hadoop3.0.0测验
下载地址:
hadoop: http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-3.0.0/
准备工作:
1.master节点与其他节点需要建立免密登录,这个很简单,两句话搞定:
ssh-keygen
ssh-copy-id 10.1.4.58
2.安装jdk
3.配置/etc/hosts(如果配置为ip ip将会导致datanode无法识别master,下面会讲)
4.关闭防火墙
新建用户
useradd sri_udap
passwd sri_udap
输入密码
方便起见,全部采用root用户操作,新建用户只是独立出目录,后续如果需要权限管理则重新赋权
解压hadoop-3.0.0.tar.gz
tar -zxvf hadoop-3.0.0.tar.gz
加入环境变量
vi /etc/profile
添加如下内容:
export HADOOP_HOME=/home/sri_udap/app/hadoop-3.0.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
修改配置文件:
cd /home/sri_udap/app/hadoop-3.0.0/etc/hadoop/
vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_121
vi core-site.xml
core-site.xml
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://10.1.4.57:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/sri_udap/app/hadoop-3.0.0/temp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- 设置namenode的http通讯地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!-- 设置secondarynamenode的http通讯地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:50090</value>
</property>
<!-- 设置namenode存放的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/soft/hadoop-2.7.2/name</value>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 设置datanode存放的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/soft/hadoop-2.7.2/data</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- 设置 resourcemanager 在哪个节点-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property> <!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
