序列比对之Biostrings包
基本概念
Biostrings包很重要的3个功能是进行Pairwise sequence alignment 和Multiple sequence alignment及 Pattern finding in a sequence
序列比对一般有2个过程:
1)构建计分矩阵公式(the scoring matrix formulation)
2)比对(alignment itself)
global alignment methods (全局比对):align every residue in the sequences ,例如Needleman-Wunsch algorithm.
local alignment technique(局部比对): align regions of high similarity in the sequences,例如Smith-Waterman algorithm
安装
if("Biostrings" %in% rownames(installed.packages()) == FALSE) {source("http://bioconductor.org/biocLite.R");biocLite("Biostrings")}
suppressMessages(library(Biostrings))
ls('package:Biostrings')
----------------Pairwise sequence alignment---------------
步骤:首先构建罚分规则,然后按照规则进行比对。用pairwiseAlignment()函数
举例1:核酸序列
(myScoringMat <- nucleotideSubstitutionMatrix(match = 1, mismatch = -1, baseOnly = TRUE))#构建罚分规则
gapOpen <- 2 #gap分为2
gapExtend <- 1 #延伸gap分为1 sequence1 <- "GAATTCGGCTA" #序列1
sequence2 <- "GATTACCTA" #序列2
myAlignment <- pairwiseAlignment(sequence1, sequence2,
substitutionMatrix = myScoringMat, gapOpening = gapOpen,
gapExtension = gapExtend, type="global", scoreOnly = FALSE) #进行比对
myAlignment

举例2:对蛋白序列进行比对
蛋白比对会更复杂,因此模型更多,
data(package="Biostrings") #查看所有数据集
data(BLOSUM62) #这里选择BLOSUM62数据
subMat <- "BLOSUM62" #赋值
gapOpen <- 2
gapExtend <- 1
sequence1 <- "PAWHEAE"
sequence2 <- "HEAGAWGHE"
myAlignProt <- pairwiseAlignment(sequence1, sequence2,
substitutionMatrix = subMat, gapOpening = gapOpen, gapExtension =
gapExtend, type="global", scoreOnly = FALSE) #全局比对
myAlignProt2 <- pairwiseAlignment(sequence1, sequence2,
substitutionMatrix = subMat, gapOpening = gapOpen, gapExtension =
gapExtend, type="local",scoreOnly = FALSE) ##局部比对
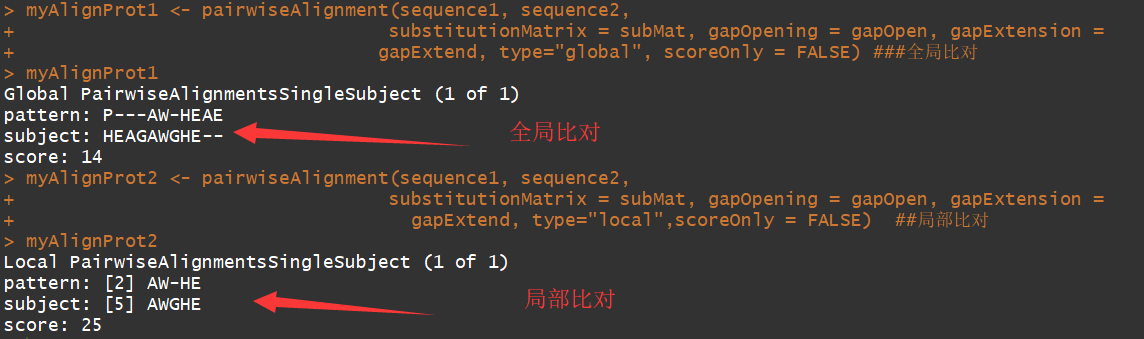
可以看到局部比对返回的是,高度相似的序列部分.
3)可视化,对于序列可以用最经典的对角线来可视化(以人和黑猩猩的hemoglobin beta为例)
library(seqinr) # 为了读取fasta序列
myseq <- read.fasta(file = "F:/R/Bioconductor/biostrings/prtein_example_seq.fas")
dotPlot(myseq[[1]], myseq[[2]], col=c("white", "red"), xlab="Human", ylab="Chimpanzee")

##########Multiple sequence alignment############
一般多序列比对可以用于进化分析
install.packages("muscle") #需要安装该包,因为该包在我的版本上没法安装,所以这里就不讲了
library(muscle)
######Phylogenetic analysis and tree plotting########
这里先不做分析
#########blast格式的解析######
install.packages("RFLPtools",dependencies=TRUE)
library(RFLPtools)
data(BLASTdata) #先查看数据集了解一下相关数据格式情况
head(BLASTdata)
colnames(BLASTdata)
DIR <- system.file("extdata", package = "RFLPtools") #用自带数据集
MyFile <- file.path(DIR, "BLASTexample.txt")
MyBLAST <- read.blast(file = MyFile)
mySimMat <- simMatrix(MyBLAST) #可以根据blast结果用来生成相似性矩阵,太厉害了
#########Pattern finding in a sequence######
library(Biostrings)
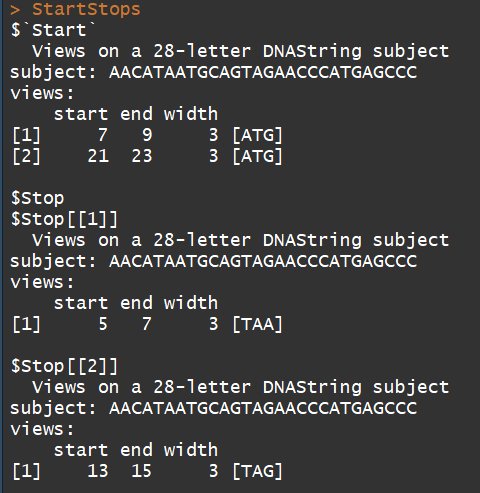
mynucleotide <- DNAString("aacataatgcagtagaacccatgagccc")
matchPattern(DNAString("ATG"), mynucleotide) #示例1
matchPattern("TAA", mynucleotide) #示例2
##以下函数可以用来寻找orf(需要修改)
myCodonFinder <- function(sequence){
startCodon = DNAString("ATG") # 指定起始密码子
stopCodons = list("TAA", "TAG", "TGA") # 指定终止密码子
codonPosition = list() #initialize the output to be returned as a list
codonPosition$Start = matchPattern(startCodon, sequence) # search start codons
x=list()
for(i in 1:3){ # iterate over all stop codons
x[[i]]= matchPattern(DNAString(stopCodons[[i]]), sequence)
codonPosition$Stop=x
}
return(codonPosition) # returns results
}
StartStops <- myCodonFinder(mynucleotide)
序列比对之Biostrings包的更多相关文章
- Python_序列与映射的解包操作
解包就是把序列或映射中每个元素单独提取出来,序列解包的一种简单用法就是把首个或前几个元素与后面几个元素分别提取出来,例如: first, seconde, *rest = sequence 如果seq ...
