NLP教程(4) - 句法分析与依存解析

作者:韩信子@ShowMeAI
教程地址:http://www.showmeai.tech/tutorials/36
本文地址:http://www.showmeai.tech/article-detail/237
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容

本系列为斯坦福CS224n《自然语言处理与深度学习(Natural Language Processing with Deep Learning)》的全套学习笔记,对应的课程视频可以在 这里 查看。

ShowMeAI为CS224n课程的全部课件,做了中文翻译和注释,并制作成了 GIF动图!点击 第5讲-句法分析与依存解析 查看的课件注释与带学解读。更多资料获取方式见文末。
概述
CS224n是顶级院校斯坦福出品的深度学习与自然语言处理方向专业课程,核心内容覆盖RNN、LSTM、CNN、transformer、bert、问答、摘要、文本生成、语言模型、阅读理解等前沿内容。
笔记核心词
- Dependency Grammar
- Dependency Structure
- Neural Dependency Parsing
- 依存解析
- 依存句法
- 语法依赖
1.依存语法与依存结构
与编译器中的解析树类似,NLP中的解析树是用于分析句子的句法结构。使用的结构主要有两种类型——短语结构 和 依存结构。
短语结构文法使用短语结构语法将词组织成嵌套成分。后面的内容会展开对它做更详细的说明。我们现在关注依存语法。
句子的依存结构展示了单词依赖于另外一个单词 (修饰或者是参数)。词与词之间的二元非对称关系称为依存关系,描述为从head (被修饰的主题) 用箭头指向dependent (修饰语)。一般这些依存关系形成树结构,他们通常用语法关系的名称 (主体,介词宾语,同位语等)。
Bills on ports and immigration were submitted by Senator Brownback, Republican of Kansas. 依存树的例子如下图所示:

有时,在依存树的头部增加一个假的ROOT节点,这样每个单词都依存于唯一一个节点。
1.1 依存分析
依存语法是给定一个输入句子 \(S\),分析句子的句法依存结构的任务。依存句法的输出是一棵依存语法树,其中输入句子的单词是通过依存关系的方式连接。
正式一点定义,依存语法问题就是创建一个输入句子的单词 \(S=w_{0}w_{1} \cdots w_{n}\) (其中 \(w_{0}\) 是 ROOT) 到它的依存语法树的映射图 \(G\)。最近几年提出了很多以依存句法为基础的的变体,包括基于神经网络的方法,我们将会在后面介绍。
确切地说,在依存语法中有两个子问题:
- 学习:给定用依赖语法图标注的句子的训练集 \(D\),创建一个可以用于解析新句子的解析模型 \(M\)
- 解析:给定解析模型 \(M\) 和句子 \(S\),根据 \(M\) 得到 \(S\) 的最优依存语法图
1.2 基于转移的依存分析
