kafka生产者网络层总结
1 层次结构
负责进行网络IO请求的是NetworkClient,主要层次结构如下
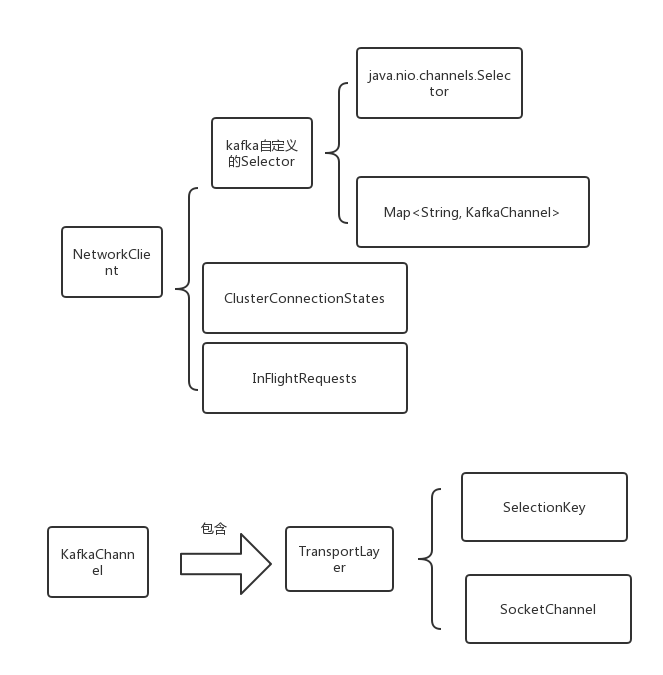
ClusterConnectionStates报存了每个节点的状态,以node为key,以node的状态为value;inFlightRequets中保存了每个节点已经发送的请求,但是还没有返回的请求,以node为key,以List<ClientRequest>为value。inFlightRequets从名字也可以看出,表示“正在空中飞”的请求。
2 如何保证每次只发送一个请求
sender线程启动后,如果RecordBatch中有消息,会将消息按照所在节点重新排列,每个节点会创建一个ClientRequest,用来发送,每个节点每次只能发送一个ClientRequest,如下
KafkaChannel#setSend(..)
public void setSend(Send send) {
if (this.send != null) // 如果已经有send,会抛出异常
throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress.");
this.send = send;
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}
那么kafka是如何保证避免setSend的时候KafkaChannel中已经没有send了呢,这个关键就是在sender线程中会调用NetworkClient#ready(..),会将没有ready的节点去除掉,从而不会在该节点上setSend:
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) { // 关键
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.connectionDelay(node, now));
}
}
3 NetworkClient#ready(..)
NetworkClient#ready(..)检查节点是否准备好,从而决定是否可以将消息封装成ClientRequest放到KafkaChannel上。
public boolean ready(Node node, long now) {
if (node.isEmpty())
throw new IllegalArgumentException("Cannot connect to empty node " + node);
if (isReady(node, now)) // 关键
return true;
if (connectionStates.canConnect(node.idString(), now))
initiateConnect(node, now);
return false;
}
我们来分析下isReady
public boolean isReady(Node node, long now) {
return !metadataUpdater.isUpdateDue(now) && canSendRequest(node.idString());
}
isReady主要两个条件,一个是判断metadata是否到了更新的时候了,如果metadata需要更新,那么就不发送本次请求,也就是metadata更新优先级高。第二个是判断这个节点是否canSendRequest。
private boolean canSendRequest(String node) {
return connectionStates.isConnected(node) && selector.isChannelReady(node)
&& inFlightRequests.canSendMore(node); // 重点
}
inFlightRequests保存的是“正在空中飞”的请求
public boolean canSendMore(String node) {
Deque<ClientRequest> queue = requests.get(node);
return queue == null || queue.isEmpty() ||
(queue.peekFirst().request().completed() && queue.size() < this.maxInFlightRequestsPerConnection);
}
满足以下几个条件,表示可以继续send
- queue是空,即该节点没有“正在空中飞”的request
- queue不为空。queue中排在最开头的request已经completed 并且queue的大小小于允许的最大值。如何理解呢?queue是一个双端队列,每次add的时候都会在queue的头部插入,所以queue中第一个就是正在发送的,同样也是KafkaChannel中的send。只有当send发送到网络中的时候才可以继续发送。这就保证了前面说的“如何保证每次只发送一个请求”。
4 inFlightRequests
inFlightRequests保存了"正在空中飞"的请求,所谓“正在空中飞”的意思就是request已经发送到了网络上,但是服务端还没有回ack。NetworkClient#doSend会往inFlightRequests头部放置一个request,同时会在KafkaChannel中放置一个request.send。
public void add(ClientRequest request) {
Deque<ClientRequest> reqs = this.requests.get(request.request().destination());
if (reqs == null) {