- Python 序列与映射的解包操作
解包就是把序列或映射中每个元素单独提取出来,序列解包的一种简单用法就是把首个或前几个元素与后面几个元素分别提取出来,例如: first, seconde, *rest = sequence 如果seq ...
- Python 序列与映射的解包操作-乾颐堂
解包就是把序列或映射中每个元素单独提取出来,序列解包的一种简单用法就是把首个或前几个元素与后面几个元素分别提取出来,例如: first, seconde, *rest = sequence 如果seq ...
- python基础之打/解包及运算符与控制流程
python基础之打/解包及运算符与控制流程 python中的解压缩(即序列类型的打包和解包) python提供了两个设计元祖和其他序列类型的处理的便利,也就是自动打包与自动解包功能,比如: data ...
- Oracle学习笔记一 初识Oracle
数据库简介 数据库(Database)是按照数据结构来组织.存储和管理数据的仓库.SQL 是 Structured Query Language(结构化查询语言)的首字母缩写词. 定义 数据库,简单来 ...
- Makefile <网络转载>
陈皓 (CSDN)概述——什 么是makefile?或许很多Winodws的程序员都不知道这个东西,因为那些Windows的IDE都为你做了这个工作,但我觉得要作一个好的和 professional的 ...
- oracle 体系结构
oracle 体系结构 数据库的体系结构是指数据库的组成.工作过程与原理,以及数据在数据库中的组织与管理机制. 1. oracle工作原理: 1).在数据库服务器上启动Oracle实例:2).应用程序 ...
- Navicat for Oracle实现连接Oracle
不知道为什么,从一开始,我就不喜欢Oracle,名字好听,功能强大,但总感觉"高不可攀";或许是因为我觉得其他的数据库就可以解决数据问题,不太了解Oracle的优势:而且它长得也不 ...
- 三、oracle 体系结构
1.oracle内存由SGA+PGA所构成 2.oracle数据库体系结构数据库的体系结构是指数据库的组成.工作过程与原理,以及数据在数据库中的组织与管理机制. oracle工作原理: 1).在数据库 ...
随机推荐
- RedHat Enterprise Linux7.0安装Oracle12c
1. 验证 1.1 硬盘空间要求 1.1.1 安装盘 类型 占用磁盘空间 Enterprise Edition 6.4GB Standard Edition 6.1GB Standard Editio ...
- C# 关于out和ref的问题
http://bbs.csdn.net/topics/320214035 问题: C#里非基础类型传参数都是以引用类型的方式,那么换句话说,out和ref除了基础类型外,实际上没有任何意义?是不是这么 ...
- php 加密 解密 方法
base64 Base64编码可用于在HTTP环境下传递较长的标识信息 base64_encode base64_decodeserialize 可以将 ...
- SpringCloud中接收application/json格式的post请求参数并转化为实体类
@CrossOrigin(allowCredentials="true", allowedHeaders="*", methods={RequestMethod ...
- 浏览器缩放导致的样式bug
缩放75% 这种问题修改的话 要兼顾多种浏览器,并且有些地方样式是要求写死的,修改成本会比较大,所以一般是不会去处理的
- java实验二——输出一个指定整数的所有质因数
import java.util.Scanner; public class 实验二 { /** * @param args */ public static void main(String[] a ...
- MySQL 二进制文件恢复
先不说话 先来一段代码块 mysql> show variables like 'autocommit'; +---------------+-------+ | Variable_name ...
- 1042 Shuffling Machine (20 分)
1042 Shuffling Machine (20 分) Shuffling is a procedure used to randomize a deck of playing cards. Be ...
- 【基础知识六】支持向量机SVM
开发库: libsvm, liblinear GitHub地址 SVM难点:核函数选择 一.基本问题 找到约束参数ω和b,支持向量到(分隔)超平面的距离最大:此时的分隔超平面称为“最优超平面 ...
- Windows10环境下loadrunner11 安装
loadrunner11安装包下载:链接:https://pan.baidu.com/s/12AVNtopwuA-UDsoxbbLgoQ 密码:deaf 链接:https://pan.baidu.co ...