Transition-based 依存语法依赖于定义可能转换的状态机,以创建从输入句到依存句法树的映射。
- 「学习」问题是创建一个可以根据转移历史来预测状态机中的下一个转换的模型。
- 「解析」问题是使用在学习问题中得到的模型对输入句子构建一个最优的转移序列。
大多数 Transition-based 系统不会使用正式的语法。
1.3 Greedy Deterministic Transition-Based Parsing
这个系统是由 Nivre 在 2003 年提出,与当时的常用方法截然不同。
这个转换系统是一个状态机,它由状态和这些状态之间的转换组成。该模型导出了从初始状态到几种终端状态之一的一系列转换。
1) 状态
对任意句子 \(S=w_{0}w_{1} \cdots w_{n}\),一个状态可以描述为一个三元组 \(c=(\sigma, \beta,A)\):
① 来自 \(S\) 的单词 \(w_{i}\) 的堆 \(\sigma\)
② 来自 \(S\) 的单词 \(w_{i}\) 的缓冲区 \(\beta\)
③ 一组形式为 \((w_{i},r,w_{j})\) 的依存弧,其中 \(w_{i},w_{j}\) 是来自 \(S\),和 \(r\) 描述依存关系。
因此,对于任意句子 \(S=w_{0}w_{1} \cdots w_{n}\):
① 一个形式为 \(([w_{0}]_{\sigma},[w_{1}, \cdots ,w_{n}]_{\beta},\varnothing)\) 的初始状态 \(c_{0}\) (现在只有 ROOT 在堆 \(\sigma\) 中,没有被选择的单词都在缓冲区 \(\beta\) 中。
② 一个形式为 \((\sigma,[]_{\beta},A)\) 的终点状态。
2) 转移
在状态之间有三种不同类型的转移:
① \(SHIFT\):移除在缓冲区的第一个单词,然后将其放在堆的顶部 (前提条件:缓冲区不能为空)。
② \(Left\text{-}Arc_{r}\):向依存弧集合 \(A\) 中加入一个依存弧 \((w_{j},r,w_{i})\),其中 \(w_{i}\) 是堆顶的第二个单词, \(w_{j}\) 是堆顶部的单词。从栈中移除 \(w_{i}\) (前提条件:堆必须包含两个单词以及 \(w_{i}\) 不是 ROOT )
③ \(Right\text{-}Arc_{r}\):向依存弧集合 \(A\) 中加入一个依存弧 \((w_{i},r,w_{j})\),其中 \(w_{i}\) 是堆顶的第二个单词, \(w_{j}\) 是堆顶部的单词。从栈中移除 \(w_{j}\) (前提条件:堆必须包含两个单词)
下图给出了这三个转换的更正式的定义:
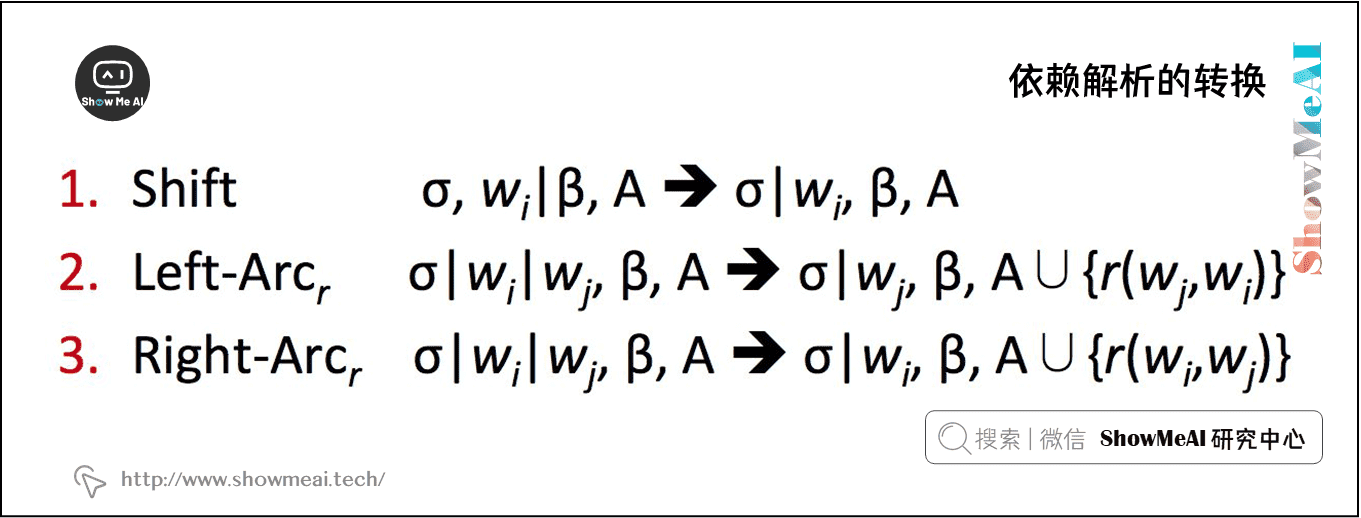
1.4 神经网络依存解析器
虽然依赖项解析有很多深层模型,这部分特别侧重于贪心,基于转移的神经网络依存语法解析器。与传统的基于特征的判别依存语法解析器相比,神经网络依存语法解析器性能和效果更好。与以前模型的主要区别在于这类模型依赖稠密而不是稀疏的特征表示。
