微服务SpringCloud之zipkin链路追踪
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位服务故障点,以对症下药。于是就有了分布式系统调用跟踪的诞生。
Spring Cloud Sleuth
一般的,一个分布式服务跟踪系统,主要有三部分:数据收集、数据存储和数据展示。根据系统大小不同,每一部分的结构又有一定变化。譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分,实时数据用于故障排查(troubleshooting),全量数据用于系统优化;数据收集除了支持平台无关和开发语言无关系统的数据收集,还包括异步数据收集(需要跟踪队列中的消息,保证调用的连贯性),以及确保更小的侵入性;数据展示又涉及到数据挖掘和分析。虽然每一部分都可能变得很复杂,但基本原理都类似。
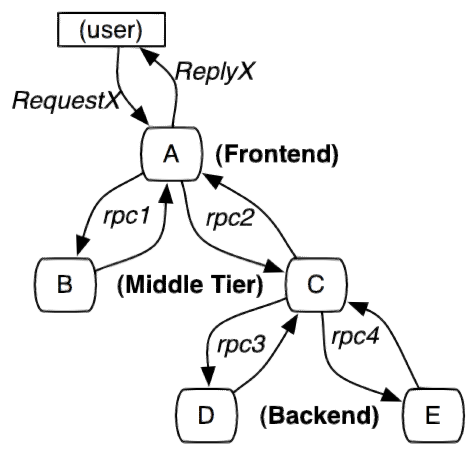
服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的过程,称为一个“trace”。每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录,称为一个“span”。这样,若干个有序的 span 就组成了一个 trace。在系统向外界提供服务的过程中,会不断地有请求和响应发生,也就会不断生成 trace,把这些带有span 的 trace 记录下来,就可以描绘出一幅系统的服务拓扑图。附带上 span 中的响应时间,以及请求成功与否等信息,就可以在发生问题的时候,找到异常的服务;根据历史数据,还可以从系统整体层面分析出哪里性能差,定位性能优化的目标。
Spring Cloud Sleuth为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外Sleuth可以帮助我们:
耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
spring cloud sleuth可以结合zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。
测试
1.启动zipkin server
由于是参考纯洁的微笑的博客http://www.ityouknow.com/springcloud/2018/02/02/spring-cloud-sleuth-zipkin.html,但在我创建zipkin-server项目引入注解@EnableZipkinServer时提示已不能使用。建议使用默认的zipkin的jar包,具体使用方法可以查看github的文档。这里直接下载下了jar,然后使用内存方式存储,java -jar zipkin-server-2.17.0-exec.jar.
/**
* @deprecated Custom servers are possible, but not supported by the community. Please use our
* <a href="https://github.com/openzipkin/zipkin#quick-start">default server build</a> first. If you
* find something missing, please <a href="https://gitter.im/openzipkin/zipkin">gitter</a> us about
* it before making a custom server.
*
* <p>If you decide to make a custom server, you accept responsibility for troubleshooting your
