4 zookeeper集群和基本命令
4 zookeeper集群和基本命令
集群思路:先搞定一台服务器,再克隆出两台,形成集群!
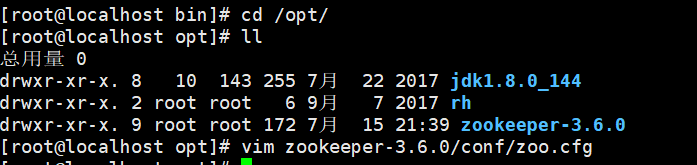
1 安装zookeeper
我们的zookeeper是安装在/opt目录下
2 配置服务器编号
- 在/opt/zookeeper/zkData创建myid文件
vim myid
- 在文件中添加与server对应的编号:1
- 其余两台服务器分别对应2和3
3 配置zoo.cfg文件
- 打开zoo.cfg文件,增加如下配置
#######################cluster##########################
server.1=192.168.204.141:2888:3888
server.2=192.168.204.142:2888:3888
server.3=192.168.204.143:2888:3888
配置参数解读 server.A=B:C:D- A:一个数字,表示第几号服务器
集群模式下配置的/opt/zookeeper/zkData/myid文件里面的数据就是A的值 - B:服务器的ip地址
- C:与集群中Leader服务器交换信息的端口
- D:选举时专用端口,万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选
出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
- A:一个数字,表示第几号服务器
4 配置其余两台服务器
找到虚拟机安装的位置进入

在虚拟机数据目录vms下,创建zk02

将本台服务器数据目录下的.vmx文件和所有的.vmdk文件分别拷贝zk02下
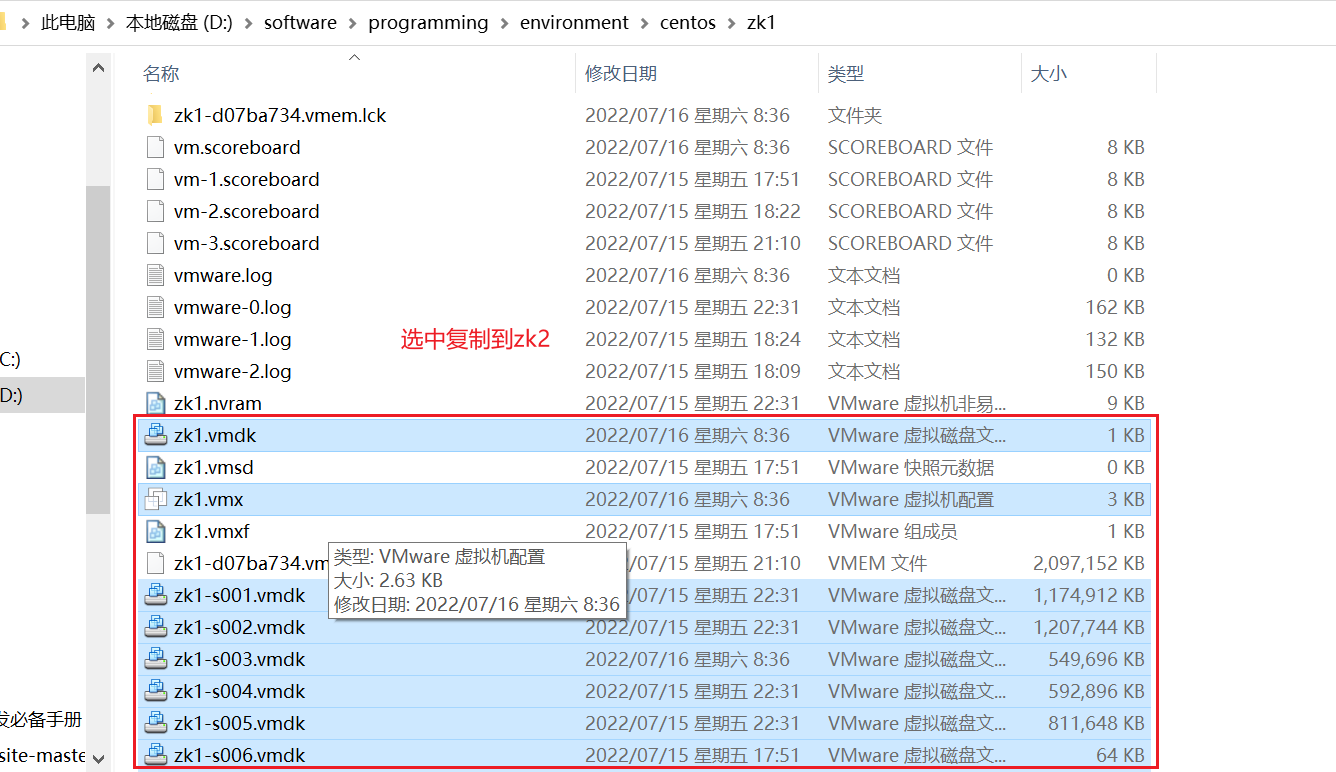
虚拟机->文件->打开 (选择zk02下的.vmx文件)
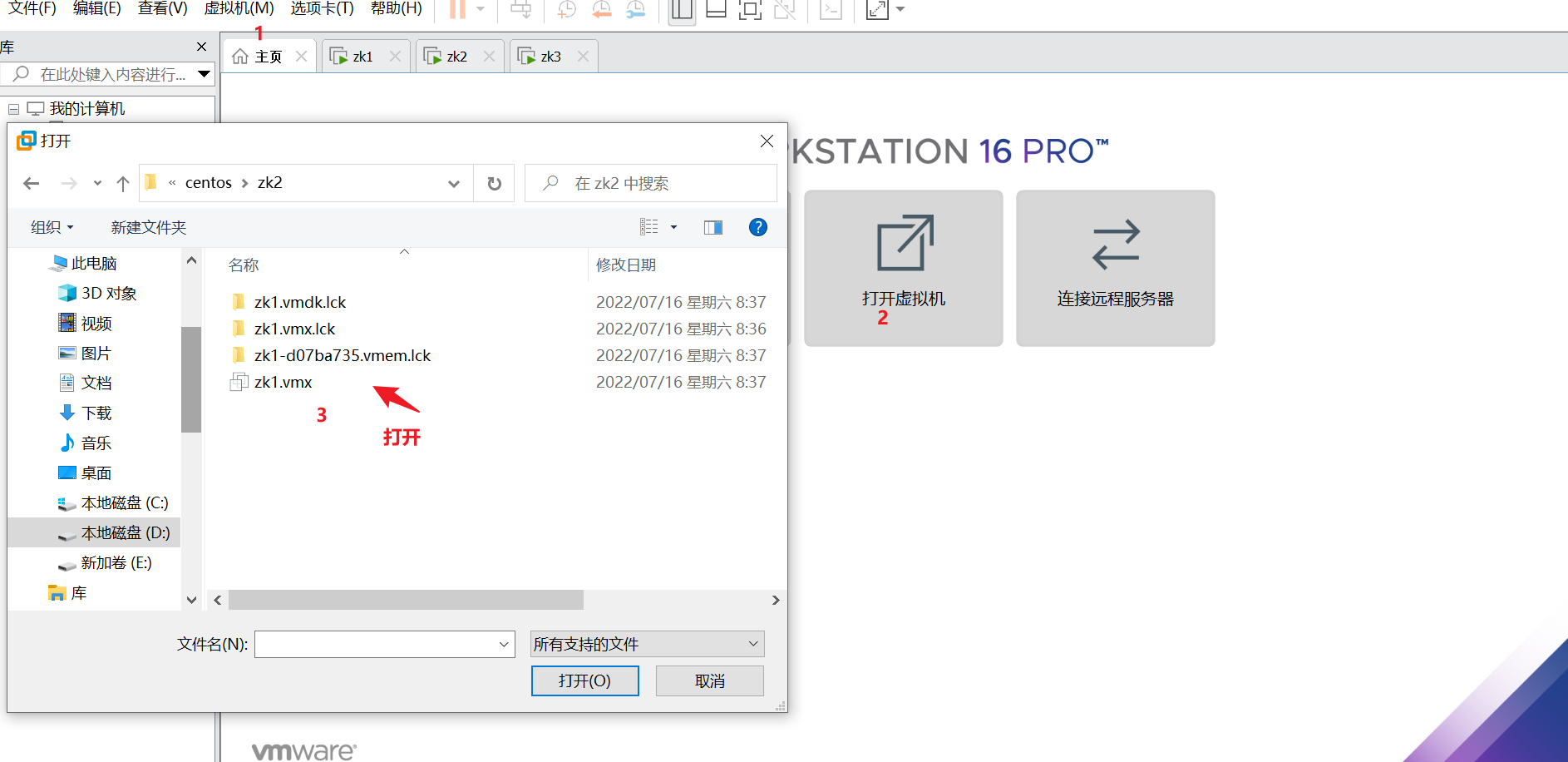
开启此虚拟机,弹出对话框,选择“我已复制该虚拟机”
进入系统后,查看ip,修改/opt/zookeeper/zkData/myid中的数值为2
还需要注意目录中集群的ip哦是否一致
