【Demo 1】基于object_detection API的行人检测 2:数据制作
项目文件结构
因为目录太多又太杂,而且数据格式对路径有要求,先把文件目录放出来。(博主目录结构并不规范)
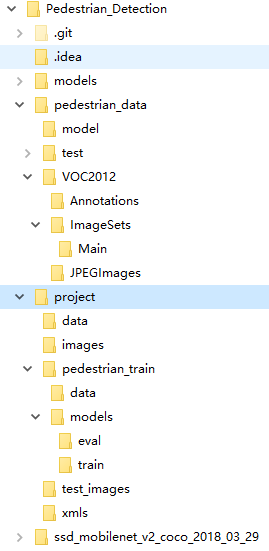
1、根目录下的models为克隆下来的项目。2、pedestrian_data目录下的路径以及文件夹名称必须相同,是VOC2012数据格式要求。3、project中data是视频数据,images是测试的图片数据、test_images为测试图片数据集,pedestrian_train文件夹为训练目录。
使用公开数据制作训练数据集
数据下载
视频数据下载:http://www.robots.ox.ac.uk/ActiveVision/Research/Projects/2009 bbenfold_headpose/Datasets/TownCentreXVID.avi
标注数据下载:http://www.robots.ox.ac.uk/ActiveVision/Research/Projects/2009 bbenfold_headpose/Datasets/TownCentre-groundtruth.top
官网(http://www.robots.ox.ac.uk/ActiveVision/index.html)
使用OpenCV生成图片数据
import cv2 as cv
import os def video2ims(src, train_path="images", test_path="test_images", factor=2):
os.mkdir(train_path)
os.mkdir(test_path)
frame = 0
cap = cv.VideoCapture(src)
counts = int(cap.get(cv.CAP_PROP_FRAME_COUNT))
w = int(cap.get(cv.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv.CAP_PROP_FRAME_HEIGHT))
print("number of frames : %d"%counts)
while True:
ret, im = cap.read()
if ret is True:
if frame < 3600: # 前3600帧作为训练数据
path = train_path
else:
path = test_path
im = cv.resize(im, (w//factor, h//factor)) # 压缩分辨率
cv.imwrite(os.path.join(path, str(frame)+".jpg"), im)
frame += 1
else:
break
cap.release() if __name__ == "__main__":
video2ims("Your TownCentreXVID.avi path")
把生成的图片拷贝到./pedestrian_data/OC2012/JPEGImages 目录下,图片大小为960*540。
制作Pasacal VOC2012数据集格式
利用标注信息文件TownCentre-groundtruth.top生成对应xml文件(注意文件路径)
import os
import pandas as pd if __name__ == '__main__': GT = pd.read_csv('D:/Study/dl/Pedestrian_Detection/TownCentre-groundtruth.top', header=None)
indent = lambda x, y: ''.join([' ' for _ in range(y)]) + x factor = 2
train_size = 3600 os.mkdir('xmls')
name = 'pedestrian'
width, height = 1920 // factor, 1080 // factor for frame_number in range(train_size): Frame = GT.loc[GT[1] == frame_number]
x1 = list(Frame[8])
y1 = list(Frame[11])
x2 = list(Frame[10])
y2 = list(Frame[9])
points = [[(round(x1_), round(y1_)), (round(x2_), round(y2_))] for x1_, y1_, x2_, y2_ in zip(x1, y1, x2, y2)] with open(os.path.join('xmls', str(frame_number) + '.xml'), 'w') as file:
file.write('<annotation>\n')
file.write(indent('<folder>voc2012</folder>\n', 1))
file.write(indent('<filename>' + str(frame_number) + '.jpg' + '</filename>\n', 1))
file.write(indent('<path>D:/Study/dl/Pedestrian_Detection/pedestrian_data/VOC2012/JPEGImages/' + str(frame_number) + '.jpg' + '</path>\n', 1))
file.write(indent('<size>\n', 1))
file.write(indent('<width>' + str(width) + '</width>\n', 2))
file.write(indent('<height>' + str(height) + '</height>\n', 2))
file.write(indent('<depth>3</depth>\n', 2))
file.write(indent('</size>\n', 1)) for point in points: top_left = point[0]
bottom_right = point[1] if top_left[0] > bottom_right[0]:
xmax, xmin = top_left[0] // factor, bottom_right[0] // factor
else:
xmin, xmax = top_left[0] // factor, bottom_right[0] // factor if top_left[1] > bottom_right[1]:
ymax, ymin = top_left[1] // factor, bottom_right[1] // factor
