Docker下kafka学习三部曲之二:本地环境搭建
在上一章《 Docker下kafka学习,三部曲之一:极速体验kafka》中我们快速体验了kafka的消息分发和订阅功能,但是对环境搭建的印象仅仅是执行了几个命令和脚本,本章我们通过实战来学习如何编写这些脚本,搭建本地kafka环境;
本次实践会制作docker镜像,所用的材料请在此获取:https://github.com/zq2599/docker_kafka
整个环境涉及到多个容器,我们先把它们全部列出来,再梳理一下之间的关系,如下图:
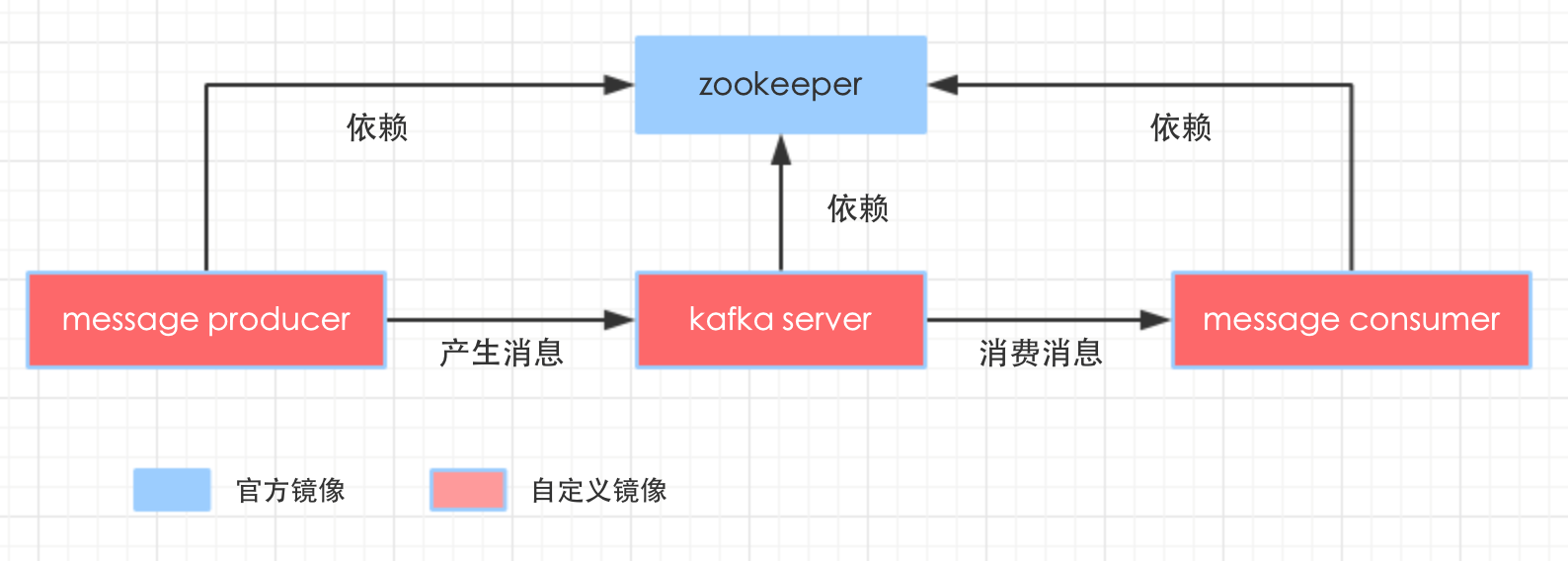
kafka sever提供消息服务;
message producer的作用是产生执行主题的消息;
message consumer的作用是订阅指定主题的消息并消费掉。
zookeeper###
zookeeper使用单机版,没什么需要定制的,因此直接使用官方镜像即可,daocloud.io/library/zookeeper:3.3.6
kafka sever###
去hub.docker.com上搜索kafka,没看到官方标志的镜像,还是自己做一个吧,写Dockerfile之前先准备两个材料:kafka安装包和启动kafka的shell脚本;
kafka安装包用的是2.9.2-0.8.1版本,在
git@github.com:zq2599/docker_kafka.git中,请clone获取;
启动kafka server的shell脚本内容如下,很简单,在kafka的bin目录下执行脚本启动server即可:
#!/bin/bash
$WORK_PATH/$KAFKA_PACKAGE_NAME/bin/kafka-server-start.sh $WORK_PATH/$KAFKA_PACKAGE_NAME/config/server.properties
接下来可以编写Dockerfile了,如下:
# Docker image of kafka
# VERSION 0.0.1
# Author: bolingcavalry
#基础镜像使用tomcat,这样可以免于设置java环境
FROM daocloud.io/library/tomcat:7.0.77-jre8
#作者
MAINTAINER BolingCavalry <zq2599@gmail.com>
#定义工作目录
ENV WORK_PATH /usr/local/work
#定义kafka文件夹名称
ENV KAFKA_PACKAGE_NAME kafka_2.9.2-0.8.1
#创建工作目录
RUN mkdir -p $WORK_PATH
#把启动server的shell复制到工作目录
COPY ./start_server.sh $WORK_PATH/
#把kafka压缩文件复制到工作目录
COPY ./$KAFKA_PACKAGE_NAME.tgz $WORK_PATH/
#解压缩
RUN tar -xvf $WORK_PATH/$KAFKA_PACKAGE_NAME.tgz -C $WORK_PATH/
#删除压缩文件
RUN rm $WORK_PATH/$KAFKA_PACKAGE_NAME.tgz
#执行sed命令修改文件,将连接zk的ip改为link参数对应的zookeeper容器的别名
RUN sed -i 's/zookeeper.connect=localhost:2181/zookeeper.connect=zkhost:2181/g' $WORK_PATH/$KAFKA_PACKAGE_NAME/config/server.properties
#给shell赋予执行权限
