数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑
背景:数据挖掘/机器学习中的术语较多,而且我的知识有限。之前一直疑惑正则这个概念。所以写了篇博文梳理下
摘要:
1.正则化(Regularization)
1.1 正则化的目的
1.2 正则化的L1范数(lasso),L2范数(ridge)
2.归一化 (Normalization)
2.1归一化的目的
2.1归一化计算方法
2.2.spark ml中的归一化
2.3 python中skelearn中的归一化
知识总结:
1.正则化(Regularization)
1.1 正则化的目的:我的理解就是平衡训练误差与模型复杂度的一种方式,通过加入正则项来避免过拟合(over-fitting)。
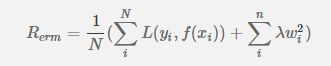
后面的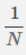
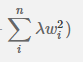 就是正则化项,其中λ越大表明惩罚粒度越大,等于0表示不做惩罚,N表示所有样本的数量,n表示参数的个数。
就是正则化项,其中λ越大表明惩罚粒度越大,等于0表示不做惩罚,N表示所有样本的数量,n表示参数的个数。

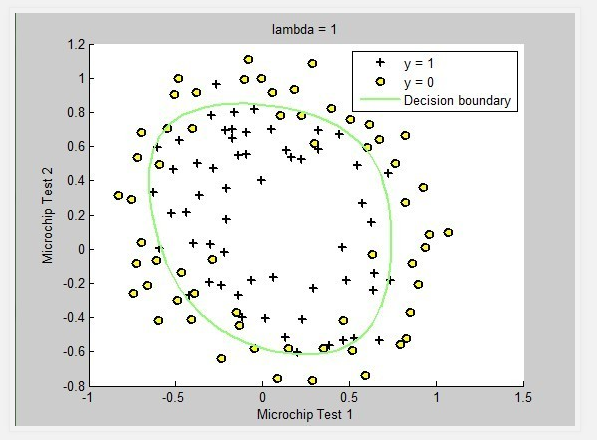
上图的 lambda = 0表示未做正则化,模型过于复杂(存在过拟合)
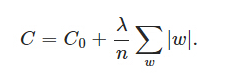 ,其中C0是代价函数,
,其中C0是代价函数,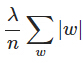 是L1正则项,lambda是正则化参数
是L1正则项,lambda是正则化参数
L2正则化:
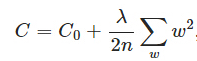 ,其中
,其中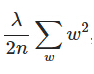 是L2正则项,lambda是正则化参数
是L2正则项,lambda是正则化参数
L1与L2正则化的比较:
1.L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。
2.Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
2.归一化 (Normalization)
2.1归一化的目的:
1)归一化后加快了梯度下降求最优解的速度;
2)归一化有可能提高精度。详解可查看
2.2归一化计算方法
2.3.spark ml中的归一化
newNormalizer(p: Double) ,其中p就是计算公式中的向量绝对值的幂指数
可以使用transform方法对Vector类型或者RDD[Vector]类型的数据进行正则化
下面举一个简单的例子:
scala> val dv: Vector = Vectors.dense(3.0,4.0)
dv: org.apache.spark.mllib.linalg.Vector = [3.0,4.0]
scala> val l2 = new Normalizer(2)
scala> l2.transform(dv)
res8: org.apache.spark.mllib.linalg.Vector = [0.6,0.8]
或者直接使用Vertors的norm方法:val norms = data.map(Vectors.norm(_, 2.0))
2.4 python中skelearn中的归一化
from sklearn.preprocessing import Normalizer
#归一化,返回值为归一化后的数据
Normalizer().fit_transform(iris.data)
数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑的更多相关文章
- 数据预处理 | 使用 Pandas 统一同一特征中不同的数据类型
出现的问题:如图,总消费金额本应该为float类型,此处却显示object 需求:将 TotalCharges 的类型转换成float 使用 pandas.to_numeric(arg, errors ...
- python中常用的九种数据预处理方法分享
Spyder Ctrl + 4/5: 块注释/块反注释 本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍; 1. 标准化(St ...
- sklearn中的数据预处理和特征工程
小伙伴们大家好~o( ̄▽ ̄)ブ,沉寂了这么久我又出来啦,这次先不翻译优质的文章了,这次我们回到Python中的机器学习,看一下Sklearn中的数据预处理和特征工程,老规矩还是先强调一下我的开发环境是 ...