else:
ymin, ymax = top_left[1] // factor, bottom_right[1] // factor file.write(indent('<object>\n', 1))
file.write(indent('<name>' + name + '</name>\n', 2))
file.write(indent('<pose>Unspecified</pose>\n', 2))
file.write(indent('<truncated>' + str(0) + '</truncated>\n', 2))
file.write(indent('<difficult>' + str(0) + '</difficult>\n', 2))
file.write(indent('<bndbox>\n', 2))
file.write(indent('<xmin>' + str(xmin) + '</xmin>\n', 3))
file.write(indent('<ymin>' + str(ymin) + '</ymin>\n', 3))
file.write(indent('<xmax>' + str(xmax) + '</xmax>\n', 3))
file.write(indent('<ymax>' + str(ymax) + '</ymax>\n', 3))
file.write(indent('</bndbox>\n', 2))
file.write(indent('</object>\n', 1)) file.write('</annotation>\n') print('File:', frame_number, end='\r')
生成的xml文件全部复制到 ./pedestrian_data/OC2012/Annotations 目录下。
xml文件中标注的信息有:图片名称,目标,大小,通道数,目标所在位置,样本难易。
生成图片描述文件
用txt文件对图片进行描述,生成代码如下:
import os def generate_classes_text():
print("start to generate classes text...") m_text = open("D:/Study/dl/Pedestrian_Detection/pedestrian_data/trainval.txt", 'w')
for i in range():
m_text.write(str(i) + " 1 \n")
m_text.close() if __name__ == '__main__':
generate_classes_text()
生成的文件为:

第一列为图片编号,对应JPEGImages目录下的图片;第二列为1,表示存在行人数据。
这一份txt拷贝成两份,改名为pedestrian_train.txt和pedestrian_val.txt,放在./pedestrian_data/VOC2012/ImageSets/Main目录下。如果下一步生成record中报错,说缺少文件aeroplane_train.txt可以把这两个文件名中的pedestrian改成aeroplane。(理论上应该不会错,但我的时候就给我报错!)
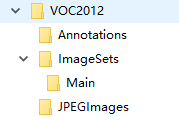
这样Pasacal VOC2012数据格式就准备完成了,目录结构是这样的:
生成 TF record
生成label_map.pbtxt文件,在txt中直接输入如下内容,并把后缀改成pbtxt即可。然后把label_map.pbtxt放在目录./Pedestrian_Detection/project/pedestrian_train/data下。
item {
id: 1
name: 'pedestrian'
}
在命令行窗口下的(dl) D:\Study\dl\Pedestrian_Detection\models\research>执行:
python object_detection/dataset_tools/create_pascal_tf_record.py --label_map_path=D:\Study\dl\Pedestrian_Detection\project\pedestrian_train\data\label_map.pbtxt --data_dir=D:\Study\dl\Pedestrian_Detection\pedestrian_data --year=VOC2012 --set=train --output_path=D:\Study\dl\Pedestrian_Detection\pascal_train.record
和
python object_detection/dataset_tools/create_pascal_tf_record.py --label_map_path=D:\Study\dl\Pedestrian_Detection\project\pedestrian_train\data\label_map.pbtxt --data_dir=D:\Study\dl\Pedestrian_Detection\pedestrian_data --year=VOC2012 --set=val --output_path=D:\Study\dl\Pedestrian_Detection\pascal_val.record
生成两份record文件。pascal_train.record和pascal_val.record
然后把这两份文件copy到目录:/Pedestrian_Detection/project/pedestrian_train/data下。这两个文件大小都为574M,千万要检查,不要把生成失败的record文件放入目录中。(这个错在后面训练的时候搞了我一下午!!!)
数据集准备完毕,record也准备完毕,下一篇将进行模型训练。
【Demo 1】基于object_detection API的行人检测 2:数据制作的更多相关文章
- 【Demo 1】基于object_detection API的行人检测 1:环境与依赖
环境 系统环境: win10.python3.6.tensorflow1.14.0.OpenCV3.8 IDE: Pycharm 2019.1.3.JupyterNotebook 依赖 安装objec ...
- 【Demo 1】基于object_detection API的行人检测 3:模型训练并在OpenCV调用模型
训练准备 模型选择 选择ssd_mobilenet_v2_coco模型,下载地址(https://github.com/tensorflow/models/blob/master/research/o ...