* build or configuration problems, even if such problems are a reaction to a change made by the
* OpenZipkin maintainers. In other words, custom servers are possible, but not supported.
*/
2.项目中添加zipkin的支持
在SpringColudZuulSimple、EurekaClient中引入依赖spring-cloud-starter-zipkin。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.1.3.RELEASE</version>
</dependency>
然后在application.properties中设置属性
spring.zipkin.base-url=http://localhost:9411
spring.sleuth.sampler.probability=1.0
spring.zipkin.base-url指定了Zipkin服务器的地址,spring.sleuth.sampler.percentage将采样比例设置为1.0,也就是全部都需要。
Spring Cloud Sleuth有一个Sampler策略,可以通过这个实现类来控制采样算法。采样器不会阻碍span相关id的产生,但是会对导出以及附加事件标签的相关操作造成影响。 Sleuth默认采样算法的实现是Reservoir sampling,具体的实现类是PercentageBasedSampler,默认的采样比例为: 0.1(即10%)。不过我们可以通过spring.sleuth.sampler.percentage来设置,所设置的值介于0.0到1.0之间,1.0则表示全部采集。
3.验证
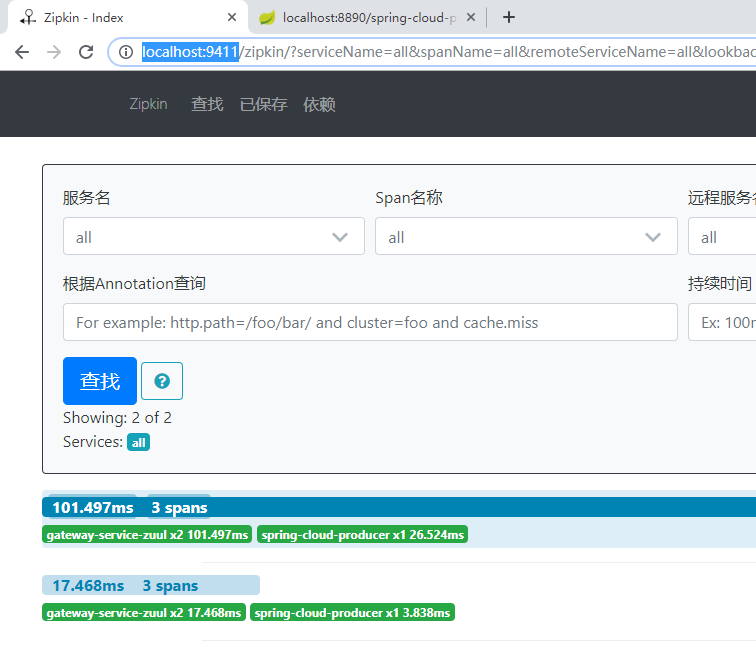
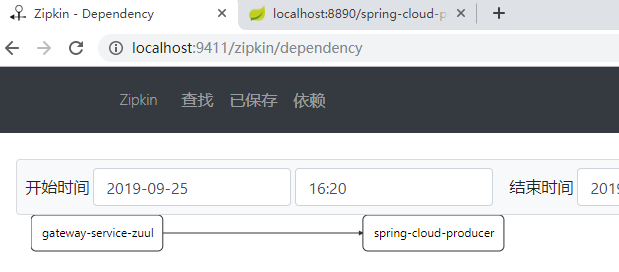
依次启动EurekaServer、EurekaClient、SpringColudZuulSimple,然后在浏览器中输入http://localhost:8890/spring-cloud-producer/hello?name=cuiyw&token=123,刷新几次,然后在http://localhost:9411页面点击查询,可以看到如下信息。
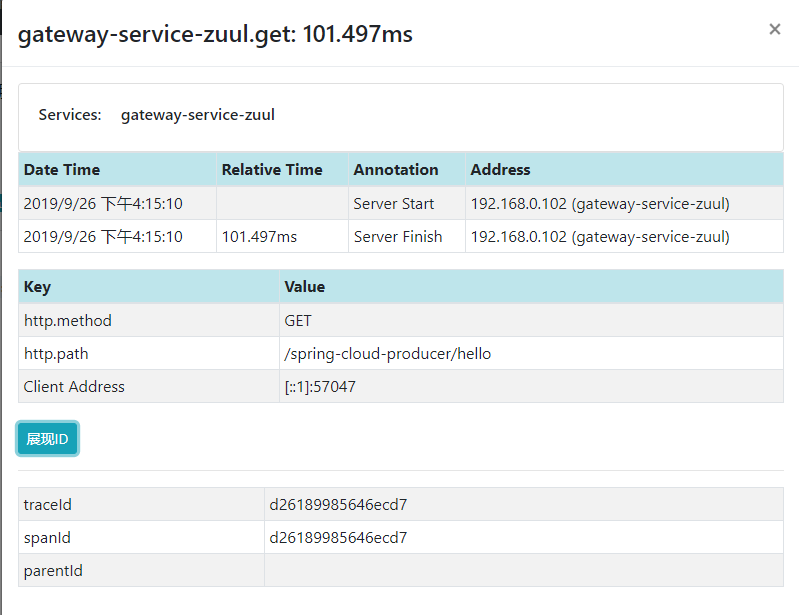
点击每项记录都能看到每项的具体耗时信息和顺序。
点击依赖分析,可以看到项目之间的调用关系
总结
这里使用的内存的方式来存储数据,生产环境一般会使用消息队列RabbitMQ、Kafka或者数据库mysql存储,具体使用方法可以查看zipkin的官方文档。
参考:http://www.ityouknow.com/springcloud/2018/02/02/spring-cloud-sleuth-zipkin.html
微服务SpringCloud之zipkin链路追踪的更多相关文章
- net core 微服务框架 Viper 调用链路追踪
1.Viper是什么? Viper 是.NET平台下的Anno微服务框架的一个示例项目.入门简单.安全.稳定.高可用.全平台可监控.底层通讯可以随意切换thrift grpc. 自带服务发现.调用链追 ...
- SpringCloud:Zipkin链路追踪,并将数据写入mysql
1.zipkin server 1.1.新建Springboot项目,zinkin 1.2.添加依赖 <dependency> <groupId>io.zipkin.java& ...
- 微服务 Zipkin 链路追踪原理(图文详解)
一个看起来很简单的应用,可能需要数十或数百个服务来支撑,一个请求就要多次服务调用. 当请求变慢.或者不能使用时,我们是不知道是哪个后台服务引起的. 这时,我们使用 Zipkin 就能解决这个问题. 由 ...