reqs = new ArrayDeque<>();
this.requests.put(request.request().destination(), reqs);
}
reqs.addFirst(request); // 重点,插入到头部
}
5 Selector#pollSelectionKeys
Selector#pollSelectionKeys用来处理读写事件。先看写事件
if (channel.ready() && key.isWritable()) {
Send send = channel.write();
if (send != null) {
this.completedSends.add(send); // 请求写完了会放到completedSends中
this.sensors.recordBytesSent(channel.id(), send.size());
}
}
往网络中写的时候,会调用KafkaChannel#write来写。
public Send write() throws IOException {
Send result = null;
if (send != null && send(send)) {
result = send;
send = null; // kafkaChannel中的send被置为null,这时候新的request可以发送了
}
return result;
}
private boolean send(Send send) throws IOException {
send.writeTo(transportLayer);
if (send.completed())
transportLayer.removeInterestOps(SelectionKey.OP_WRITE);
return send.completed();
}
发送可能一次不能完全发送完毕,需要发送好几次才能将request全部发送到网络上,只有这个request发送完毕了才能将KafkaChannel中的send置为null,新的request才可以setSend。但此时inFlightRequests并没有移除该request,也就是说该request还在"飞",但是新的request可以添加。发送完毕后会将channel的SelectionKey.OP_WRITE移除,没有发送完毕不会移除,下次轮询的时候该节点没有ready,不会添加新的request,会继续发送没有发完的request。
对于ack=0,不要求服务端ack就表示发送成功。该处理是在NetworkClient#handleCompletedSends(..)中进行的
private void handleCompletedSends(List<ClientResponse> responses, long now) {
// if no response is expected then when the send is completed, return it
for (Send send : this.selector.completedSends()) {
ClientRequest request = this.inFlightRequests.lastSent(send.destination());
if (!request.expectResponse()) { // ack = 0不需要服务端response
this.inFlightRequests.completeLastSent(send.destination()); // request从inFlightRequests中移除,表示此次请求完毕
responses.add(new ClientResponse(request, now, false, null));
}
}
}
对于ack !=0 ,则要求服务端ack才表示发送成功,该处理是在
NetworkClient#handleCompletedReceives(..)中进行
private void handleCompletedReceives(List<ClientResponse> responses, long now) {
for (NetworkReceive receive : this.selector.completedReceives()) {
String source = receive.source();
ClientRequest req = inFlightRequests.completeNext(source);
Struct body = parseResponse(receive.payload(), req.request().header());
if (!metadataUpdater.maybeHandleCompletedReceive(req, now, body))
responses.add(new ClientResponse(req, now, false, body));
}
}
5 参考
https://blog.csdn.net/chunlongyu/article/details/52651960
kafka生产者网络层总结的更多相关文章
- 【转】 详解Kafka生产者Producer配置
粘贴一下这个配置,与我自己的程序做对比,看看能不能完善我的异步带代码: ----------------------------------------- 详解Kafka生产者Produce ...
- Kafka生产者-向Kafka中写入数据
(1)生产者概览 (1)不同的应用场景对消息有不同的需求,即是否允许消息丢失.重复.延迟以及吞吐量的要求.不同场景对Kafka生产者的API使用和配置会有直接的影响. 例子1:信用卡事务处理系统,不允 ...
