NIO零拷贝的深入分析
深入分析通过Socket进行数据文件传递中的传统IO的弊端以及NIO的零拷贝实现原理,及用户空间和内核空间的切换方式
传统的IO流程
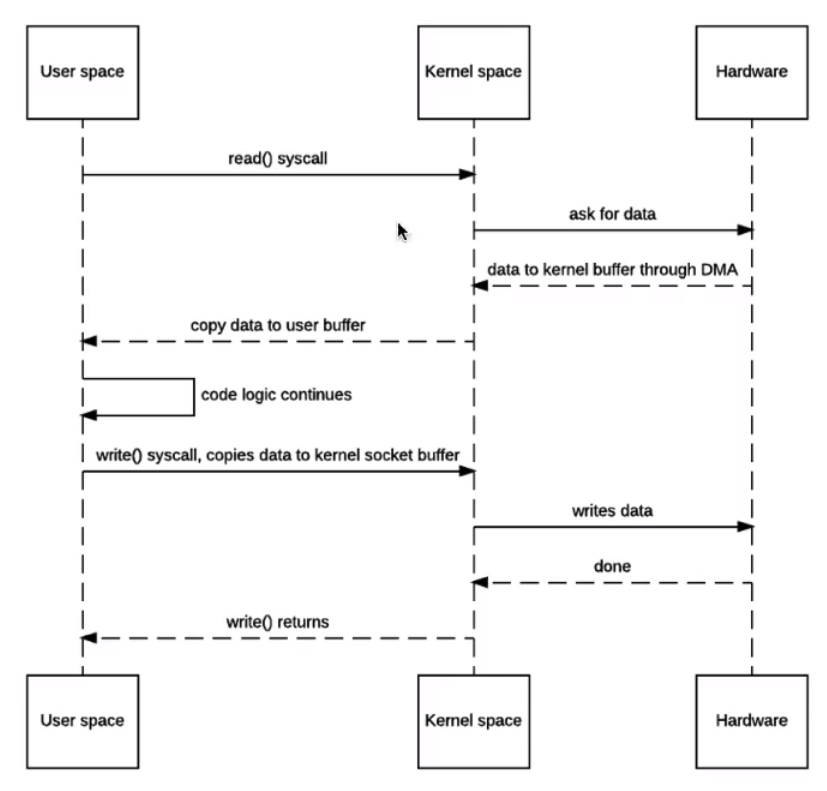
在这个过程中:
- 数据从磁盘拷贝进内核空间缓冲区
- 从内核空间缓冲区拷贝到用户空间缓冲区
- 从用户空间缓冲区拷贝回内核空间缓冲区
- 在从内核空间缓冲区拷贝到socket的缓冲区
- 由Socket缓存区传递给数据发送引擎发送
第三步的必要性:
IO操作涉及到本地方法,java担心,当使用native本地方法对堆内数组进行操作时发生GC, 因为堆内内存是受JVM影响的,一旦发生了垃圾回收机制就使得全部数据都是错乱的,而堆外内存是不受JVM控制的.