我们将要描述的模型采用上一部分中讲述的标准依存弧转换系统。最终,模型的目标是预测从一些初始状态 \(c\) 到一个终点状态的转换序列,对模型中的依存语法树进行编码的。
由于模型是贪心的,它基于从当前的状态 \(c=(\sigma, \beta, A)\) 提取特征,然后尝试一次正确地预测一次转移 \(T\in \{SHIFT, Left\text{-}Arc_{r},Right\text{-}Arc_{r}\}\)。回想一下, \(\sigma\) 是栈,\(\beta\) 是缓存, \(A\) 是对于一个给定的句子的依赖弧的集合。
1) 特征选择
根据该模型所需的复杂性,定义神经网络的输入是灵活的。对给定句子 \(S\) 的特征包含一些子集:
① \(S_{word}\):在堆 \(\sigma\) 的顶部和缓冲区 \(\beta\) 的 \(S\) 中一些单词的词向量 (和它们的依存)。
② \(S_{tag}\):在 \(S\) 中一些单词的词性标注 ( POS )。词性标注是由一个离散集合组成:\(\mathcal{P}=\{NN,NNP,NNS,DT,JJ, \cdots \}\)。
③ \(S_{label}\):在 \(S\) 中一些单词的依存标签。依存标签是由一个依存关系的离散集合组成:\(\mathcal{L}=\{amod,tmod,nsubj,csubj,dobj, \cdots \}\)。
对每种特征类型,我们都有一个对应的将特征的 one-hot 编码映射到一个 \(d\) 维的稠密的向量表示的嵌入矩阵。
\(S_{word}\) 的完全嵌入矩阵是 \(E^{w}\in \mathbb{R}^{d\times N_{w}}\),其中 \(N_{w}\) 是字典/词汇表的大小。
POS 和依存标签的嵌入矩阵分别为 \(E^{t}\in \mathbb{R}^{d\times N_{t}}\) 和 \(E^{l}\in \mathbb{R}^{d\times N_{l}}\),其中 \(N_{t}\) 和 \(N_{l}\) 分别为不同词性标注和依存标签的个数。
最后,定义从每组特征中选出的元素的数量分别为 \(n_{word}\),\(n_{tag}\),\(n_{label}\)。
2) 特征选择的例子
作为一个例子,考虑一下对 \(S_{word}\),\(S_{tag}\) 和 \(S_{label}\) 的选择:
① \(S_{word}\):在堆和缓冲区的前三个单词:\(s_{1},s_{2},s_{3},b_{1},b_{2},b_{3}\)。栈顶部两个单词的第一个和第二个的 leftmost / rightmost 的子单词:\(lc_{1}(s_{i}),rc_{1}(s_{i}),lc_{2}(s_{i}),rc_{2}(s_{i}),i=1,2\)。栈顶部两个单词的第一个和第二个的 leftmost of leftmost / rightmost of rightmost 的子单词:\(lc_{1}(lc_{1}(s_{i})),rc_{1}(rc_{1}(s_{i})),i=1,2\)。\(S_{word}\) 总共含有 \(n_{word}=18\) 个元素。
