大数据Hadoop平台安装及Linux操作系统环境配置
配置 Linux 系统基础环境
查看服务器的IP地址

设置服务器的主机名称
hostnamectl set-hostname hadoop
hostname可查看
绑定主机名与IP 地址
vim /etc/hosts
写入:
ip hadoop #自己虚拟机ip和主机名
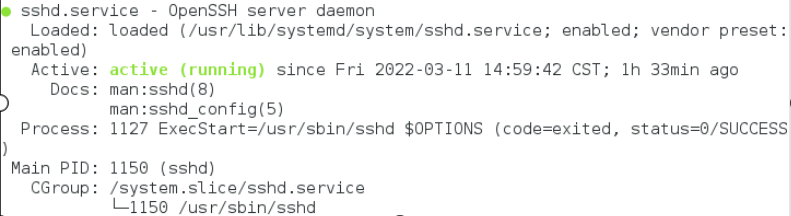
查看SSH 服务状态
- SSH 为 Secure Shell 的缩写,是专为远程登录会话和其他网络服务提供安
全性的协议。一般的用法是在本地计算机安装SSH客服端,在服务器端安装SSH
服务,然后本地计算机利用 SSH 协议远程登录服务器,对服务器进行管理。这
样可以非常方便地对多台服务器进行管理。同时在 Hadoop分布式环境下,集群
中的各个节点之间(节点可以看作是一台主机)需要使用SSH协议进行通信。因
此Linux系统必须安装并启用SSH服务。
命令:systemctl status sshd
关闭防火墙
- Hadoop可以使用Web页面进行管理,但需要关闭防火墙,否则打不开Web页
面。同时不关闭防火墙也会造成 Hadoop 后台运行脚本出现莫名其妙的错误。
关闭命令如下:

查看状态为:

- 看到inactive (dead)就表示防火墙已经关闭。不过这样设置后,Linux系
统如果重启,防火墙仍然会重新启动。执行如下命令可以永久关闭防火墙。

创建hadoop 用户

安装JAVA 环境
下载JDK 安装包
- JDK 安 装 包 需 要 在 Oracle 官 网 下 载 , 下 载 地 址 为 :
https://www.oracle.com/java /technologies /javase-jdk8-downloads.html,本教材采用的Hadoop 2.7.1所需要的JDK版本为JDK7以上,这里采用的安装包为jdk-8u152-linux-x64.tar.gz
卸载自带OpenJDK
删除相关文件,键入命令
rpm -e --nodeps 安装包名称
查看删除结果再次键入命令 java -version 出现以下结果表示删除成功

安装JDK
Hadoop 2.7.1 要求 JDK 的版本为 1.7 以上,这里安装的是 JDK1.8 版(即
JAVA 8)。
安装命令如下,将安装包解压到/usr/local/src目录下:
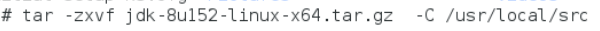
解压完成后,查看目录确认一下。可以看出 JDK 安在/usr/local/src/jdk1.8.0_152目录中。

设置 JAVA 环境变量
在Linux中设置环境变量的方法比较多,较常见的有两种:一是配置/etc/profile文件,配置结果对整个系统有效,系统所有用户都可以使用;二是配置~/bashrc文件,配置结果仅对当前用户有效。这里使用第一种方法。
在文件的最后增加如下两行:
进入vim /etc/profile,在文件结尾添加
# JAVA_HOME指向JAVA安装目录
执行source使设置生效:

- 检查JAVA是否可用
source /etc/profile
echo $JAVA_HOME
- 说明JAVA_HOME已指向JAVA安装目录。能够正常显示Java版本则说明JDK安装并配置成功。
安装Hadoop 软件
获取Hadoop 安装包
- Apache Hadoop 各 个 版 本 的 下 载 网 址 :
https://archive.apache.org/dist/hadoop /common/。本教材选用的事Hadoop2.7.1版本,安装包为hadoop-2.7.1.tar.gz。需要先下载Hadoop安装包,再上传到Linux系统的/opt/software目录。具体的方法见前一节“实验一 Linux操作系统环境设置”,这里就不再赘述。
安装Hadoop 软件
安装命令如下,将安装包解压到/usr/local/src/目录下:

- 解压完成后,查看目录确认一下。可以看出 Hadoop 安装在/usr/local/src/hadoop -2.7.1目录中

- 查看Hadoop目录,得知Hadoop目录内容如下:

- 其中:
bin:此目录中存放Hadoop、HDFS、YARN和MapReduce运行程序和管理软件。
etc:存放Hadoop配置文件。
include: 类似C语言的头文件
lib:本地库文件,支持对数据进行压缩和解压。
libexe:同lib
sbin:Hadoop集群启动、停止命令
share:说明文档、案例和依赖jar包。
配置 Hadoop 环境变量
和设置JAVA环境变量类似,修改/etc/profile文件。
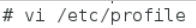
在文件的最后增加如下两行:
HADOOP_HOME指向 JAVA安装目录

执行source使用设置生效:

检查设置是否生效:

出现上述Hadoop帮助信息就说明Hadoop已经安装好了。
修改目录所有者和所有者组
上述安装完成的 Hadoop 软件只能让 root 用户使用,要让 hadoop 用户能够运行Hadoop软件,需要将目录/usr/local/src的所有者改为hadoop用户。