就这样, 前前后后一共发生了4次数据的拷贝,用户空间模式和内核空间模式来回切换了4次, 其中用户空间参与的第二次和第三次拷贝并没有对数据进行任何改动,它仅仅是起到了中转的作用; 这恰恰是传统的IO的局限性
NIO的零拷贝
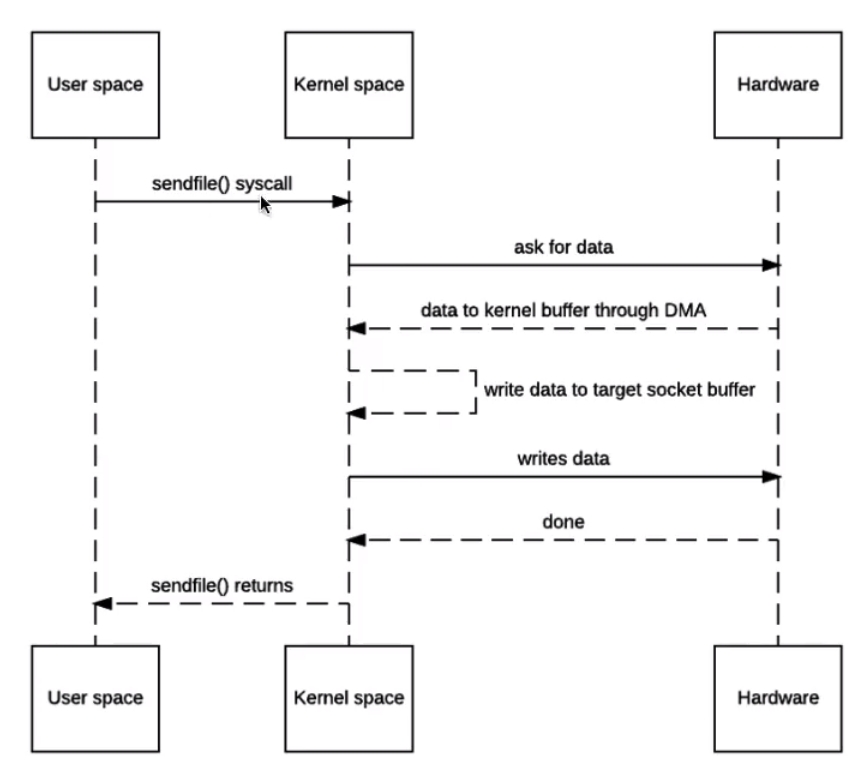
在NIO的数据传递模型中可以看到,用户明显少了用户空间缓冲区缓存数据的步骤, 减少了两次不必要的数据的拷贝,以及不必要的上下文切换, 具体如下:
- 数据从磁盘写入内核空间缓冲区
- 再从内核空间缓冲区写入到Socket缓冲区
- 由Socket缓存区传递给数据发送引擎发送
然而这个模型中仍然有问题存在,在内核空间缓冲区中仍然存在数据的拷贝
- 数据从内核空间缓冲区拷贝进了Socket缓冲区
这种现状也是有办法解决的
在2.X版本的linux中,NIO的零拷贝模型如下:
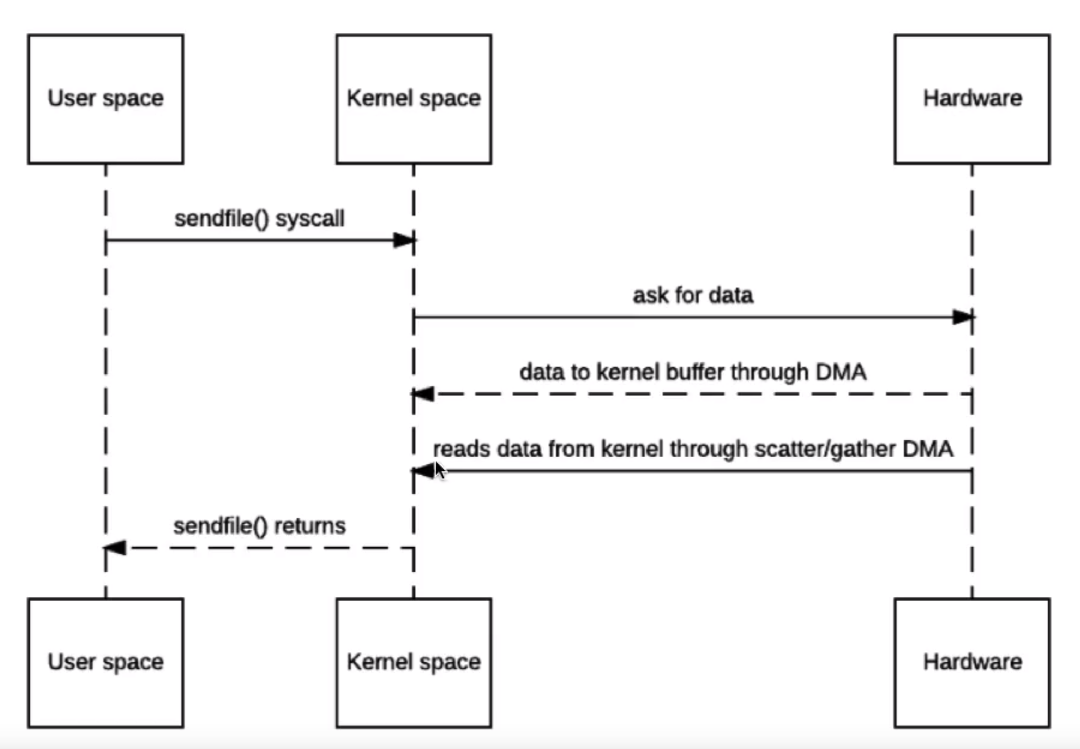
这个模型中充分利用了Scatter/Gather 分散和汇聚的特性
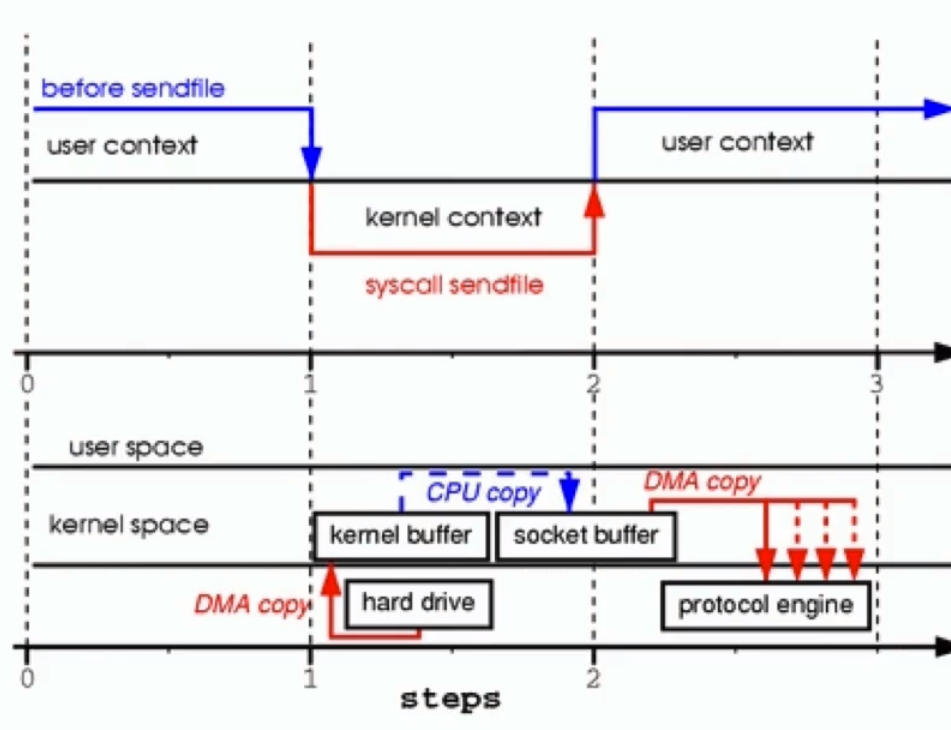
这张图是最完美的零拷贝模型,
- 首先文件从磁盘中加载进内核空间缓冲区
- CPU将内核空间缓冲区存储的数据的adress以及数据的大小存放进Socket
- 协议引擎根据socket提供的数据的描述,直接去内核缓冲区取出数据
第2步 一个完整的可用的buffer被分散在两个buffer中, 可以理解成是一个分散的过程 Scatter
第3步 操作系统去收集buffer,可以理解成一个Gather的过程
从而实现了真正的零拷贝
回到Java
除了上面的第一张图片以外,其他图片中数据全部在内核缓冲区,这部分空间对于人来说其实是一个黑盒,于是java提供了封装类帮我们和这块黑盒打交道
mappedByteBuffer
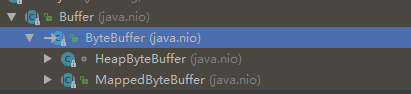
这是他的继承体系,和HeadByteBuffer位于同一级,我们称它为内存映射文件 他是通道的调用map()方法得来的, 这个mappedByteBuffer相对于普通的buffer而言,他并没有板板整整的维护自己的数组,相反直接关联着堆外内存,针对它的任何修改,操作系统都会自动的同步到文件中