新建worker文件:
vi workers
添加如下:
10.1.4.58
10.1.4.59
将整个包拷贝到其他两台主机的相同位置
格式化:(格式化一次就好,多次格式化可能导致datanode无法识别,如果想要多次格式化,需要先删除数据再格式化)
./bin/hdfs namenode -format
启动
[root@10 sbin]# ./start-dfs.sh
报错:
Starting namenodes on [10.1.4.57]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [10.1.4.57]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
把缺少的环境变量加上:hadoop-env.sh
export HDFS_DATANODE_SECURE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
再启动:
又报错:
Starting namenodes on [10.1.4.57]
上一次登录:二 12月 26 15:06:36 CST 2017pts/2 上
Starting datanodes
10.1.4.58: ERROR: Cannot set priority of datanode process 5752
10.1.4.59: ERROR: Cannot set priority of datanode process 9788
Starting secondary namenodes [10.1.4.58]
上一次登录:二 12月 26 15:10:16 CST 2017pts/2 上
10.1.4.58: secondarynamenode is running as process 5304. Stop it first.
这个问题,查阅了各个方面的文档始终无法解决,不知道会不会跟hostname的写法有关系,我的/etc/hosts配置方法是,这种写法在hadoopdatanode节点启动是无法识别到master_ip的,这个问题在后面尝试中改掉了,最后会导致集群没有可用datanode,要避免这样写
10.1.4.57 10.1.4.57
10.1.4.58 10.1.4.58
10.1.4.59 10.1.4.59
尝试失败..不过据说这个问题在2.*版本中是没有出现的,所以回退一下版本
退到2.7.2,把配置拷贝过去,并在配置目录下 etc/hadoop添加两个文件
vi masters
内容:
10.1.4.57
vi slaves
内容:
10.1.4.58
10.1.4.59
启动
[root@10 sbin]# ./start-dfs.sh
Starting namenodes on [10.1.4.57]
10.1.4.57: starting namenode, logging to /home/sri_udap/app/hadoop-2.7.2/logs/hadoop-root-namenode-10.1.4.57.out
