boxcox1p归一化+pipeline+StackingCVRegressor
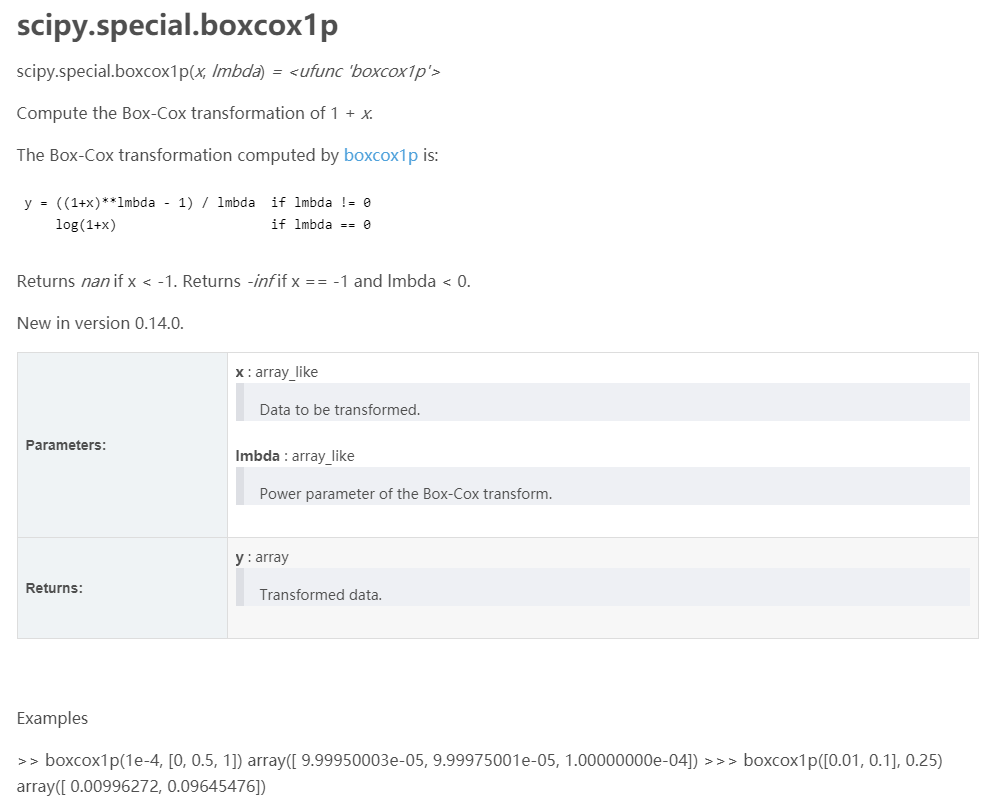
找到最好的那个参数lmbda。







from mlxtend.regressor import StackingCVRegressor
from sklearn.datasets import load_boston
from sklearn.svm import SVR
from sklearn.linear_model import Lasso
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
import numpy as np
RANDOM_SEED = 42
X, y = load_boston(return_X_y=True)
svr = SVR(kernel='linear')
lasso = Lasso()
rf = RandomForestRegressor(n_estimators=5,
random_state=RANDOM_SEED)
# The StackingCVRegressor uses scikit-learn's check_cv
# internally, which doesn't support a random seed. Thus
# NumPy's random seed need to be specified explicitely for
# deterministic behavior
np.random.seed(RANDOM_SEED)
stack = StackingCVRegressor(regressors=(svr, lasso, rf),
meta_regressor=lasso)
print('5-fold cross validation scores:\n')
for clf, label in zip([svr, lasso, rf, stack], ['SVM', 'Lasso','Random Forest','StackingClassifier']):
scores = cross_val_score(clf, X, y, cv=5)
print("R^2 Score: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
5-fold cross validation scores:
R^2 Score: 0.45 (+/- 0.29) [SVM]
R^2 Score: 0.43 (+/- 0.14) [Lasso]
R^2 Score: 0.52 (+/- 0.28) [Random Forest]
R^2 Score: 0.58 (+/- 0.24) [StackingClassifier]
# The StackingCVRegressor uses scikit-learn's check_cv
# internally, which doesn't support a random seed. Thus
# NumPy's random seed need to be specified explicitely for
# deterministic behavior
np.random.seed(RANDOM_SEED)
stack = StackingCVRegressor(regressors=(svr, lasso, rf),
meta_regressor=lasso)
print('5-fold cross validation scores:\n')
for clf, label in zip([svr, lasso, rf, stack], ['SVM', 'Lasso','Random Forest','StackingClassifier']):
scores = cross_val_score(clf, X, y, cv=5, scoring='neg_mean_squared_error')
print("Neg. MSE Score: %0.2f (+/- %0.2f) [%s]"

from mlxtend.regressor import StackingCVRegressor
from sklearn.datasets import load_boston