- 机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化
1 数据无量纲化 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”.譬如梯度和矩阵为核心的算法中,譬如逻辑回 ...
- 文本数据预处理:sklearn 中 CountVectorizer、TfidfTransformer 和 TfidfVectorizer
文本数据预处理的第一步通常是进行分词,分词后会进行向量化的操作.在介绍向量化之前,我们先来了解下词袋模型. 1.词袋模型(Bag of words,简称 BoW ) 词袋模型假设我们不考虑文本中词与词 ...
- 深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用
深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用 周翼南 北京大学 工学硕士 373 人赞同了该文章 基于深 ...
- Python初探——sklearn库中数据预处理函数fit_transform()和transform()的区别
敲<Python机器学习及实践>上的code的时候,对于数据预处理中涉及到的fit_transform()函数和transform()函数之间的区别很模糊,查阅了很多资料,这里整理一下: ...
- postgreSQL使用sql归一化数据表的某列,以及出现“字段 ‘xxx’ 必须出现在 GROUP BY 子句中或者在聚合函数中”错误的可能原因之一
前言: 归一化(区别于标准化)一般是指,把数据变换到(0,1)之间的小数.主要是为了方便数据处理,或者把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权. 不过还是有很多人使用 ...
- 借助 SIMD 数据布局模板和数据预处理提高 SIMD 在动画中的使用效率
原文链接 简介 为发挥 SIMD1 的最大作用,除了对其进行矢量化处理2外,我们还需作出其他努力.可以尝试为循环添加 #pragma omp simd3,查看编译器是否成功进行矢量化,如果性能有所提升 ...
随机推荐
- javascript中的Array对象 —— 数组的合并、转换、迭代、排序、堆栈
Array 是javascript中经常用到的数据类型.javascript 的数组其他语言中数组的最大的区别是其每个数组项都可以保存任何类型的数据.本文主要讨论javascript中数组的声明.转换 ...
- PHP实现RTX发送消息提醒
RTX是腾讯公司推出的企业级即时通信平台,大多数公司都在使用它,但是我们很多时候需要将自己系统或者产品的一些通知实时推送给RTX,这就需要用到RTX的服务端SDK,建议先去看看RTX的SDK开发文档( ...
- 深入理解JS 执行细节
javascript从定义到执行,JS引擎在实现层做了很多初始化工作,因此在学习JS引擎工作机制之前,我们需要引入几个相关的概念:执行环境栈.全局对象.执行环境.变量对象.活动对象.作用域和作用域链等 ...
- 深入理解C#
简单认识.NET框架 (1)首先我们得知道 .NET框架具有两个主要组件:公共语言进行时CLR(Common Language Runtime)和框架类库FCL(Framework Class ...
- 微框架spark--api开发利器
spark简介 Spark(注意不要同Apache Spark混淆)的设计初衷是,可以简单容易地创建REST API或Web应用程序.它是一个灵活.简洁的框架,大小只有1MB.Spark允许用户自己选 ...
- web api接口同步和异步的问题
一般来说,如果一个api 接口带上Task和 async 一般就算得上是异步api接口了. 如果我想使用异步api接口,一般的动机是我在我的方法里面可能使用Task.Run 进行异步的去处理一个耗时的 ...
- Java之多态(二)
package test05;import test06.Car1;public class DuoTai_Test02 { /**多个对象,一个形态 * Tiger.Lion.Snake → Ani ...
- iOS 多线程之GCD的使用
在iOS开发中,遇到耗时操作,我们经常用到多线程技术.Grand Central Dispatch (GCD)是Apple开发的一个多核编程的解决方法,只需定义想要执行的任务,然后添加到适当的调度队列 ...
- 发布APP到app store
好久好久没写博客了,主要是 都在学习新东西,忙不赢啊. 近段时间在用AC平台学习开发移动APP, 今天开始发布应用. 在ac云控制台编译成ipa后,使用apple提供的Application Load ...
- 跟着老男孩教育学Python开发【第四篇】:模块
双层装饰器示例 __author__ = 'Golden' #!/usr/bin/env python # -*- coding:utf-8 -*- USER_INFO = {} def ch ...