② \(S_{tag}\):相应的词性标注,则 \(S_{tag}\) 含有 \(n_{tag}=18\) 个元素。
③ \(S_{label}\):单词的对应的依存标签,不包括堆/缓冲区上的 \(6\) 个单词,因此 \(S_{label}\) 含有 \(n_{label}=12\) 个元素。
注意我们使用一个特殊的 \(NULL\) 表示不存在的元素:当堆和缓冲区为空或者还没有指定依存关系时。
对一个给定句子例子,我们按照上述的方法选择单词,词性标注和依存标签,从嵌入矩阵 \(E^{w},E^{t},E^{l}\) 中提取它们对应的稠密的特征的表示,然后将这些向量连接起来作为输入 \([x^{w},x^{t},x^{l}]\)。
在训练阶段,我们反向传播到稠密的向量表示,以及后面各层的参数。
3) 前馈神经网络模型
(关于前馈神经网络的内容也可以参考ShowMeAI的对吴恩达老师课程的总结文章深度学习教程 | 神经网络基础,深度学习教程 | 浅层神经网络和深度学习教程 | 深层神经网络)
这个神经网络包含一个输入层 \([x^{w},x^{t},x^{l}]\),一个隐藏层,以及具有交叉熵损失函数的最终 softmax 层。
我们可以在隐藏层中定义单个权值矩阵,与 \([x^{w},x^{t},x^{l}]\) 进行运算,我们可以使用三个权值矩阵 \([W^{w}_{1},W^{t}_{1},W^{l}_{1}]\),每个矩阵对应着相应的输入类型,如下图所示。
然后我们应用一个非线性函数并使用一个额外的仿射层 \([W_{2}]\),使得对于可能的转移次数 (输出维度) ,有相同数量的 softmax 概率。
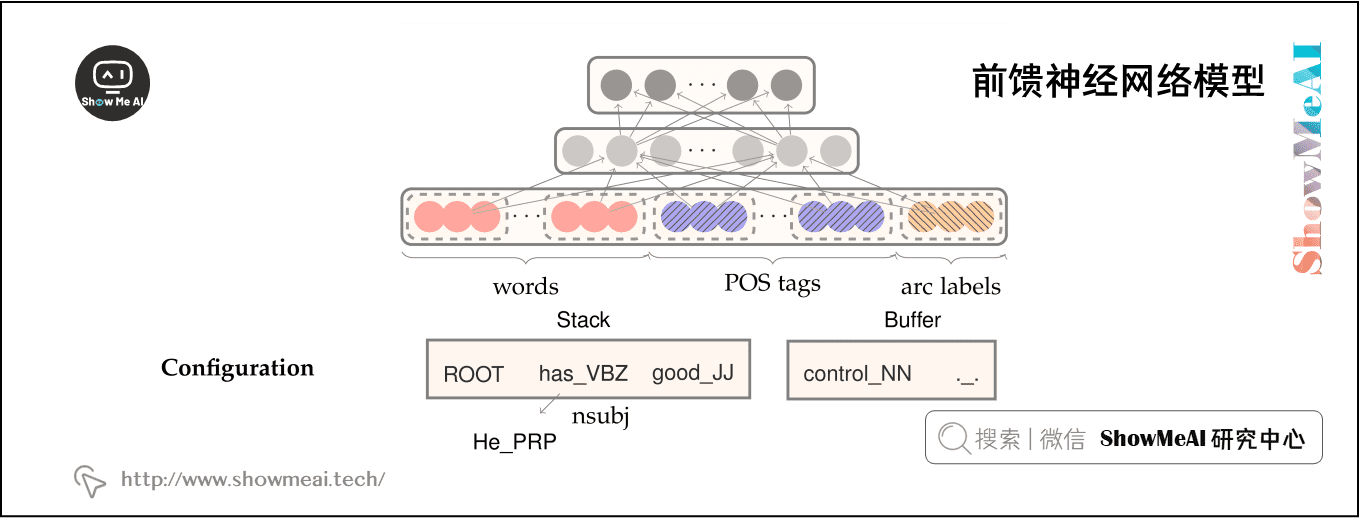
- Softmax layer: \(p=\operatorname{softmax}\left(W_{2} h\right)\)
- Hidden layer: \(h=\left(W_{1}^{w} x^{w}+W_{1}^{t} x^{t}+W_{1}^{l} x^{l}+b_{1}\right)^{3}\)
- Input layer:\(\left[x^{w}, x^{t}, x^{l}\right]\)
注意在上图中,使用的非线性函数是 \(f(x)=x^{3}\)。
有关 greedy transition-based 神经网络依存语法解析器的更完整的解释,请参考论文:[A Fast and Accurate Dependency Parser using Neural Networks](https://cs.stanford.edu/~danqi/papers/emnlp2014.pdf)。
2.参考资料
- 本教程的在线阅读版本
- 《斯坦福CS224n深度学习与自然语言处理》课程学习指南
- 《斯坦福CS224n深度学习与自然语言处理》课程大作业解析
- 【双语字幕视频】斯坦福CS224n | 深度学习与自然语言处理(2019·全20讲)