RUN chmod a+x $WORK_PATH/start_server.sh
如脚本所示,操作并不复杂,复制解压kafka安装包,启动shell脚本,再把配置文件中zookeeper的ip改成link时zookeeper的别名;
Dockerfile编写完成后,和kafka_2.9.2-0.8.1.tgz以及start_server.sh放在同一个目录下,用控制台在此目录下执行:
docker build -t bolingcavalry/kafka:0.0.1 .
镜像构建成功后,新建一个目录编写docker-compose.yml脚本,如下:
version: '2'
services:
zk_server:
image: daocloud.io/library/zookeeper:3.3.6
restart: always
kafka_server:
image: bolingcavalry/kafka:0.0.1
links:
- zk_server:zkhost
command: /bin/sh -c '/usr/local/work/start_server.sh'
restart: always
message_producer:
image: bolingcavalry/kafka:0.0.1
links:
- zk_server:zkhost
- kafka_server:kafkahost
restart: always
message_consumer:
image: bolingcavalry/kafka:0.0.1
links:
- zk_server:zkhost
restart: always
docker-compose.yml中配置了四个容器:
- zookeeper是官方的;
- 其他三个都是用刚刚制作的bolingcavalry/kafka做镜像生成的;
- kafka_server在启动时执行了start_server.sh脚本把服务启动起来了;
- message_producer和message_consumer都仅仅是将kafka环境安装好了,以便于通过命令行发送或者订阅消息,但是这两个容器本身并未启动server;
- kafka_server,message_producer,message_consumer都通过link参数连接到了zookeeper容器,并且message_producer还连接到了kafka server,因为发送消息的时候会用到kafka server的ip地址;
现在打开终端,在docker-compose.yml所在目录下执行docker-compose up -d,即可启动所有容器;
至此,本地环境搭建已经成功了,我们可以通过命令行体验kafka的消息发布订阅服务,具体的命令可以参考上一章《 Docker下kafka学习,三部曲之一:极速体验kafka》。
以上就是本地搭建kafka的全过程,下一章我们开发java应用来体验kafka的消息发布订阅服务。
欢迎关注我的公众号:程序员欣宸
Docker下kafka学习三部曲之二:本地环境搭建的更多相关文章
- Docker下kafka学习三部曲之一:极速体验kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,从本章开始我们先极速体验,再实战docker下搭建kafka环境,最后开发一个java web应用来体验kafka服务. 我们一起用最快的速度体验ka ...
- Docker下实战zabbix三部曲之二:监控其他机器
在上一章<Docker下实战zabbix三部曲之一:极速体验>中,我们快速安装了zabbix server,并登录管理页面查看了zabbix server所在机器的监控信息,但是在实际场景 ...
