Hadoop 学习之路(四)—— Hadoop单机伪集群环境搭建
一、前置条件
Hadoop的运行依赖JDK,需要预先安装,安装步骤见:
二、配置免密登录
Hadoop组件之间需要基于SSH进行通讯。
2.1 配置映射
配置ip地址和主机名映射:
vim /etc/hosts
# 文件末尾增加
192.168.43.202 hadoop001
2.2 生成公私钥
执行下面命令行生成公匙和私匙:
ssh-keygen -t rsa
3.3 授权
进入~/.ssh目录下,查看生成的公匙和私匙,并将公匙写入到授权文件:
[root@@hadoop001 sbin]# cd ~/.ssh
[root@@hadoop001 .ssh]# ll
-rw-------. 1 root root 1675 3月 15 09:48 id_rsa
-rw-r--r--. 1 root root 388 3月 15 09:48 id_rsa.pub
# 写入公匙到授权文件
[root@hadoop001 .ssh]# cat id_rsa.pub >> authorized_keys
[root@hadoop001 .ssh]# chmod 600 authorized_keys
三、Hadoop(HDFS)环境搭建
3.1 下载并解压
下载Hadoop安装包,这里我下载的是CDH版本的,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
# 解压
tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz
3.2 配置环境变量
# vi /etc/profile
配置环境变量:
export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
export PATH=${HADOOP_HOME}/bin:$PATH
执行source命令,使得配置的环境变量立即生效:
# source /etc/profile
3.3 修改Hadoop配置
进入${HADOOP_HOME}/etc/hadoop/目录下,修改以下配置:
1. hadoop-env.sh
# JDK安装路径
export JAVA_HOME=/usr/java/jdk1.8.0_201/
2. core-site.xml
<configuration>
<property>
<!--指定namenode的hdfs协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<!--指定hadoop存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
3. hdfs-site.xml
指定副本系数和临时文件存储位置:
<configuration>
<property>
<!--由于我们这里搭建是单机版本,所以指定dfs的副本系数为1-->
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4. slaves
配置所有从属节点的主机名或IP地址,由于是单机版本,所以指定本机即可:
hadoop001
3.4 关闭防火墙