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
X, y = load_boston(return_X_y=True)
ridge = Ridge()
lasso = Lasso()
rf = RandomForestRegressor(random_state=RANDOM_SEED)
# The StackingCVRegressor uses scikit-learn's check_cv
# internally, which doesn't support a random seed. Thus
# NumPy's random seed need to be specified explicitely for
# deterministic behavior
np.random.seed(RANDOM_SEED) stack = StackingCVRegressor(regressors=(lasso, ridge),
meta_regressor=rf,
use_features_in_secondary=True)
params = {'lasso__alpha': [0.1, 1.0, 10.0],
'ridge__alpha': [0.1, 1.0, 10.0]} grid = GridSearchCV(
estimator=stack,param_grid={'lasso__alpha': [x/5.0 for x in range(1, 10)],
'ridge__alpha': [x/20.0 for x in range(1, 10)],
'meta-randomforestregressor__n_estimators': [10,100]},
cv=5,
refit=True
) grid.fit(X, y) print("Best: %f using %s" % (grid.best_score_, grid.best_params_)) #Best: 0.673590 using {'lasso__alpha': 0.4, 'meta-randomforestregressor__n_estimators': 10, 'ridge__alpha cv_keys = ('mean_test_score', 'std_test_score', 'params')
for r, _ in enumerate(grid.cv_results_['mean_test_score']):
print("%0.3f +/- %0.2f %r"
% (grid.cv_results_[cv_keys[0]][r],
grid.cv_results_[cv_keys[1]][r] / 2.0,
grid.cv_results_[cv_keys[2]][r]))
if r > 10:
break
print('...') print('Best parameters: %s' % grid.best_params_)
print('Accuracy: %.2f' % grid.best_score_)
boxcox1p归一化+pipeline+StackingCVRegressor的更多相关文章
- 1.3:Render Pipeline and GPU Pipeline
文章著作权归作者所有.转载请联系作者,并在文中注明出处,给出原文链接. 本系列原更新于作者的github博客,这里给出链接. 在学习SubShader之前,我们有必要对 Render Pipeline ...
- sklearn pipeline
sklearn.pipeline pipeline的目的将许多算法模型串联起来,比如将特征提取.归一化.分类组织在一起形成一个典型的机器学习问题工作流. 优点: 1.直接调用fit和predict方法 ...
- 机器学习:多项式回归(scikit-learn中的多项式回归和 Pipeline)
一.scikit-learn 中的多项式回归 1)实例过程 模拟数据 import numpy as np import matplotlib.pyplot as plt x = np.random. ...
- GPU上创建目标检测Pipeline管道
GPU上创建目标检测Pipeline管道 Creating an Object Detection Pipeline for GPUs 今年3月早些时候,展示了retinanet示例,这是一个开源示例 ...