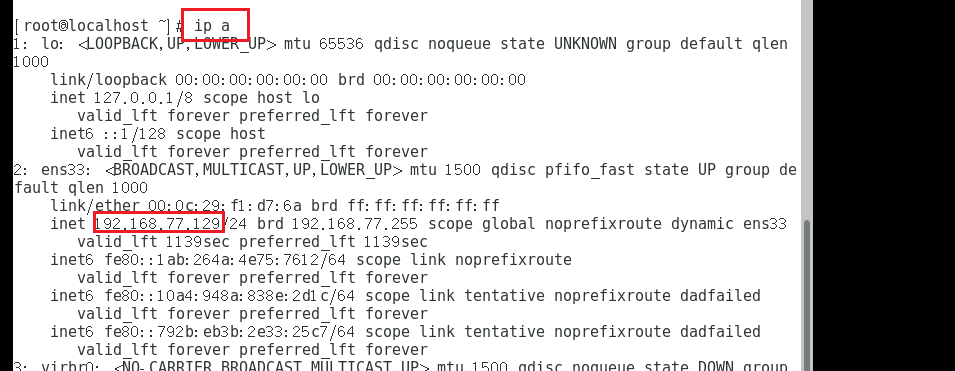
第三台服务器zk03,重复上面的步骤
5 集群操作
每台服务器的防火墙必须关闭
systemctl stop firewalld.service # 关闭集群
systemctl status firewalld.service #查看状态
启动第1台
需要进入到zookeeper的bin 目录
[root@localhost bin]# ./zkServer.sh start
- 查看状态
[root@localhost bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Error contacting service. It is probably not running.
注意:因为没有超过半数以上的服务器,所以集群失败 (防火墙没有关闭也会导致失败)
- 当启动第2台服务器时
- 查看第1台的状态:Mode: follower
- 查看第2台的状态:Mode: leader
6 客户端命令行操作
启动客户端
[root@localhost bin]# ./zkCli.sh
显示所有操作命令
help
查看当前znode中所包含的内容
ls /
查看当前节点详细数据
ls -s /
- cZxid:创建节点的事务
- 每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID。
- 事务ID是ZooKeeper中所有修改总的次序。
- 每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。
- ctime:被创建的毫秒数(从1970年开始)
- mZxid:最后更新的事务zxid
- mtime:最后修改的毫秒数(从1970年开始)
- pZxid:最后更新的子节点zxid
- cversion:创建版本号,子节点修改次数
- dataVersion:数据变化版本号
- aclVersion:权限版本号
- ephemeralOwner:如果是临时节点,这个是znode拥有者的session id。如果不是临时节>点
则是0。- dataLength:数据长度
- numChildren:子节点数
分别创建2个普通节点
- 在根目录下,创建中国和美国两个节点