10.1.4.59: starting datanode, logging to /home/sri_udap/app/hadoop-2.7.2/logs/hadoop-root-datanode-10.1.4.59.out
10.1.4.58: starting datanode, logging to /home/sri_udap/app/hadoop-2.7.2/logs/hadoop-root-datanode-10.1.4.58.out
Starting secondary namenodes [10.1.4.57]
10.1.4.57: starting secondarynamenode, logging to /home/sri_udap/app/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-10.1.4.57.out
[root@10 sbin]# ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/sri_udap/app/hadoop-2.7.2/logs/yarn-root-resourcemanager-10.1.4.57.out
10.1.4.59: starting nodemanager, logging to /home/sri_udap/app/hadoop-2.7.2/logs/yarn-root-nodemanager-10.1.4.59.out
10.1.4.58: starting nodemanager, logging to /home/sri_udap/app/hadoop-2.7.2/logs/yarn-root-nodemanager-10.1.4.58.out
登录http://10.1.4.57:50070 查看hadoop作业情况
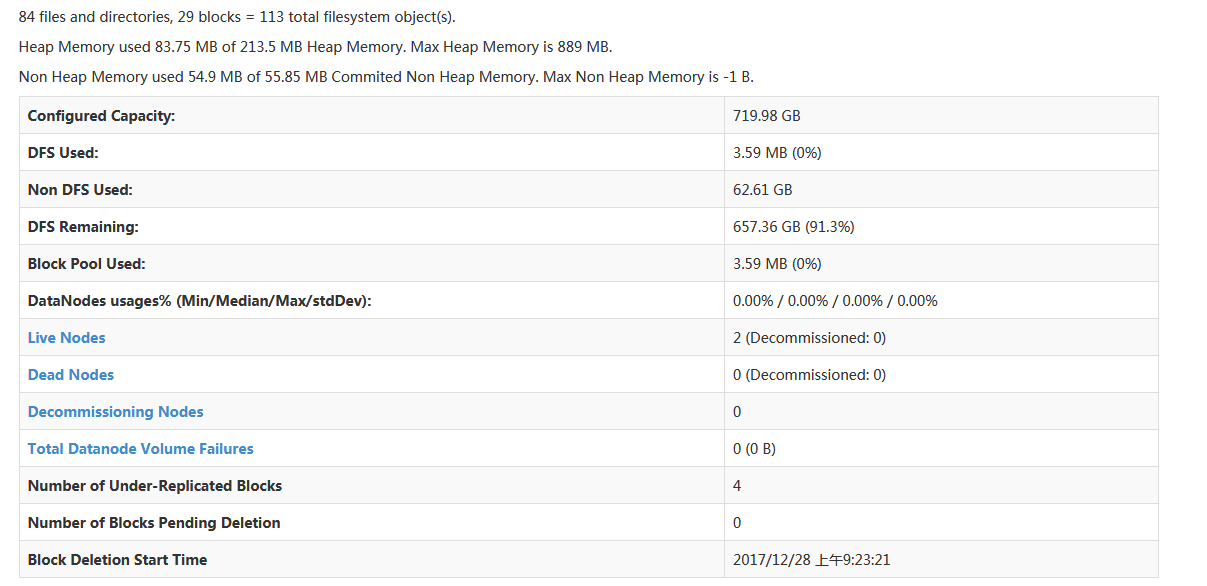
查看yarn 10.1.4.57:8088
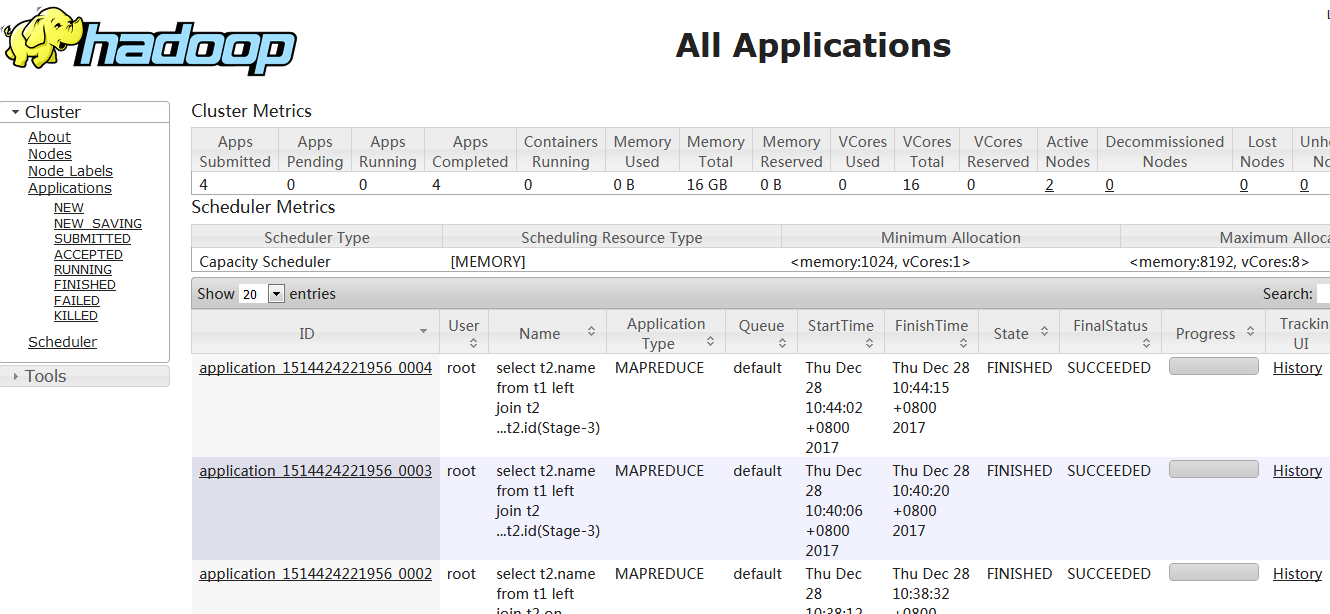
测验:
测验可以等到安装hive后一起,因为复杂的hive语句将会产生MapReduce作业在hdfs
hdfs dfs -mkdir /input
hdfs dfs -put 1.txt /input
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /input /output
这样就产生了一个作业,其中1.txt是随便写的一个文件,我们运行一个单词计数作业
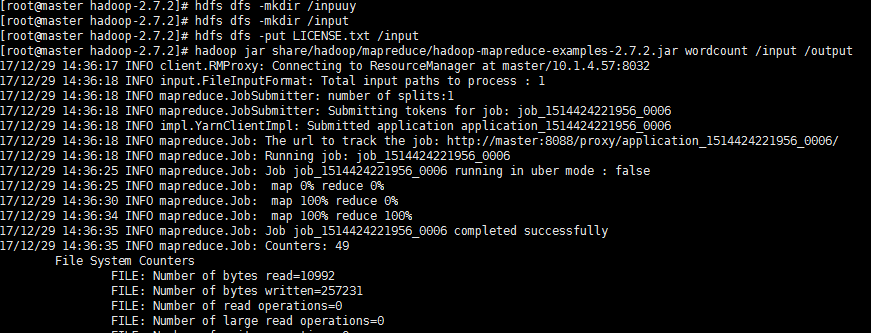
hadoop3.0.0测验的更多相关文章
- Hadoop3.2.0使用详解
1.概述 Hadoop3已经发布很久了,迭代集成的一些新特性也是很有用的.截止本篇博客书写为止,Hadoop发布了3.2.0.接下来,笔者就为大家分享一下在使用Hadoop3中遇到到一些问题,以及解决 ...
- Hadoop3.2.0集群(4节点-无HA)
1.准备环境 1.1配置dns # cat /etc/hosts 172.27.133.60 hadoop-01 172.27.133.61 hadoop-02 172.27.133.62 hadoo ...