如下修改内存buffer,却更新了文件
RandomAccessFile randomAccessFile = new RandomAccessFile("123.txt", "rw"); //class sun.nio.ch.FileChannelImpl
FileChannel channel = randomAccessFile.getChannel();
System.out.println(channel.getClass());
MappedByteBuffer mappedByteBuffer = channel.map(FileChannel.MapMode.READ_WRITE, 0, 5);
// todo 接下来我们直接修改内存中的内容就行了,不需要修改文件
mappedByteBuffer.put(0, (byte) 'a');
mappedByteBuffer.put(3, (byte) 'b');
randomAccessFile.close();
channel.close();
关于FileChannel.MapMode文件通道的映射模型 是个枚举:
- PRIVATE
- READ_WRITE
- READ_ONLY
当我们想构建read_write类型的只能使用 RandomAccessFile类型的文件stream, 通过它的rw参数,设置为可读写的类型
关于ByteBuffer的ByteBuffer.allocateDirect()
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
class DirectByteBuffer extends MappedByteBuffer implements DirectBuffer
{
...
}
最常用的ByteBuffer的allocateDirect()底层使用同样是MappedBytebuffer的实现类,DirectByteBuffer,这个对象相对于HeapByteBuffer来说,他并没有初始化父类ByteBuffer中的数组,但是它使用了超类BUffer中的Long类型的adress关键字
adress关键字的作用是 存放了一个堆外的地址,这个地址标记着一个堆外数组的位置,使得java可以使用unsafe类下的本地方法,操作adress标记的堆外内存,这样就省去了在第一张图片中的还要把堆内数组拷贝到堆外再进行读写的弊端,实现了零拷贝