不关闭防火墙可能导致无法访问Hadoop的Web UI界面:
# 查看防火墙状态
sudo firewall-cmd --state
# 关闭防火墙:
sudo systemctl stop firewalld.service
3.5 初始化
第一次启动Hadoop时需要进行初始化,进入${HADOOP_HOME}/bin/目录下,执行以下命令:
[root@hadoop001 bin]# ./hdfs namenode -format
3.6 启动HDFS
进入${HADOOP_HOME}/sbin/目录下,启动HDFS:
[root@hadoop001 sbin]# ./start-dfs.sh
3.7 验证是否启动成功
方式一:执行jps查看NameNode和DataNode服务是否已经启动:
[root@hadoop001 hadoop-2.6.0-cdh5.15.2]# jps
9137 DataNode
9026 NameNode
9390 SecondaryNameNode
方式二:查看Web UI界面,端口为50070:
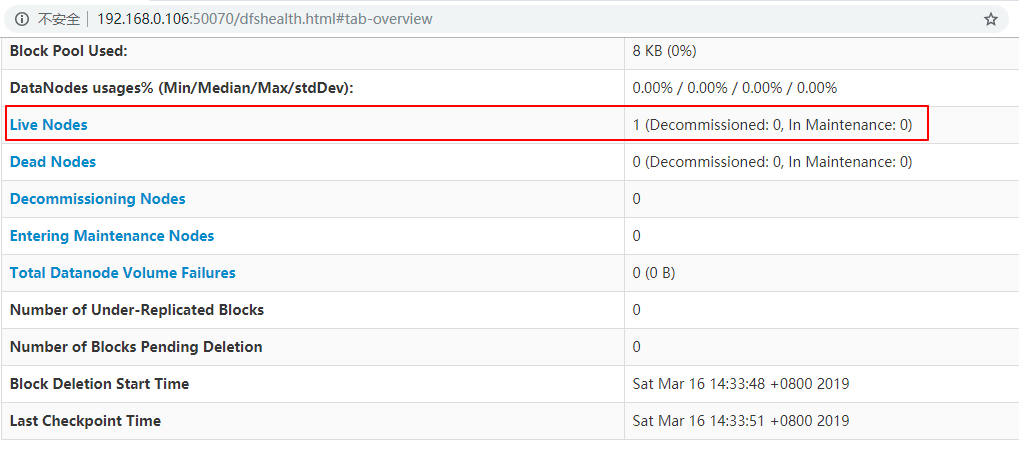
四、Hadoop(YARN)环境搭建
4.1 修改配置
进入${HADOOP_HOME}/etc/hadoop/目录下,修改以下配置:
1. mapred-site.xml
# 如果没有mapred-site.xml,则拷贝一份样例文件后再修改
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2. yarn-site.xml
<configuration>
<property>
<!--配置NodeManager上运行的附属服务。需要配置成mapreduce_shuffle后才可以在Yarn上运行MapReduce程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.2 启动服务
进入${HADOOP_HOME}/sbin/目录下,启动YARN:
./start-yarn.sh
4.3 验证是否启动成功
方式一:执行jps命令查看NodeManager和ResourceManager服务是否已经启动:
[root@hadoop001 hadoop-2.6.0-cdh5.15.2]# jps
9137 DataNode
9026 NameNode
12294 NodeManager
12185 ResourceManager
9390 SecondaryNameNode
方式二:查看Web UI界面,端口号为8088:
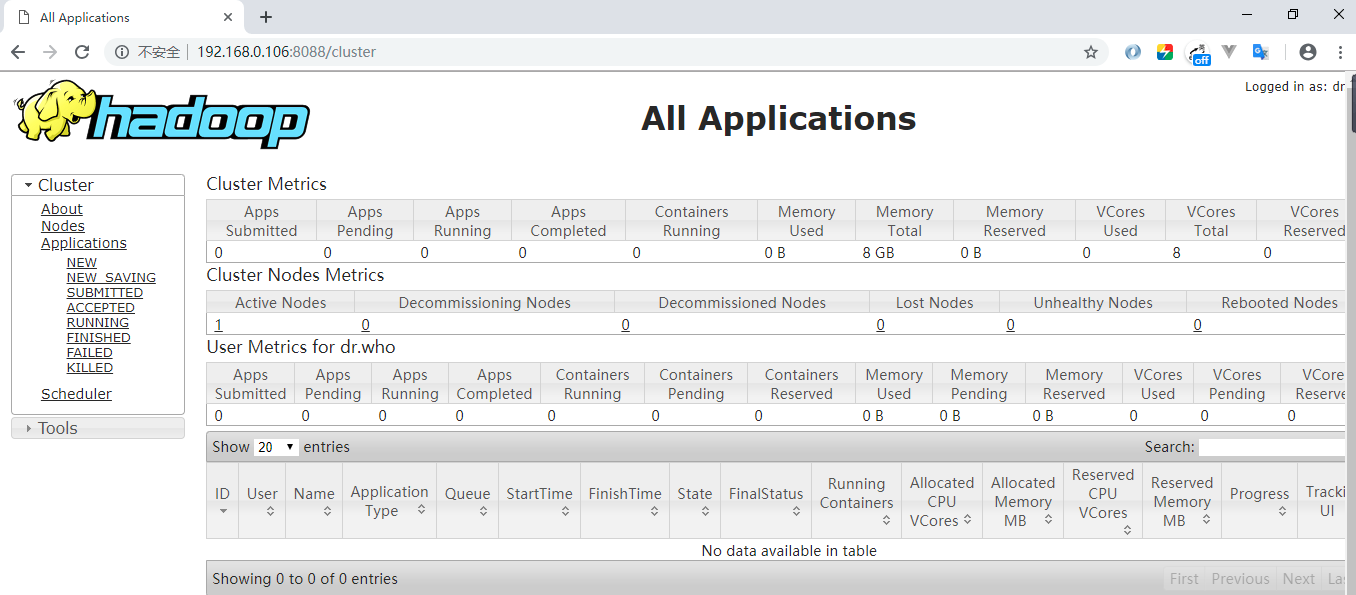
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Hadoop 学习之路(四)—— Hadoop单机伪集群环境搭建的更多相关文章
- Hadoop学习(一):完全分布式集群环境搭建
1. 设置免密登录 (1) 新建普通用户hadoop:useradd hadoop(2) 在主节点master上生成密钥对,执行命令ssh-keygen -t rsa便会在home文件夹下生成 .ss ...