ShowMeAI 系列教程推荐
- 大厂技术实现 | 推荐与广告计算解决方案
- 大厂技术实现 | 计算机视觉解决方案
- 大厂技术实现 | 自然语言处理行业解决方案
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程 | 吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程 | 斯坦福CS224n课程 · 课程带学与全套笔记解读
NLP系列教程文章
- NLP教程(1)- 词向量、SVD分解与Word2vec
- NLP教程(2)- GloVe及词向量的训练与评估
- NLP教程(3)- 神经网络与反向传播
- NLP教程(4)- 句法分析与依存解析
- NLP教程(5)- 语言模型、RNN、GRU与LSTM
- NLP教程(6)- 神经机器翻译、seq2seq与注意力机制
- NLP教程(7)- 问答系统
- NLP教程(8)- NLP中的卷积神经网络
- NLP教程(9)- 句法分析与树形递归神经网络
斯坦福 CS224n 课程带学详解
- 斯坦福NLP课程 | 第1讲 - NLP介绍与词向量初步
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
- 斯坦福NLP课程 | 第3讲 - 神经网络知识回顾
- 斯坦福NLP课程 | 第4讲 - 神经网络反向传播与计算图
- 斯坦福NLP课程 | 第5讲 - 句法分析与依存解析
- 斯坦福NLP课程 | 第6讲 - 循环神经网络与语言模型
- 斯坦福NLP课程 | 第7讲 - 梯度消失问题与RNN变种
- 斯坦福NLP课程 | 第8讲 - 机器翻译、seq2seq与注意力机制
- 斯坦福NLP课程 | 第9讲 - cs224n课程大项目实用技巧与经验
- 斯坦福NLP课程 | 第10讲 - NLP中的问答系统
- 斯坦福NLP课程 | 第11讲 - NLP中的卷积神经网络
- 斯坦福NLP课程 | 第12讲 - 子词模型
- 斯坦福NLP课程 | 第13讲 - 基于上下文的表征与NLP预训练模型
- 斯坦福NLP课程 | 第14讲 - Transformers自注意力与生成模型
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
- 斯坦福NLP课程 | 第16讲 - 指代消解问题与神经网络方法
- 斯坦福NLP课程 | 第17讲 - 多任务学习(以问答系统为例)
- 斯坦福NLP课程 | 第18讲 - 句法分析与树形递归神经网络
- 斯坦福NLP课程 | 第19讲 - AI安全偏见与公平
- 斯坦福NLP课程 | 第20讲 - NLP与深度学习的未来

NLP教程(4) - 句法分析与依存解析的更多相关文章
- NLP基础 成分句法分析和依存句法分析
正则匹配: .除换行符所有的 ?表示0次或者1次 *表示0次或者n次 a(bc)+表示bc至少出现1次 ^x.*g$表示字符串以x开头,g结束 |或者 http://regexr.com/ 依存句法分 ...
