MapReduce程序(一)——wordCount
写在前面:WordCount的功能是统计输入文件中每个单词出现的次数。基本解决思路就是将文本内容切分成单词,将其中相同的单词聚集在一起,统计其数量作为该单词的出现次数输出。
1.MapReduce之wordcount的计算模型
1.1 WordCount的Map过程
假设有两个输入文本文件,输入数据经过默认的LineRecordReader被分割成一行行数据,再经由map()方法得到<key, value>对,Map过程如下:
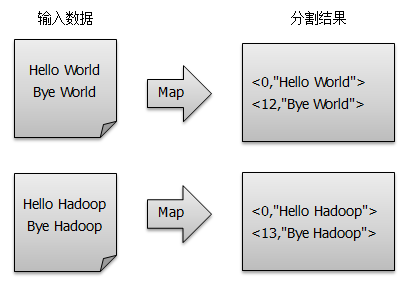

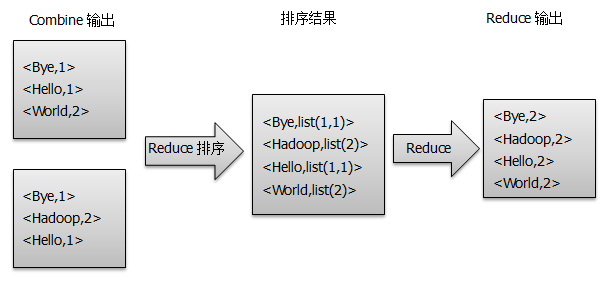
得到map方法输出的< key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key值相同的value值累加,得到Mapper的最终输出结果,如图所示:

1.2 WordCount的Reduce过程
Reducer对从Mapper端接收的数据进行排序,之后由reduce()方法进行处理,将相同主键下的所有值相加,得到新的<key, value>对作为最终的输出结果,如图所示:
2. 打包运行WordCount程序
通过Eclipse来编译打包运行自己写的MapReduce程序(基于Hadoop 2.6.0)。
2.1 下载所需的驱动包
下载地址Group: org.apache.hadoop下载对应版本的驱动包:
- hadoop-common-2.6.0.jar
- hadoop-mapreduce-client-core-2.6.0.jar
- hadoop-test-1.2.1.jar
2.2 创建新的工程
- 使用Eclipse创建名为WordCount的Java Project;
- 在
Project Properties -> Java Build Path -> Libraries -> Add External Jars添加第一步所下载Jar包, 点击OK; - 创建WordCount.java源文件:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable();
private Text word = new Text();
/*
* LongWritable 为输入的key的类型
* Text 为输入value的类型
* Text-IntWritable 为输出key-value键值对的类型
*/
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString()); // 将TextInputFormat生成的键值对转换成字符串类型
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
/*
* Text-IntWritable 来自map的输入key-value键值对的类型
* Text-IntWritable 输出key-value 单词-词频键值对
*/
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = ;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); // job的配置
Job job = Job.getInstance(conf, "word count"); // 初始化Job
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[])); // 设置输入路径
FileOutputFormat.setOutputPath(job, new Path(args[])); // 设置输出路径
System.exit(job.waitForCompletion(true) ? : );
}
}
2.3 打包源文件
- 在Eclipse -> File ->Export -> Java ->JAR file ->next
- 选中新建的WordCount工程,设置相应的输出路径和文件名(这里的输出路径一定要记下来,后面会用到),FInish
- 在设置的输出路径处生成了WordCount.jar,至此,打包完毕。
2.4 启动HDFS服务
打开Terminal,进入目录/usr/local/Cellar/hadoop/2.6.0/sbin
$ start-dfs.sh #启动HDFS
$ jps #验证是否启动成功
1666
2503 SecondaryNameNode
2920 Jps
2317 NameNode
2399 DataNode
成功启动服务后, 可以直接在浏览器中输入http://localhost:50070/访问Hadoop页面
2.5 将文件上传到HDFS
进入目录/usr/local/Cellar/hadoop/2.6.0/bin
#在HDFS上创建输入/输出文件夹
$ hdfs dfs -mkdir /user
$ hdfs dfs -mkdir /user/input
$ hdfs dfs -ls /user
#上传本地file中文件到集群的input目录下
$ hdfs dfs -put /Users/&&&&&&&&/Downloads/test* /user/input
#查看上传到HDFS输入文件夹中到文件
$ hadoop fs -ls /user/input
#输出结果
-rw-r--r-- 1 &&&&&& supergroup 666 2015-04-06 10:49 /user/input/test01.html
-rw-r--r-- 1 &&&&&& supergroup 9708 2015-04-06 14:25 /user/input/test02.html
2.6 运行JAR文件
#在当前文件夹创建一个工作目录
$ mkdir WorkSpace
#下面这句可以不用,只要运行程序时,正确写入jar所在的完整路径即可
#将打包好的Jar复制到当前工作目录下(复制前路径就是你打包Jar时的存储路径)
$ cp /Users/&&&&&/Desktop/WorkCount.jar ./WorkSpace #运行Jar文件,各字段含义:hadoop是运行命令命令,jar WorkSpace/WordCount.jar指定Jar文件,WordCount指定Jar文件入口类,/user/input指定job的HDFS上得输入文件目录,output指定job的HDFS输出文件目录
$ hadoop jar WorkSpace/WordCount.jar WordCount /user/input /user/output
#这里input和output在同一user目录中,方便管理
显示如下结果,则说明运行成功:
……省略大量代码
2.7 查看运行结果
$ hdfs dfs -ls /user/output Found items
-rw-r--r-- xumengting supergroup -- : output/_SUCCESS
-rw-r--r-- xumengting supergroup -- : output/part-r-00000 #查看结果输出文件中的内容
$ hdfs dfs -cat /user/output/part-r-00000
结果文件一般由2部分组成:
- _SUCCESS文件:表示MapReduce运行成功。
- part-r-00000文件:存放结果,也是默认生成的结果文件
参考文献:
[1]. 【Hadoop基础教程】5、Hadoop之单词计数——http://blog.csdn.net/andie_guo/article/details/44055863
[2]. MapReduce之Wordcount——http://andrewliu.tk/2015/03/29/MapReduce%E4%B9%8BWordCount/#more
[3]. Mac下Hadoop的配置及在Eclipse上编程
MapReduce程序(一)——wordCount的更多相关文章
- mapreduce程序编写(WordCount)
折腾了半天.终于编写成功了第一个自己的mapreduce程序,并通过打jar包的方式运行起来了. 运行环境: windows 64bit eclipse 64bit jdk6.0 64bit 一.工程 ...
