift 需求: 导航栏和HeaderView 使用一个背景图片。
问题界面 需求: 导航栏和HeaderView 使用一个背景图片.解决方案: 让 导航栏 变成透明. override func viewWillAppear(_ animated: Bool) { ...
- LWIP学习
转自:https://blog.csdn.net/kzq_qmi/article/details/46900589 数据包pbuf: LwIP采用数据结构 pbuf 来描述数据包,其结构如下: ...
- centos 7 安装pip
1.首先检查centos 有没有安装python-pip 包, >>yum install python-pipnotice:NO package python-pip available ...
- Python开发——数据类型【字典】
字典的定义 # Python语言中唯一的类型映射 # 键与值之间用“:”分开 # 项与项之间用“,”分开 person = {"name":"yuan",&qu ...
- jdk8 永久代变更
java8 去掉了永久代permgen(又称非堆,其实也是堆的一部分),类的方法代码,常亮,方法名,静态变量等存放在永久代中 改为使用元空间 Metaspace , Metaspace 不在是堆的一部 ...
- 79、iOS 的Cocoa框架、Foundation框架以及UIKit框架
Cocoa框架是iOS应用程序的基础 1. Cocoa是什么? Cocoa是 OS X和ios 操作系统的程序的运行环境. 是什么因素使一个程序成为Cocoa程序呢?不是编程语言,因为在Cocoa开发 ...
- vue子传父多个值
子组件:this.$emit("methdosName",data1,data2,data3) 父组件: <child @methodsName="xxx(argu ...
- Clion pycharm激活码(可使用到2019年2月)
D87IQPUU3Q-eyJsaWNlbnNlSWQiOiJEODdJUVBVVTNRIiwibGljZW5zZWVOYW1lIjoiTnNzIEltIiwiYXNzaWduZWVOYW1lIjoiI ...
- spring boot开发笔记——mybatis
概述 mybatis框架的优点,就不用多说了,今天这边干货主要讲mybatis的逆向工程,以及springboot的集成技巧,和分页的使用 因为在日常的开发中,当碰到特殊需求之类会手动写一下s ...