- SpringCloud与微服务Ⅲ --- SpringCloud入门概述
一. 什么是SpringCloud SpringCloud基于SpringBoot提供了一套微服务解决方案,包括服务注册与发现,配置中心,全链路监控,服务网关,负载均衡,熔断器等组件,除了基于NetF ...
- 微服务SpringCloud之配置中心和消息总线
在微服务SpringCloud之Spring Cloud Config配置中心SVN博客中每个client刷新配置信息时需要post请求/actuator/refresh,但客户端越来越多时,,需要每 ...
- Java生鲜电商平台-深入理解微服务SpringCloud各个组件的关联与架构
Java生鲜电商平台-深入理解微服务SpringCloud各个组件的关联与架构 概述 毫无疑问,Spring Cloud是目前微服务架构领域的翘楚,无数的书籍博客都在讲解这个技术.不过大多数讲解还停留 ...
- 小D课堂 - 新版本微服务springcloud+Docker教程_汇总
小D课堂 - 新版本微服务springcloud+Docker教程_1_01课程简介 小D课堂 - 新版本微服务springcloud+Docker教程_1_02技术选型 小D课堂 - 新版本微服务s ...
- 「 从0到1学习微服务SpringCloud 」10 服务网关Zuul
系列文章(更新ing): 「 从0到1学习微服务SpringCloud 」06 统一配置中心Spring Cloud Config 「 从0到1学习微服务SpringCloud 」07 RabbitM ...
- 「 从0到1学习微服务SpringCloud 」09 补充篇-maven父子模块项目
系列文章(更新ing): 「 从0到1学习微服务SpringCloud 」06 统一配置中心Spring Cloud Config 「 从0到1学习微服务SpringCloud 」07 RabbitM ...
随机推荐
- Azure Devops: COPY failed: stat /var/lib/docker/tmp/docker-builder268095359/xxxxxxx.csproj no such file or directory
在Azure Devops中部署docker镜像时, 出现COPY failed: stat /var/lib/docker/tmp/docker-builder268095359/xxxxxxx. ...
- Java集合框架之Map接口浅析
Java集合框架之Map接口浅析 一.Map接口综述: 1.1java.util.Map<k, v>简介 位于java.util包下的Map接口,是Java集合框架的重要成员,它是和Col ...
- 学测试,看视频?NONONO,除非这种情况
001 前言 : 很久没周末写文章了,一个是要睡懒觉.另外一个是,周末写了大家也没有心思看(加班1周了,好不容易周末,你又让我学习 ?先睡个懒觉再说,去TM的学习). 然而,今天早早的5点就起床了,处 ...
- js的兼容问题以及解决方式(持续更新)
我们在使用js操作页面的时候兼容问题是很常见的,下面将常见的兼容问题及其对应的解决方法分享给大家,并持续更新: 1.获取事件对象的兼容写法: IE中:window.event 正常浏览器中:对 ...
- c3p0,dbcp与druid 三大连接池的区别[转]
说到druid,这个是在开源中国开源项目中看到的,说是比较好的数据连接池.于是乎就看看.扯淡就到这. 下面就讲讲用的比较多的数据库连接池.(其实我最先接触的是dbcp这个) 1)DBCP DBCP是一 ...
- GIS基础知识 - 坐标系、投影、EPSG:4326、EPSG:3857
最近接手一个GIS项目,需要用到 PostGIS,GeoServer,OpenLayers 等工具组件,遇到一堆地理信息相关的术语名词,在这里做一个总结. 1. 大地测量学 (Geodesy) 大地测 ...
- 实参&形参
实参VS形参 1.实参 argument 实际参数,在函数调用的时候,传递给函数的参数.实参-按值调用 实际参数可以是变量.常量.表达式以及函数 实际参数必须得有确定的值(赋值.输入等),在函数调用时 ...
- 并发、线程的基本概念&线程启动结束
并发.进程.可执行程序.进程.线程的基本概念 1.并发 并发当有多个线程在操作时,如果系统只有一个CPU,则它根本不可能真正同时进行一个以上的线程,它只能把CPU运行时间划分成若干个时间段,再将时间段 ...
- lightoj 1046 - Rider(bfs)
A rider is a fantasy chess piece that can jump like a knight several times in a single move. A rider ...
- 牛客练习赛51 A abc
A. abc 题意: 给出一个字符串s,你需要做的是统计s中子串”abc”的个数.子串的定义就是存在任意下标a<b<c,那么”s[a]s[b]s[c]”就构成s的一个子串.如”abc”的子 ...