create /china
create /usa
- 在根目录下,创建俄罗斯节点,并保存“普京”数据到节点上
create /ru "pujing"
- 多级创建节点
- 在日本下,创建东京 “热”
- japan必须提前创建好,否则报错 “节点不存在”
create /japan/Tokyo "hot"
获得节点的值
get /japan/Tokyo
创建短暂节点:
创建成功之后,quit退出客户端,重新连接,短暂的节点消失
create -e /uk
ls /
quit
ls /
创建带序号的节点
- 在俄罗斯ru下,创建3个city
create -s /ru/city # 执行三次
ls /ru
[city0000000000, city0000000001, city0000000002]
- 如果原来没有序号节点,序号从0开始递增。
- 如果原节点下已有2个节点,则再排序时从2开始,以此类推
修改节点数据值
set /japan/Tokyo "too hot"
监听节点
监听 节点的值变化 或 子节点变化(路径变化)
- 在server3主机上注册监听/usa节点的数据变化
addWatch /usa
- 在Server1主机上修改/usa的数据
set /usa "telangpu"
- Server3会立刻响应
WatchedEvent state:SyncConnected type:NodeDataChanged path:/usa - 如果在Server1的/usa下面创建子节点NewYork
create /usa/NewYork
- Server3会立刻响应
WatchedEvent state:SyncConnected type:NodeCreatedpath:/usa/NewYork
删除节点
delete /usa/NewYork
递归删除节点 (非空节点,节点下有子节点)
不仅删除/ru,而且/ru下的所有子节点也随之删除
deleteall /ru
4 zookeeper集群和基本命令的更多相关文章
- zookeeper集群配置与启动
摘要:Zookeeper是一个很好的集群管理工具,被大量用于分布式计算.如Hadoop以及Storm系统中.这里简单记录下Zookeeper集群环境的搭建过程.本文以Ubuntu 12.04 LTS作 ...