- ZooKeeper伪集群环境搭建
1.从官网下载程序包. 2.解压. [dev@localhost software]$ tar xzvf zookeeper-3.4.6.tar.gz 3.进入zookeeper文件夹后创建data文 ...
- Storm 学习之路(四)—— Storm集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- ZooKeeper学习之路(二)—— Zookeeper单机环境和集群环境搭建
一.单机环境搭建 1.1 下载 下载对应版本Zookeeper,这里我下载的版本3.4.14.官方下载地址:https://archive.apache.org/dist/zookeeper/ # w ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Zookeeper集群搭建(多节点,单机伪集群,Docker集群)
Zookeeper介绍 原理简介 ZooKeeper是一个分布式的.开源的分布式应用程序协调服务.它公开了一组简单的原语,分布式应用程序可以在此基础上实现更高级别的同步.配置维护.组和命名服务.它的设 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- redis在Windows下以后台服务一键搭建集群(单机--伪集群)
redis在Windows下以后台服务一键搭建集群(单机--伪集群) 一.概述 此教程介绍如何在windows系统中同一台机器上布置redis伪集群,同时要以后台服务的模式运行.布置以脚本的形式,一键 ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
随机推荐
- .NET/C# 使窗口永不激活(No Activate 永不获得焦点)
原文 .NET/C# 使窗口永不激活(No Activate 永不获得焦点) 有些窗口天生就是为了辅助其它程序而使用的,典型的如“输入法窗口”.这些窗口不希望抢夺其它窗口的焦点. 有 Win32 方法 ...
- 开始使用Material UI
Material-UI采用 Material Design风格的React UI组件,所以要想学习material ui先要了解react. material ui安装 Material-UI 可以使 ...
- DDD实战8_2 利用Unity依赖注入,实现接口对应实现类的可配置
1.在Util类库下新建DIService类 /// <summary> /// 创建一个类,对应在配置文件中配置的DIServices里面的对象的 key /// </summar ...
- C#中的MessageBox消息对话框
关键字:C# MessageBox 消息对话框 在程序中,我们经常使用消息对话框给用户一定的信息提示,如在操作过程中遇到错误或程序异常,经常会使用这种方式给用于以提示.在C#中,MessageBox消 ...
- WPF 获取 ListView DataTemplate 中控件值
原文:WPF 获取 ListView DataTemplate 中控件值 版权声明:本文为博主原创文章,未经博主允许可以随意转载 https://blog.csdn.net/songqingwei19 ...
- wpf XMAL中隐藏控件
原文:wpf XMAL中隐藏控件 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/a771948524/article/details/9264569 ...
- 从源码角度看MySQL memcached plugin——1. 系统结构和引擎初始化
本章尝试回答两个问题: 一.memcached plugin与MySQL的关系: 二.MySQL系统如何启动memcached plugin. 1. memcached plugin与MySQL的关系 ...
- IAA32过程调用保护规则注册
因为操作系统共享性质,所以,寄存器已成为各种处理或共享资源的处理.然后,该过程发生 当所谓的.假设呼叫者使用内部寄存器值.但这个寄存器的内容,很可能在该呼叫者的执行的过程中改变,用过程执行之前,对该寄 ...
- TCP网络通讯如何解决分包粘包问题(有模拟代码)
TCP作为常用的网络传输协议,数据流解析是网络应用开发人员永远绕不开的一个问题. TCP数据传输是以无边界的数据流传输形式,所谓无边界是指数据发送端发送的字节数,在数据接收端接受时并不一定等于发送的字 ...
- Qt移动应用开发(六):QML与C++互动
Qt移动应用开发(六):QML与C++互动 上一篇文章讲到了在Qt Quick中实现场景切换的一种可能的方法,场景切换是诸如游戏等应用在内必需要面临的技术难点,所以场景切换并没有通行的方法,依据自己的 ...