- OpenCV中基于HOG特征的行人检测
目前基于机器学习方法的行人检测的主流特征描述子之一是HOG(Histogram of Oriented Gradient, 方向梯度直方图).HOG特征是用于目标检测的特征描述子,它通过计算和统计图像 ...
- opencv+树莓PI的基于HOG特征的行人检测
树莓PI远程控制摄像头请参考前文:http://www.cnblogs.com/yuliyang/p/3561209.html 参考:http://answers.opencv.org/questio ...
- paper 87:行人检测资源(下)代码数据【转载,以后使用】
这是行人检测相关资源的第二部分:源码和数据集.考虑到实际应用的实时性要求,源码主要是C/C++的.源码和数据集的网址,经过测试都可访问,并注明了这些网址最后更新的日期,供学习和研究进行参考.(欢迎补充 ...
- 行人检测(Pedestrian Detection)资源
一.论文 综述类的文章 [1]P.Dollar, C. Wojek,B. Schiele, et al. Pedestrian detection: an evaluation of the stat ...
- 目标检测之行人检测(Pedestrian Detection)---行人检测之简介0
一.论文 综述类的文章 [1]P.Dollar, C. Wojek,B. Schiele, et al. Pedestrian detection: an evaluation of the stat ...
- 【计算机视觉】行人检测(Pedestrian Detection)资源
一.论文 综述类的文章 [1]P.Dollar, C. Wojek,B. Schiele, et al. Pedestrian detection: an evaluation of the stat ...
- 基于图形检测API(shape detection API)的人脸检测
原文:https://paul.kinlan.me/face-detection/ 在 Google 开发者峰会中,谷歌成员 Miguel Casas-Sanchez 跟我说:"嘿 Paul ...
随机推荐
- 如何调整cookie的生命周期
一.什么是cookie 形象比喻成“网络身份证” 指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密). (1)记录信息的盒子(2)识别每一个网络用户的证件 ...
- sails连接monogodb数据库
1.全局安装:cnpm install -g sails 2.命令窗口进入项目位置 新建项目:sails new sails_cqwu --fast,选择2(快速建立sails项目) 3.cd进入sa ...
- [代码修订版] Python 踩坑之旅进程篇其五打不开的文件
目录 1.1 踩坑案例 1.2 填坑和分析 1.2.1 从程序优化入手 1.2.2 从资源软硬限入手 1.4.1 技术关键字 下期坑位预告 代码示例支持 平台: Centos 6.3 Python: ...
- 干货!Git 如何使用多个托管平台管理代码
考虑到github不能免费创建私有仓库原因,最近开始在使用码云托管项目,这样避免了连接数据库的用户密码等信息直接暴露在公共仓库中.今天突然想到一个点,就是能不能同时把代码推送到github和码云上呢? ...
- Hadoop 学习之路(二)—— 集群资源管理器 YARN
一.hadoop yarn 简介 Apache YARN (Yet Another Resource Negotiator) 是hadoop 2.0 引入的集群资源管理系统.用户可以将各种服务框架部署 ...
- 从零开始实现ASP.NET Core MVC的插件式开发(一) - 使用ApplicationPart动态加载控制器和视图
标题:从零开始实现ASP.NET Core MVC的插件式开发(一) - 使用Application Part动态加载控制器和视图 作者:Lamond Lu 地址:http://www.cnblogs ...
- 跟我学SpringCloud | 第七篇:Spring Cloud Config 配置中心高可用和refresh
SpringCloud系列教程 | 第七篇:Spring Cloud Config 配置中心高可用和refresh Springboot: 2.1.6.RELEASE SpringCloud: Gre ...
- V语言横空出世,C/C++/Java/Python/Go地位不保
V语言已在github正式开源,目前已收获近9000星,引发开发者的强烈关注. V语言到底是怎样一门语言?已经有了C/C++/Java/Python/Go..., 我们还需要另外一门语言吗? 先看看V ...
- 在Winform开发框架中使用DevExpress的TreeList和TreeListLookupEdit控件
DevExpress提供的树形列表控件TreeList和树形下拉列表控件TreeListLookupEdit都是非常强大的一个控件,它和我们传统Winform的TreeView控件使用上有所不同,我一 ...
- Linux使用httpd配置反代理
Linux安装httpd请看上一篇:https://www.cnblogs.com/tuituji27/p/11189095.html 首先,httpd默认监听端口号是80,增加或修改代理的端口号的文 ...