- NLP教程(2) | GloVe及词向量的训练与评估
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- NLP教程(3) | 神经网络与反向传播
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- NLP教程(5) - 语言模型、RNN、GRU与LSTM
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- NLP教程(6) - 神经机器翻译、seq2seq与注意力机制
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- NLP教程(7) - 问答系统
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- Spring 系列教程之自定义标签的解析
Spring 系列教程之自定义标签的解析 在之前的章节中,我们提到了在 Spring 中存在默认标签与自定义标签两种,而在上一章节中我们分析了 Spring 中对默认标签的解析过程,相信大家一定已经有 ...
- Spring 系列教程之默认标签的解析
Spring 系列教程之默认标签的解析 之前提到过 Spring 中的标签包括默认标签和自定义标签两种,而两种标签的用法以及解析方式存在着很大的不同,本章节重点带领读者详细分析默认标签的解析过程. 默 ...
- NLP(十二)依存句法分析的可视化及图分析
依存句法分析的效果虽然没有像分词.NER的效果来的好,但也有其使用价值,在日常的工作中,我们免不了要和其打交道.笔者这几天一直在想如何分析依存句法分析的结果,一个重要的方面便是其可视化和它的图分析 ...
随机推荐
- vue集成webpack,遭遇 SyntaxError: Unknown word
这个错误根本和我的项目八竿子打不着,错误原因是配置了 css 的rule,将 这个rule注释掉,正常运行没有问题, 可是我却有强迫症,既然处理 node_modules 文件里才出现的错误,那么我就 ...
- Thymeleaf集成Shiro,shiro权限使用el表达式
如果是Thymeleaf集成Shiro的话, 如果使用Shiro在页面上权限字符串需使用thymeleaf的表达式的话, 如果权限字符串在实例级别的话, 可以使用这种方式进行权限字符串的动态实例控制 ...
- Markdown入门操作
Markdown基本操作 一. 字体 1. 标题 (1). 一级标题 "# + 标题名" (2). 其余类推 (最多支持6级标题) 加粗 " ** + 内容 + ** & ...
- c++ 虚函数多态、纯虚函数、虚函数表指针、虚基类表指针详解
静态多态.动态多态 静态多态:程序在编译阶段就可以确定调用哪个函数.这种情况叫做静态多态.比如重载,编译器根据传递给函数的参数和函数名决定具体要使用哪一个函数.动态多态:在运行期间才可以确定最终调用的 ...
- 用jq实现移动端滑动轮播以及定时轮播效果
Html的代码: <div class="carousel_img"> <div class="car_img" style="ba ...
- video标签学习使用
video标签学习使用 学习前的理解 video是HTML5中的新标签,可以用来播放视频.对于不同的浏览器支持的视频格式不一样,但是具体浏览器支持的类型并不清楚. 支持的类型 视频的格式分为编码格式和 ...
- CSS简单样式练习(二)
运行效果: 源代码: 1 <!DOCTYPE html> 2 <html lang="zh"> 3 <head> 4 <meta char ...
- 生成swap分区之利用磁盘分区
生成swap 分区方式很多,有利用磁盘分区来生成swap,这种效率比较高,他并不是文件系统, 另外我们还可以拿出磁盘一些空间,做成swap分区还有通过lvm逻辑卷的方式创建swap分区(这种分区就可以 ...
- mysql4与mysql5的区别_MySQL 4.1/5.0/5.1/5.5/5.6各版本的主要区别
MySQL 4.1/5.0/5.1/5.5/5.6各版本的主要区别 一.5.0 增加了Stored procedures.Views.Cursors.Triggers.XA transactions的 ...
- 2.Docker容器学习之新生入门必备基础知识
0x02 Docker 核心概念 描述:Docker的三大核心概念镜像/容器和仓库, 通过三大对象核心概念所构建的高效工作流程; 1.镜像 [image] 描述:images 类似于虚拟机镜像,借鉴了 ...