scattering 和 gathering在NIO编程中的体现
scattering是一个分散的过程,即把一整块数据分散在不同的buffer中,而gathering与之相反,是一个聚集的过程,只有搜集全所有的全部的buffer得到的数据才是有意义的
例子: 自定义网络协议 将请求头分装成多个缓存buffer中,实现了天然的解析
ByteBuffer[] byteBuffers = new ByteBuffer[3];
byteBuffers[0] = ByteBuffer.allocate(2);
byteBuffers[1] = ByteBuffer.allocate(3);
byteBuffers[2] = ByteBuffer.allocate(4);
SocketChannel client = serverSocketChannel.accept();
long read = client.read(byteBuffers);
NIO零拷贝的深入分析的更多相关文章
- NIO学习笔记,从Linux IO演化模型到Netty—— Java NIO零拷贝
同样只是大致上的认识. 其中,当使用transferFrom,transferTo的时候用的sendfile(). 如果系统内核不支持 sendfile,进一步执行 transferToTrusted ...
- Java零拷贝
1.摘要 零拷贝的“零”是指用户态和内核态间copy数据的次数为零. 传统的数据copy(文件到文件.client到server等)涉及到四次用户态内核态切换.四次copy.四次copy中,两次在用户 ...
- 深入剖析Linux IO原理和几种零拷贝机制的实现
深入剖析Linux IO原理和几种零拷贝机制的实现 来源 https://zhuanlan.zhihu.com/p/83398714 零壹技术栈 公众号[零壹技术栈] 前言 零拷贝(Zero ...
- 【Netty技术专题】「原理分析系列」Netty强大特性之ByteBuf零拷贝技术原理分析
零拷贝Zero-Copy 我们先来看下它的定义: "Zero-copy" describes computer operations in which the CPU does n ...