- 【笔记】多项式回归的思想以及在sklearn中使用多项式回归和pipeline
多项式回归以及在sklearn中使用多项式回归和pipeline 多项式回归 线性回归法有一个很大的局限性,就是假设数据背后是存在线性关系的,但是实际上,具有线性关系的数据集是相对来说比较少的,更多时 ...
- 多项式回归 & pipeline & 学习曲线 & 交叉验证
多项式回归就是数据的分布不满足线性关系,而是二次曲线或者更高维度的曲线.此时只能使用多项式回归来拟合曲线.比如如下数据,使用线性函数来拟合就明显不合适了. 接下来要做的就是升维,上面的真实函数是:$ ...
- redis大幅性能提升之使用管道(PipeLine)和批量(Batch)操作
前段时间在做用户画像的时候,遇到了这样的一个问题,记录某一个商品的用户购买群,刚好这种需求就可以用到Redis中的Set,key作为productID,value 就是具体的customerid集合, ...
- Building the Testing Pipeline
This essay is a part of my knowledge sharing session slides which are shared for development and qua ...
- 数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑
背景:数据挖掘/机器学习中的术语较多,而且我的知识有限.之前一直疑惑正则这个概念.所以写了篇博文梳理下 摘要: 1.正则化(Regularization) 1.1 正则化的目的 1.2 正则化的L1范 ...
随机推荐
- redis中scan和keys的区别
scan和keys的区别 redis的keys命令,通来在用来删除相关的key时使用,但这个命令有一个弊端,在redis拥有数百万及以上的keys的时候,会执行的比较慢,更为致命的是,这个命令会阻塞r ...
- Shell编程中的用户输入处理
Linux read命令用于从标准输入读取数值. read 内部命令被用来从标准输入读取单行数据.这个命令可以用来读取键盘输入,当使用重定向的时候,可以读取文件中的一行数据. 语法 read [-er ...
- NFS(Network File System)即网络文件系统 (转)
第1章 NFS介绍 1.1 NFS服务内容的概述 □ RPC服务知识概念介绍说明,以及RPC服务存在价值(必须理解掌握) □ NFS服务工作原理讲解(必须理解掌握) □ NFS共享文件系统使用原理讲解 ...
- Emoji与unicode特殊字符的处理
遇到了一个很让人纠结的问题:emoji表情在使用的过程中,会莫名其妙的消失,或者变成乱码,同时数据库用utf8mb4来存储,但是也出现了问题,冷备过后,导入进库的时候,变成了不可见字符,神奇的消失了! ...
- 定制博客CSS样式
首先你需要添加页面CSS代码
- NSTimer、CADisplayLink、GCD 三种定时器的用法 —— 昉
在软件开发过程中,我们常常需要在某个时间后执行某个方法,或者是按照某个周期一直执行某个方法.在这个时候,我们就需要用到定时器. 在iOS中有很多方法完成定时器的任务,例如 NSTimer.CADisp ...
- Ansible之roles模块--lnmp分布式部署
Ansible之roles模块--lnmp分布式部署 目录 Ansible之roles模块--lnmp分布式部署 1. role模块的作用 2. roles的目录结构 3. roles内个目录含义解释 ...
- 文件I/O流、文件、FileInputStreaam、FileOutputStream、FileReader、FileWriter的介绍和使用
一.文件:保存数据的地方 1.文件流:文件在程序中是以流的形式类操作的 类比: 流:数据在数据源(文件)和程序(内存)之间经历的路径 输入流:数据从数据源(文件)到程序(内存)的路径 输出流:数据从程 ...
- MLlib学习——基本统计
给定一个数据集,数据分析师一般会先观察一下数据集的基本情况,称之为汇总统计或者概要性统计.一般的概要性统计用于概括一系列观测值,包括位置或集中趋势(比如算术平均值.中位数.众数和四分位均值),展型(比 ...
- Scala中实现break与continue
Scala是函数式编程语言,因此没有直接的break与continue关键字,要实现break与continue效果,需要绕一下. 需要导入包: import util.control.Breaks. ...