- struts2学习笔记之二:基本环境搭建
学习struts2有一段时间了,作为一个运维人员学习的时间还是挺紧张的,写这篇文件为了方便以后复习时使用 环境: MyEclipse 10 tomcat6 jdk1.6 首先建立一个web项目,并 ...
- 大数据学习系列之二 ----- HBase环境搭建(单机)
引言 在上一篇中搭建了Hadoop的单机环境,这一篇则搭建HBase的单机环境 环境准备 1,服务器选择 阿里云服务器:入门型(按量付费) 操作系统:linux CentOS 6.8 Cpu:1核 内 ...
- hibernate学习笔记之二 基本环境搭建
1.创建一个普通的java项目 2.加入Hibernate所有的jar包 3.建立包名com.bjpowernode.hibernate 4.建立实体类User.java package com.bj ...
- Docker下实战zabbix三部曲之一:极速体验
对于想学习和实践zabbix的读者来说,在真实环境搭建一套zabbix系统是件费时费力的事情,本文内容就是用docker来缩减搭建时间,目标是让读者们尽快投入zabbix系统的体验和实践: 环境信息 ...
- Docker下实战zabbix三部曲之三:自定义监控项
通过上一章<Docker下实战zabbix三部曲之二:监控其他机器>的实战,我们了解了对机器的监控是通过在机器上安装zabbix agent来完成的,zabbix agent连接上zabb ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- Docker下dubbo开发三部曲之三:java开发
在前两章<Docker下dubbo开发,三部曲之一:极速体验>和<Docker下dubbo开发,三部曲之二:本地环境搭建>中,我们体验了dubbo环境搭建以及服务的发布和消费, ...
随机推荐
- iText实现pdf导出
/** * AsianTest.java */ import java.io.FileOutputStream; import java.io.IOException; import com.lowa ...
- NLP(十五)让模型来告诉你文本中的时间
背景介绍 在文章NLP入门(十一)从文本中提取时间 中,笔者演示了如何利用分词.词性标注的方法从文本中获取时间.当时的想法比较简单快捷,只是利用了词性标注这个功能而已,因此,在某些地方,时间的识别 ...
- 在Linux和Windows系统中输出目录结构
前言 一直以来就想在写文章时,能以文本形式(而不是截图)附上项目的目录结构,今天终于知道怎么操作了,在这分享一下. Linux 首先说下Linux上输出目录结构的方法. yum安装tree 需要支持t ...
- java学习笔记(中级篇)—JDK动态代理
一.什么是代理模式 相信大家都知道代理商这个概念,在商业中,代理商无处不在.假设你要去买东西,你不可能去找真正的厂家去买,也不可能直接跟厂家提出需求,代理商就是这中间的一桥梁,连接买家和厂商.你要买或 ...
- 阿里云短信服务(JAVA)
一,前言 短信验证码想必大家都不陌生,在很多网站,APP中都有使用到.比如登录,注册,身份校验等场景.不过通常情况下,短信服务都是外包给第三方公司的,接下来向大家分享如何使用阿里的短信服务. 二, ...
- 后端开发之chrome开发者模式
1. 场景描述 java开发前后端分离模式越来越流行,后端人员可以直接使用swagger进行接口调试(前后端分离之Swagger2),但是调试的时候,需要设置入参,假如该模块不是软件老王开发的,接别人 ...
- js-EventLoop
1.浏览器事件环 eventLoop是由js的宿主环境(浏览器)来实现的 事件循环可以简单的描述为以下四个步骤 1.函数入栈,当Stack中执行到异步任务的时候,就将他丢给WebAPIs,接着执行同步 ...
- Mybatis 中的<![CDATA[ ]]>浅析
在使用mybatis 时我们sql是写在xml 映射文件中,如果写的sql中有一些特殊的字符的话,在解析xml文件的时候会被转义,但我们不希望他被转义,所以我们要使用<![CDATA[ ]]&g ...
- unity编辑器扩展_04(使用Selection获取选择的游戏物体)
代码: [MenuItem("Tools/GetChance", false, 1)] static void GetChance() { if (Sel ...
- 使用Eclipse开发动态Javaweb项目
使用Eclipse开发动态Javaweb项目 一.Eclipse的使用 1. 把开发选项切换到 JavaEE 2. 可以在 Window -> Show View 中找到 Package Exp ...