/usr/local/src目录的所有者已经改为hadoop了
安装单机版 Hadoop 系统
配置 Hadoop 配置文件
进入Hadoop目录

配置hadoop-env.sh文件,目的是告诉Hadoop系统JDK的安装目录

在文件中查找export JAVA_HOME这行,将其改为如下所示内容

这样就设置好Hadoop的本地模式,下面使用官方案例来测试Hadoop是否运
行正常。
测试 Hadoop 本地模式的运行
切换到hadoop 用户
- 使用hadoop这个用户来运行Hadoop软件

创建输入数据存放目录
- 将输入数据存放在~/input目录(hadoop用户主目录下的input目录中)

创建数据输入文件
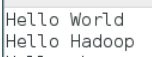
- 创建数据文件data.txt,将要测试的数据内容输入到data.txt文件中

- 输入如下内容,保存退出:
测试 MapReduce 运行
运行 WordCount 官方案例,统计 data.txt 文件中单词的出现频度。这个案例可以用来统计年度十大热销产品、年度风云人物、年度最热名词等。命令如下:

- 运行结果保存在~/output目录中,命令执行后查看结果:

- 文件_SUCCESS表示处理成功,处理的结果存放在part-r-00000文件中,查看该文件。

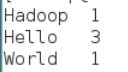
可以看出统计结果正确,说明 Hadoop 本地模式运行正常。读者可将这个运行结果与“3.2.3 MapReduce”中的WordCount案例运行过程进行对照,来加深对MapReduce框架的理解。
注意:输出目录不能事先创建,如果已经有 ~/output 目录,就要选择另外的输出目录,或者将 ~/output 目录先删除。删除命令如下所示。
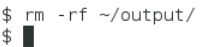
大数据Hadoop平台安装及Linux操作系统环境配置的更多相关文章
- OpenStack-Ocata版+CentOS7.6 云平台环境搭建 — 1.操作系统环境配置
1.OpenStack示例的架构介绍 1.1 各节点介绍 (1)控制节点(controller)控制节点(controller)上运行身份服务,镜像服务,计算节点管理,网络管理,各种网络代理和仪表板. ...
- 大数据Hadoop入门教程 | (二)Linux
使用finalShell可以提供文件目录图形化 完整Linux命令整理参考大佬博客:Linux常见文件管理命令 - Mr_Walker - 博客园 Linux文件系统基础知识 Linux文件系统概念 ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
- 14周事情总结-机器人-大数据hadoop
14周随着考试的进行,其他该准备的事情也在并行的处理着,考试内容这里不赘述了 首先说下,关于机器人大赛的事情,受益颇多,机器人的制作需要机械和电控两方面 昨天参与舵机的测试,遇到的问题:舵机不动 排查 ...
- 大数据计算平台Spark内核全面解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着Spark在大数据计算领域的暂露头角,越来越多的 ...
随机推荐
- SAP 实例 6 HTML input
REPORT demo_html_input. CLASS demo DEFINITION. PUBLIC SECTION. CLASS-METHODS main. PRIVATE SECTION. ...
- rhel安装vmtools
第一步,vmware登录虚拟机,菜单栏找到"虚拟机"--"安装TOOLS" //如果打开虚拟机的光驱后没有文件.那么重复以上操作. 第二步,拷贝压缩文件到桌面: ...
- NC50038 kotori和糖果
NC50038 kotori和糖果 题目 题目描述 kotori共有 \(n\) 块糖果,每块糖果的初始状态是分散的,她想把这些糖果聚在一堆.但她每次只能把两堆糖果合并成一堆. 已知把两堆数量为 \( ...
- 卸载office密钥
一.管理员身份运行命令提示行: 二.命令提示行上输入: cd C:\Program Files\Microsoft Office\Office16 弹出如下内容: C:\Program Files\M ...
- 基于 Hexo 从零开始搭建个人博客(二)
阅读本篇前,请先配置好相应的环境,请仔细阅读教程 基于 Hexo 从零开始搭建个人博客(一). 原文链接:基于 Hexo 从零开始搭建个人博客(二) 前言 博客搭建过程遇到任何问题,优先在本页面搜索, ...
- vue3代码编写
vue3代码编写 团队内的vue3已经升级一年,在这一年中vue也在不停的更新,为了最大化组合式api带来的优势,便需要合理规范代码的编写方式- 1.从vue2到vue3 vue2组件采用配置式API ...
- 5-21 拦截器 Interceptor
Spring MVC拦截器 什么是拦截器 拦截器是SpringMvc框架提供的功能 它可以在控制器方法运行之前或运行之后(还有其它特殊时机)对请求进行处理或加工的特定接口 常见面试题:过滤器和拦截器的 ...
- Python 封装SNMP调用接口
PySNMP 是一个纯粹用Python实现的SNMP,用PySNMP的最抽象的API为One-line Applications,其中有两类API:同步的和非同步的,都在模块pysnmp.entity ...
- 9.2 DAG上的动态规划
在有向无环图上的动态规划是学习动态规划的基础,很多问题都可以转化为DAG上的最长路,最短路或路径计数问题 9.2.1 DAG模型 嵌套矩形问题: 矩形之间的可嵌套关系是一种典型的二元关系,二元关系可以 ...
- Dubbo源码(三) - 服务导出(生产者)
前言 本文基于Dubbo2.6.x版本,中文注释版源码已上传github:xiaoguyu/dubbo 在了解了Dubbo SPI后,我们来了解下Dubbo服务导出的过程. Dubbo的配置是通过Du ...