- zookeeper集群的搭建以及hadoop ha的相关配置
1.环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 master作为active主机,data1作为standby备用机,三台机器均作为数据节点,yarn资源 ...
- ZooKeeper1 利用虚拟机搭建自己的ZooKeeper集群
前言: 前段时间自己参考网上的文章,梳理了一下基于分布式环境部署的业务系统在解决数据一致性问题上的方案,其中有一个方案是使用ZooKeeper,加之在大数据处理中,ZooKeeper确实起 ...
- 构建高可用ZooKeeper集群
ZooKeeper 是 Apache 的一个顶级项目,为分布式应用提供高效.高可用的分布式协调服务,提供了诸如数据发布/订阅.负载均衡.命名服务.分布式协调/通知和分布式锁等分布式基础服务.由于 Zo ...
- 搭建zookeeper集群
简介: Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群管理.分布式应用配置 ...
- ZooKeeper集群搭建中的Connection refused而导致的启动失败
1. 前言 每一次搭建集群环境都像一次战斗,作战中任何一个细节的出错都会导致严重的后果,所以搭建中所需要做的配置如系统配置.网络配置(防火墙记得关).用户权限.文件权限还有配置文件等等内容,都必须非常 ...
- zookeeper集群
0,Zookeeper基本原理 ZooKeeper集群由一组Server节点组成,这一组Server节点中存在一个角色为Leader的节点,其他节点都为Follower.当客户端Client连接到Zo ...
- 分布式架构中一致性解决方案——Zookeeper集群搭建
当我们的项目在不知不觉中做大了之后,各种问题就出来了,真jb头疼,比如性能,业务系统的并行计算的一致性协调问题,比如分布式架构的事务问题, 我们需要多台机器共同commit事务,经典的案例当然是银行转 ...
- 构建高可用ZooKeeper集群(转载)
ZooKeeper 是 Apache 的一个顶级项目,为分布式应用提供高效.高可用的分布式协调服务,提供了诸如数据发布/订阅.负载均衡.命名服务.分布式协调/通知和分布式锁等分布式基础服务.由于 Zo ...
随机推荐
- spring 拦截器流程 HandlerInterceptor AsyncHandlerInterceptor HandlerInterceptorAdapter
HandlerInterceptor源码 3种方法: preHandle:拦截于请求刚进入时,进行判断,需要boolean返回值,如果返回true将继续执行,如果返回false,将不进行执行.一般用于 ...
- js实时查询,为空提示
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- leetcode704二分查找
title: 二分查找 题目描述 题目链接:二分查找 解题思路 二分模板默写 int search(vector<int>& nums, int target) { int lef ...
- 手把手教你 在IDEA搭建 SparkSQL的开发环境
1. 创建maven项目 在IDEA中添加scala插件 并添加scala的sdk https://www.cnblogs.com/bajiaotai/p/15381309.html 2. 相关依赖j ...
- (AAAI2020 Yao) Graph Few-shot Learning via knowledge transfer
22-5-13 seminar上和大家分享了这篇文章 [0]Graph few-shot learning via knowledge transfer 起因是在MLNLP的公众号上看到了张初旭老师讲 ...
- 【SNOI2017 DAY1】炸弹
题意:P5024 思路:首先\(O(n^2)\)向能炸到的点连边,所以能到达的点的个数就是能到达的点的个数.然后显然要缩点+拓扑排序(我写的记搜). 然后再写一个线段树优化建图. 然后就WA了,我想了 ...
- 官方出品,比 mydumper 更快的逻辑备份工具
mysqldump 和 mydumper 是我们常用的两个逻辑备份工具. 无论是 mysqldump 还是 mydumper 都是将备份数据通过 INSERT 的方式写入到备份文件中. 恢复时,myl ...
- DML数据操作语言
DML数据操作语言 用来对数据库中表的数据记录进行更新.(增删改) 插入insert -- insert into 表(列名1,列名2,列名3...) values (值1,值2,值3...):向表中 ...
- React简单教程-3.1-样式之使用 tailwindcss
前言 本文是作为一个额外内容,主要介绍 tailwindcss 的用法 tailwindcss 是一个功能类优先的 CSS 框架,我在以前的文章里有描述为什么使用功能类优先:为什么我在 css 里使用 ...
- 使用JavaCV实现读取视频信息及自动截取封面图
概述 最近在对之前写的一个 Spring Boot 的视频网站项目做功能完善,需要利用 FFmpeg 实现读取视频信息和自动截图的功能,查阅资料后发现网上这部分的内容非常少,于是就有了这篇文章. 视频 ...