- Python 使用python-kafka类库开发kafka生产者&消费者&客户端
使用python-kafka类库开发kafka生产者&消费者&客户端 By: 授客 QQ:1033553122 1.测试环境 python 3.4 zookeeper- ...
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- [Spark][kafka]kafka 生产者,消费者 互动例子
[Spark][kafka]kafka 生产者,消费者 互动例子 # pwd/usr/local/kafka_2.11-0.10.0.1/bin 创建topic:# ./kafka-topics.sh ...
- Kafka权威指南 读书笔记之(三)Kafka 生产者一一向 Kafka 写入数据
不管是把 Kafka 作为消息队列.消息总线还是数据存储平台来使用 ,总是需要有一个可以往 Kafka 写入数据的生产者和一个从 Kafka 读取数据的消费者,或者一个兼具两种角色的应用程序. 开发者 ...
- kafka生产者
1.kafka生产者是线程安全的,她允许多个线程共享一个kafka实例 2.kafka管理一个简单的后台线程,所有的IO操作以及与每个broker的tcp连接通信,如果没有正确的关闭生产者可能会造成资 ...
- java实现Kafka生产者示例
使用java实现Kafka的生产者 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 3 ...
- kafka生产者和消费者流程
前言 根据源码分析kafka java客户端的生产者和消费者的流程. 基于zookeeper的旧消费者 kafka消费者从消费数据到关闭经历的流程. 由于3个核心线程 基于zookeeper的连接器监 ...
随机推荐
- can_has_stdio?
得到一个用±<>这样符号组成的五角星,结合题目stdio,估计是c语言编译后的文件 查到BrianFuck语言,找个在线编译器或者找到编译码(c++)得到flag 在线编译网站 brain ...
- 16进制转字符串得到flag
工业协议分析2 666c61677b37466f4d3253746b6865507a7d
- over the Wall
最近风头很紧,先上两个可用的谷歌镜像给各位应急. https://kfd.me/ http://gufenso.coderschool.cn/ https://github.com/gfw-break ...
- python os.system 和popen
1.python os.system 和popen 其中第一个只会返回0或者1,另外一个会返回执行结果 每天生成一个文件,并把磁盘的使用情况写到到这个文件中,文件名为日期格式(yyyy-mm-dd ...
- JZ-062-二叉查找树的第 K 个结点
二叉查找树的第 K 个结点 题目描述 给定一棵二叉搜索树,请找出其中的第k小的结点. 题目链接: 二叉查找树的第 K 个结点 代码 /** * 标题:二叉查找树的第 K 个结点 * 题目描述 * 给定 ...
- [2022-2-26] OICLASS-USACO提高组模拟赛 C·Convoluted Intervals S
这道题非常简单啊,我看很多人都做出来了,张林昨天也讲的很明白了,那我来简单写一下: 暴力思路(10pts) 我们发现,我们只需要模拟画出一个图然后进行暴力枚举就行了. 差分+桶+加乘原理思路(100p ...
- Dapr 弹性的策略
云原生应用需要处理 云中很容易出现瞬时故障.原因在以下文档 暂时性故障处理[1] 中有具体说明. 任何环境.任何平台或操作系统以及任何类型的应用程序都会发生暂时性故障. 在本地基础结构上运行的解决方案 ...
- Laravel常用工具类
工具类函数 Geom转成字符串 如果项目中有大量的计算经纬度需求,强烈建议使用PgSql的geometry类型 public static function formatGeomToStr($geom ...
- pandas常用操作详解——数据运算(一)
表与表之间的数据运算 #构建数据集df1=pd.DataFrame(np.random.random(32).reshape(8,4),columns=list('ABCD')) df2=pd.Dat ...
- knative入门指南
尽管Knative自2018年以来一直由社区维护,但最近一直有关于该项目的传言,因为谷歌最近将Knative提交给了云原生计算基金会(CNCF),作为一个孵化项目考虑. 太酷了!但Knative到底是 ...