- Win10 下 hadoop3.0.0 单机部署
前言 因近期要做 hadoop 有关的项目,需配置 hadoop 环境,简单起见就准备进行单机部署,方便开发调试.顺便记录下采坑步骤,方便碰到同样问题的朋友们. 安装步骤 一.下载 hadoop-XX ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- hadoop3.1.0 HDFS快速搭建伪分布式环境
1.环境准备 CenntOS7环境 JDK1.8-并配置好环境变量 下载Hadoop3.1.0二进制包到用户目录下 2.安装Hadoop 1.解压移动 #1.解压tar.gz tar -zxvf ha ...
- hadoop3.1.0 window win7 基础环境搭建
https://blog.csdn.net/wsh596823919/article/details/80774805 hadoop3.1.0 window win7 基础环境搭建 前言:在windo ...
- 超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群
超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群 ps:本文的步骤已自实现过一遍,在正文部分避开了旧版教程在新版使用导致出错的内容,因此版本一致的情况下照搬执行基本不会有大错误. ...
- hadoop-3.0.0 配置中的 yarn.nodemanager.aux-services 项
在hadoop-3.0.0-alpha4 的配置中,yarn.nodemanager.aux-services项的默认值是“mapreduce.shuffle”,但如果在hadoop-2.2 中继续使 ...
- 【hadoop】hadoop3.2.0应用环境搭建与使用指南
下面列出我搭建hadoop应用环境的文章整理在一起,不定期更新,供大家参考,互相学习!!! 杂谈篇: [英语学习]Re-pick up English for learning big data (n ...
随机推荐
- spring 下载
Spring官网(https://spring.io/)改版后,直接下载Jar包的链接,下面汇总 1.直接输入地址,改相应版本即可:http://repo.springsource.org/libs- ...
- Android开发:setAlpha()方法和常用RGB颜色表----颜色, r g b分量数值(int), 16进制表示 一一对应
杂家前文Android颜色对照表只有颜色和十六进制,有时候需要设置r g b分量的int值,如paint.setARGB(255, 127, 255, 212);就需要自己计算下分量的各个值.这里提供 ...
- 浅谈Mysql 表设计规范(转)
本文首先探讨下数据库设计的三大范式,因为范式只是给出了数据库设计的原则,并没有告诉我们实际操作中应该怎样操作,应该注意什么,所以我们还会谈下实际工作中需要注意的具体操作问题. 三大范式 首先放出三大范 ...
- unity, 在材质上指定render queue
材质球inspector面板在debug模式下可以看到Custom Render Queue一项: 其默认值为-1,表示使用相应shader的render queue设置. 也可以人为将其改为其它值, ...
- Spark学习笔记之-Spark远程调试
Spark远程调试 本例子介绍简单介绍spark一种远程调试方法,使用的IDE是IntelliJ IDEA. 1.了解jvm一些参数属性 -X ...
- 在Android Studio 和 Eclipse 的 git 插件操作 "代码提交"以及"代码冲突"
面向对象:曾经使用过SVN的同学. (因为Git 它 可以说是双重的SVN (本地一个服务器,远程一个服务器)),提交代码要有两次步骤,先提交到本地服务器,再把本地服务器在提交到远程服务器. 所以连S ...
- ios--网页js调用oc代码+传递参数+避免中文参数乱码的解决方案(实例)
此解决方案原理: 1.在ViewController.h中声明方法和成员变量,以及webView的委托: // // ViewController.h // JS_IOS_01 // // Cr ...
- iOS7隐藏状态栏 status Bar
转自:http://blog.csdn.net/dqjyong/article/details/17896145 IOS7中,不仅应用的风格有一定的变化,状态栏变化比较大,我们可以看到UIVIEWCO ...
- 【Acm】算法之美—Fire Net
题目概述:Fire Net Suppose that we have a square city with straight streets. A map of a city is a square ...
- ubuntu+nginx+laravel
1, 到http://v4.golaravel.com/docs/4.2/installation 点击下载最新版Laravel框架.然后解压 2,把laravel-master下的文件夹拷入到php ...