- 运行第一个MapReduce程序,WordCount
1.安装Eclipse 安装后如果无法启动重新配置Java路径(如果之前配置了Java) 2.下载安装eclipse的hadoop插件 注意版本对应,放到/uer/lib/eclipse/plugin ...
- Hadoop学习之路(5)Mapreduce程序完成wordcount
程序使用的测试文本数据: Dear River Dear River Bear Spark Car Dear Car Bear Car Dear Car River Car Spark Spark D ...
- MapReduce 程序:WordCount
- MapReduce程序——WordCount(Windows_Eclipse + Ubuntu14.04_Hadoop2.9.0)
本文主要参考<Hadoop应用开发技术详解(作者:刘刚)> 一.工作环境 Windows7: Eclipse + JDK1.8.0 Ubuntu14.04:Hadoop2.9.0 二.准备 ...
- 第一个MapReduce程序——WordCount
通常我们在学习一门语言的时候,写的第一个程序就是Hello World.而在学习Hadoop时,我们要写的第一个程序就是词频统计WordCount程序. 一.MapReduce简介 1.1 MapRe ...
- 从零开始学习Hadoop--第2章 第一个MapReduce程序
1.Hadoop从头说 1.1 Google是一家做搜索的公司 做搜索是技术难度很高的活.首先要存储很多的数据,要把全球的大部分网页都抓下来,可想而知存储量有多大.然后,要能快速检索网页,用户输入几个 ...
- hadoop下跑mapreduce程序报错
mapreduce真的是门学问,遇到的问题逼着我把它从MRv1摸索到MRv2,从年前就牵挂在心里,连过年回家的旅途上都是心情凝重,今天终于在eclipse控制台看到了job completed suc ...
- 使用Python实现Hadoop MapReduce程序
转自:使用Python实现Hadoop MapReduce程序 英文原文:Writing an Hadoop MapReduce Program in Python 根据上面两篇文章,下面是我在自己的 ...
随机推荐
- 在centos7下安装svn
SVN的安装 yum install subversion 服务端命令 1. svnserver - 控制svn系统服务的启动等 2. svnadmin - 版本库的创建/导出/导入/删除等 3. s ...
- POJ:Dungeon Master(三维bfs模板题)
Dungeon Master Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 16748 Accepted: 6522 D ...
- loadrunner获取接口返回参数(包括body,headers等)
Action() { web_set_max_html_param_len("); // 默认最大长度为256 web_reg_save_param("ResponseBody&q ...
- .net MVC 下拉多级联动及编辑
多级联动实现,附源码.当前,部分代码是参与博客园其它网友. 新增,前台代码: <script src="~/Scripts/jquery-1.10.2.js">< ...
- Canvas标签基础
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 分页Bootstrap实现
<%@ include file="/init.jsp" %> <script type="text/javascript" src=&quo ...
- 20155239 2016-2017-2 《Java程序设计》第5周学习总结
教材内容学习 第八章 JAVA异常架构 Java异常是Java提供的一种识别及响应错误的一致性机制. Java异常机制可以使程序中异常处理代码和正常业务代码分离,保证程序代码更加优雅,并提高程序健壮性 ...
- mybatis打印sql日志配置
<settings> <!-- 打印查询语句 --> <setting name="logImpl" value="STDOUT_LOGGI ...
- Python:slice与indices
slice: eg: >>>e=[0,1,2,3,4,5,6] >>>s=slice(2,3) >>>e[s] [2] slice的区间左闭右开[ ...
- linux常用命令:vmstat 命令
vmstat 是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存.进程.CPU活动进行监控.他是对系统的整体 情况进行统计,不足之处是无法对某个进程进 ...