- Netty 零拷贝(一)NIO 对零拷贝的支持
Netty 零拷贝(二)NIO 对零拷贝的支持 Netty 系列目录 (https://www.cnblogs.com/binarylei/p/10117436.html) 非直接缓冲区(HeapBy ...
- 零拷贝详解 Java NIO学习笔记四(零拷贝详解)
转 https://blog.csdn.net/u013096088/article/details/79122671 Java NIO学习笔记四(零拷贝详解) 2018年01月21日 20:20:5 ...
- NIO学习笔记,从Linux IO演化模型到Netty—— Linux零拷贝
这里只是感性地认识Linux零拷贝,不涉及具体细节. 1.Linux传统的数据拷贝 用户进程是不能直接访问文件系统的,要先切换到内核态,发起系统调用,DMA把磁盘中的数据写入内核空间,内核再把数据拷贝 ...
- NIO 与 零拷贝
零拷贝介绍 零拷贝是网络编程的关键, 很多性能优化都需要零拷贝. 在 Java程序中, 常用的零拷贝方式有m(memory)map[内存映射] 和 sendFile.它们在OS中又是怎样的设计? NI ...
- Linux、JDK、Netty中的NIO与零拷贝
一.先理解内核空间与用户空间 Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中, CPU 特权等级分为4个,Linux 使用 Ring 0 和 Ring 3. 内核空 ...
随机推荐
- 《Java数据结构》树形结构
树形结构是一层次的嵌套结构. 一个树形结构的外层和内层有相似的结构, 所以这种结构多可以递归的表示.经典数据结构中的各种树形图是一种典型的树形结构:一颗树可以简单的表示为根, 左子树, 右子树. 左子 ...
- IPFS学习-IPNS
星际名称系统(IPNS)是一个创建个更新可变的链接到IPFS内容的系统,由于对象在IPFS中是内容寻址的,他们的内容变化将导致地址随之变化.对于多变的事物是有用的.但是很难获取某些内容的最新版本. 在 ...
- Winform中使用Timer实现滚动字幕效果(附代码下载)
场景 效果 注: 博客主页: https://blog.csdn.net/badao_liumang_qizhi 关注公众号 霸道的程序猿 获取编程相关电子书.教程推送与免费下载. 实现 新建一个Fo ...
- wx-一个简单页面
一个具有顶部,底部和中间的html页面,但没有js <view class="root"> <!-- 标签栏的页签 固定高度 --> <view cl ...
- 利用ExecuteMultipleRequest来批量导入数据,成功的成功失败的失败,并生成导入结果文件
我是微软Dynamics 365 & Power Platform方面的工程师罗勇,也是2015年7月到2018年6月连续三年Dynamics CRM/Business Solutions方面 ...
- 从微信小程序开发者工具源码看实现原理(三)- - 双线程通信
文章概览: 引言 小程序开发者工具双线程通信的设计 1.on: 用来收集小程序开发者工具触发的事件回调 2.invoke:以api方式调用开发工具提供的基础能力 3.publish:用来向Appser ...
- IM即时通信软件设计
参考资料: 架构篇:https://yq.aliyun.com/articles/698301 模型篇:https://yq.aliyun.com/articles/701593 实现篇:https: ...
- JCC 指令
JCC跳转指令 JCC指条件跳转指令,CC就是指条件码. JCC指令 中文含义 英文原意 检查符号位 典型C应用 JZ/JE 若为0则跳转:若相等则跳转 jump if zero;jump if eq ...
- Context知识详解
Context知识详解 建议配合context知识架构图食用. 一.什么是Context 贴一个官方解释: Interface to global information about an appli ...
- wireshark抓包如何查看视频分辨率和码率
本文简单介绍如何查看Wireshark抓取pcap包,其视频码流的分辨率和码率. 查看分辨率 我们打开一个抓取的pcap文件,找到标记为SPS(Sequence Parameter Set)的数据包. ...